

Audit Data Analytics dengan R – Mengelola Teks
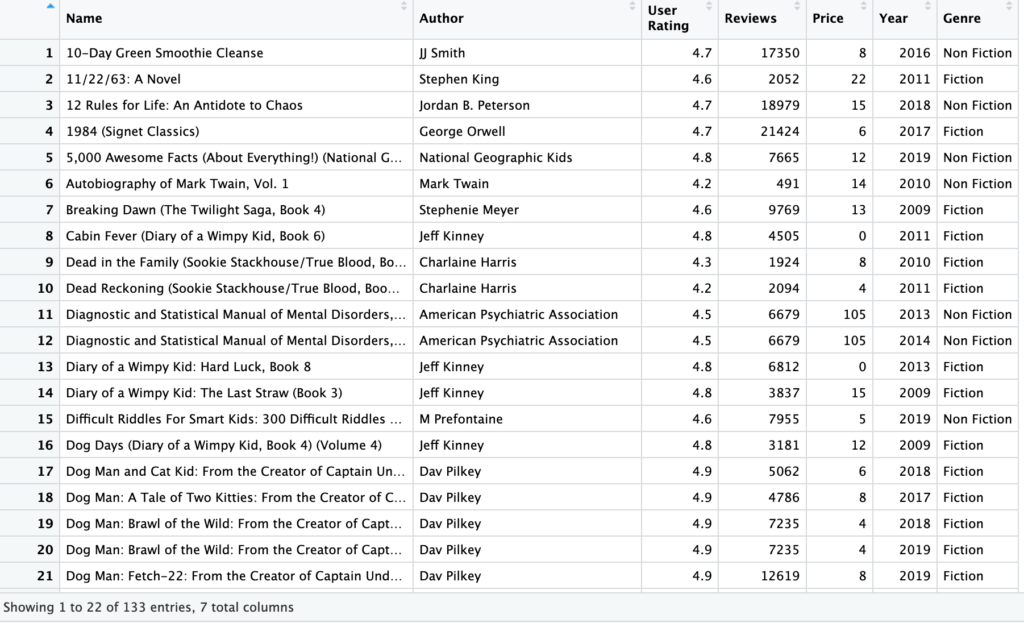
“Chaos was the law of nature, order was the dream of man”, menurut internet pernah dikatakan oleh Henry Adams.
Kode Lima Detik
library(tidyverse)
books <- readxl::read_excel('AmazonBooks.xlsx')
books$AuthorBesar <- str_to_upper(books$Author)
books$AuthorNamaDepan <- sapply(str_split(books$Author, pattern = ' '), head, n=1)
books$AuthorNamaDepan2 <- sapply(str_split(books$Author, pattern = ' '), '[', 1)
books$AuthorNamaKeluarga <- sapply(str_split(books$Author, pattern = ' '), tail, n=1)
books %>%
filter(str_detect(books$Author, regex('a', ignore_case = TRUE)))
books %>%
filter(str_detect(books$Name, '[0-9]+'))
books$namaspasi <- str_replace_all(books$Name, ' ', '_')
Dalam tulisan ini kita akan belajar:
- Load Data dari Excel ke R
- Membuat Kolom Berdasarkan Teks
- Mengidentifikasi Keberadaan Pola Teks Tertentu
- Mengambil Angka dari Teks
- RStudio Project sebagai salah satu best practice
Excel

Sampai tingkatan tertentu kita harus mengakui bahwa MS Excel emang ada dimana-mana. Jika harus jujur, sepertinya data dalam Excel adalah yang paling sering kita temui dalam kehidupan.
Karena itu R (dan teknologi untuk membantu olah data lainnya) memiliki beberapa pilihan library yang dapat digunakan untuk mengelola berkas Excel, diantaranya:
Operasi Sederhana
Sebelum mengolah data dari Excel, kita perlu mencoba beberapa operasi sederhana pada teks.
Oya, library yang akan digunakan adalah stringr, yang merupakan bagian dari tidyverse. Untuk meload library tersebut dapat dengan menggunakan perintah:
library(stringr)
Atau jika akan menggunakan library lain dalam tidyverse, dapat menggunakan perintah di bawah ini agar tak usah mengetik library lain untuk diload.
library(tidyverse)
Misal kita memiliki sebuah teks sederhana di bawah ini.
teks <- 'Halo dunia, ini adalah teks pertama yang diciptakan oleh manusia. Meskipun merupakan fakta sehari-hari bagi manusia kekiniyan namun sebenarnya kegiatan baca tulis adalah pencapaian signifikan dalam peradaban manusia'

Teks BESAR SEMUA
Bagaimana jika ingin membuat semua huruf menjadi kapital? gunakan str_to_upper.
str_to_upper(teks)

Teks Kapital
Oke, sepertinya membuat semua teks menjadi besar bukanlah ide yang baik, bagaimana jika hanya huruf pertama saja yang besar?
str_to_title(teks)

teks kecil
Ingin teks lebih bersahaja? Gimana kalo dikecilin semua hurup?
str_to_title(teks)

Membagi Teks
Memotong sebuah teks menjadi beberapa teks terpisah merupakan kebutuhan standar yang cepat atau lambat akan kita temui. Library stringr menyediakan fungsi str_split untuk mencapainya.
Spasi
str_split(teks, pattern = ' ')

Kode di atas membagi teks berdasarkan spasi sehingga terbentuk daftar kata (dan tanda baca seperti koma dan titik). Jika ingin mengakses salah satu hasilnya lebih mudah jika menambahkan parameter simplify = TRUE.
str_split(teks, pattern = ' ', simplify = TRUE)

Mengakses kata pertama atau kedua atau ketiga atau pertama sampai ketiga, gunakan kode di bawah ini.
str_split(teks, pattern = ' ', simplify = TRUE)[1] str_split(teks, pattern = ' ', simplify = TRUE)[2] str_split(teks, pattern = ' ', simplify = TRUE)[3] str_split(teks, pattern = ' ', simplify = TRUE)[1:3]

Titik
Bagaimana jika ingin membagi teks menggunakan pemisah berupa tanda baca, misal titik?
str_split(teks, pattern = '.')

Hasilnya tak sesuai harapan.
hm, sudah kuduga
Parameter pattern secara default diterjemahkan sebagai regular expression. Sepertinya kita perlu sedikit belajar mengenai konsep itu.
Regular Expression (Regex)
Mengelola teks tak lengkap jika tak menggunakan Regex.
Menurut wiki, Regex adalah urutan karakter yang digunakan untuk pencarian. Karena tersusun dari karakter, sekilas Regex seperti sembarang karakter yang diketik oleh ponsel di dalam saku celana.

Tulisan ini tidak diniatkan untuk memberikan penjelasan mengenai Regex. Sayangnya mengolah teks (string) akan banyak terbantu jika menggunakan Regex, tersebab itu hanya disebutkan beberapa pola yang jamak digunakan.
- . semua karakter kecuali newline (baris baru)
- \w kata (word)
- \d digit,
- \s spasi
- \W bukan kata (huruf w kapital)
- \D bukan digit
- \S bukan spasi
- [a-g] karakter antara a dan g
- ^ awal teks
- $ akhir teks
Untuk pola lebih lengkap, atau kondisi lebih rumit, silahkan bertanya pada banyak bahan belajar mengenai Regex di internet. Bahkan untuk melakukan pengujian Regex secara online pun telah tersedia.
Ooo.. Sebab itu kode str_split(teks, pattern = ‘.’) tidak memunculkan hasil yang diinginkan, karena titik diterjemahkan menjadi semua karakter. Lantas bagaimana untuk memisahkan teks menggunakan titik?
Tambahkan \\ di depan titik.
str_split(teks, pattern = '\\.')

Kalimat
Omong-omong mumpung terlanjur membahas regex, berikut regex yang dapat digunakan untuk membagi teks per kalimat. Di bawah ini kita membuat teks baru yang sedikit lebih kompleks dari teks sebelumnya. Kemudian menggunakan regex kita memisahkan masing-masing kalimat.
teks2 <- 'Ini adalah kalimat pertama! Ini, adalah kalimat kedua. Dan (diksi yang kurang tepat untuk pembuka kalimat) adalah kalimat terakhir.' str_split(teks2, pattern = '(?<=[[:punct:]])\\s(?=[A-Z])')

Membuka Excel
Sekarang saatnya mengolah banyak teks, dari berkas Excel.
Karena file Excel ada dimana-mana, kita tidak akan kesulitan mendapatkannya. Kali ini kita akan menggunakan data 50 novel terlaris di Amazon pada periode tahun 2009 hingga 2020 yang dapat diunduh di sini.

Untuk membuka berkas bernama AmazonBooks.xlsx ini akan digunakan library readxl dari tidyverse, jadi jika sebelumnya kita telah meload library tidyverse kode di bawah ini dapat langsung digunakan.
books <- readxl::read_excel('AmazonBooks.xlsx')
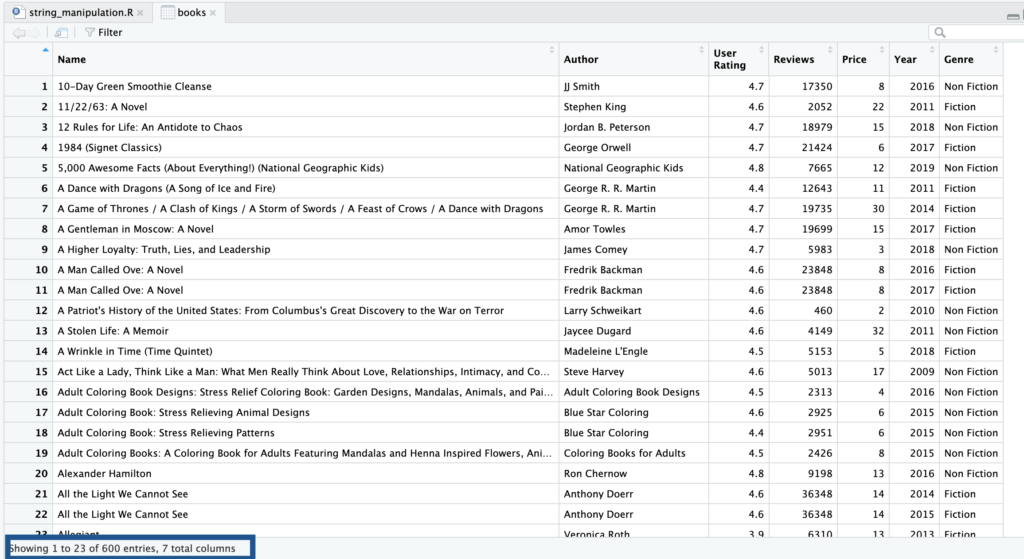
Seperti terlihat pada bagian bawah tabel, data ini berisi 600 baris dengan 7 kolom. Dan membuka berkas Excel di R sangat mudah.
Operasi Sederhana pada Data Baru
Seringnya kita membuat sebuah kolom baru berisi hasil olahan data dari kolom lain. Di bawah ini kita akan membuat beberapa kolom yang merujuk pada kolom Author. Metode yang digunakan sama seperti sebelumnya, bedanya keluaran dari proses tersebut akan ditampung di dalam kolom baru.
Teks BESAR SEMUA
Membuat kolom bernama AuthorBesar berisi data pada kolom Author, namun menggunakan huruf KAPITAL.
books$AuthorBesar <- str_to_upper(books$Author)
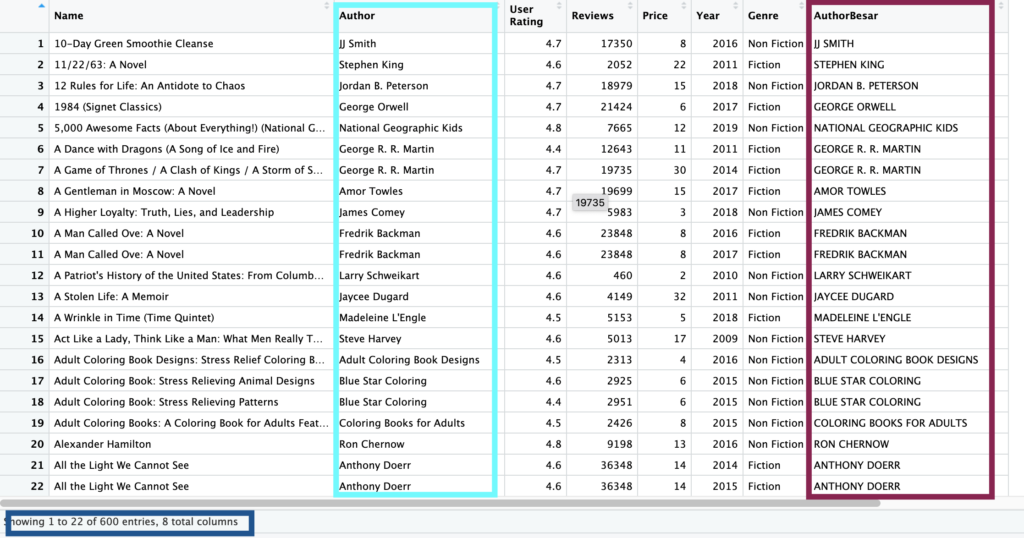
Seperti terlihat, R memproses kolom Author pada seluruh baris, sama seperti menyalin formula Excel ke semua baris.
Membagi Teks, Mendapatkan Nama Depan
Pada bagian sebelumnya kita telah belajar cara membagi teks berdasarkan spasi. Kita dapat menggunakan metode tersebut untuk mendapatkan sebagian data, misal mendapatkan nama depan penulis.
books$AuthorNamaDepan <- sapply(str_split(books$Author, pattern = ' '), head, n=1)
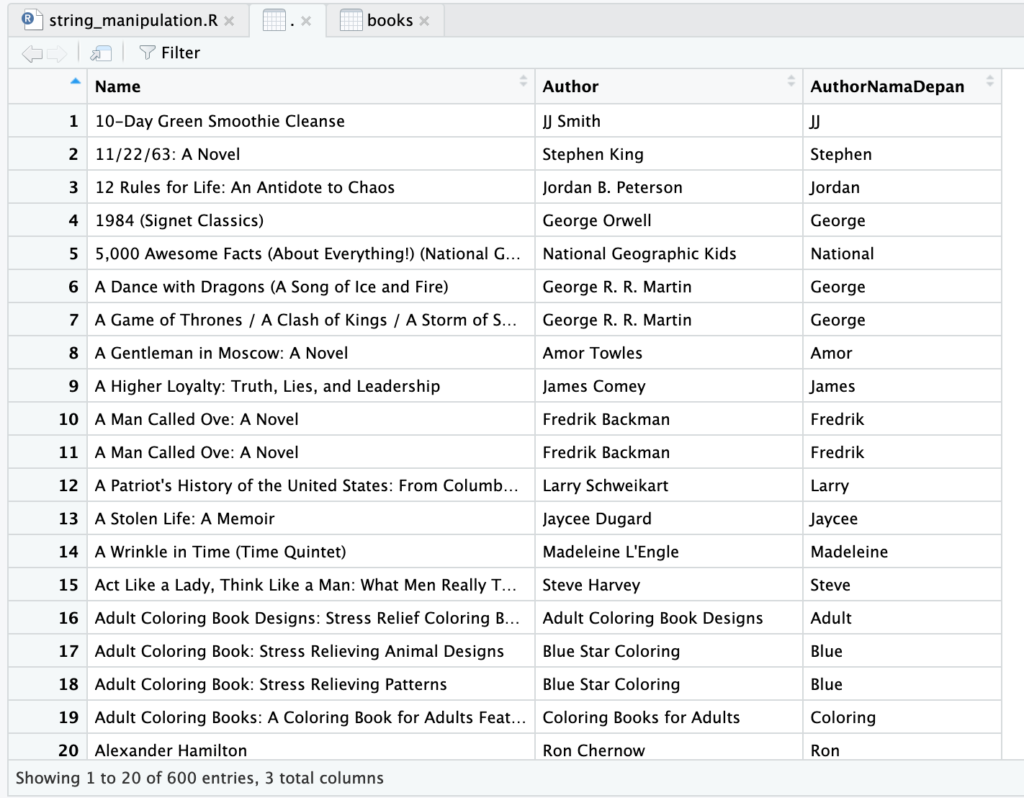
Menarik, ada beberapa tambahan kode selain str_split.
sapply
Adalah fungsi untuk mengaplikasikan sebuah fungsi pada semua elemen vector atau list, atau bahasa mudahnya fungsi sapply membaca semua baris data kemudian melakukan fungsi (katakanlah fungsi A). Fungsi sapply adalah turunan dari lapply dan terdapat beberapa varian lainnya.
Untuk menggunakan fungsi sapply setidaknya menggunakan urutan di bawah ini.
sapply(x, FUN, ...)
Dimana:
- x adalah data yang akan diproses
- FUN adalah fungsi yang akan diaplikasikan pada semua data
- … adalah argumen tambahan yang akan digunakan pada fungsi FUN
Nilai x diisi dengan:
str_split(books$Author, pattern = ' ')
Yang dari proses sebelumnya saat pertama kali menggunakan str_split kita tahu akan mengembalikan data berupa sebuah list (daftar) berisi nama per kata.
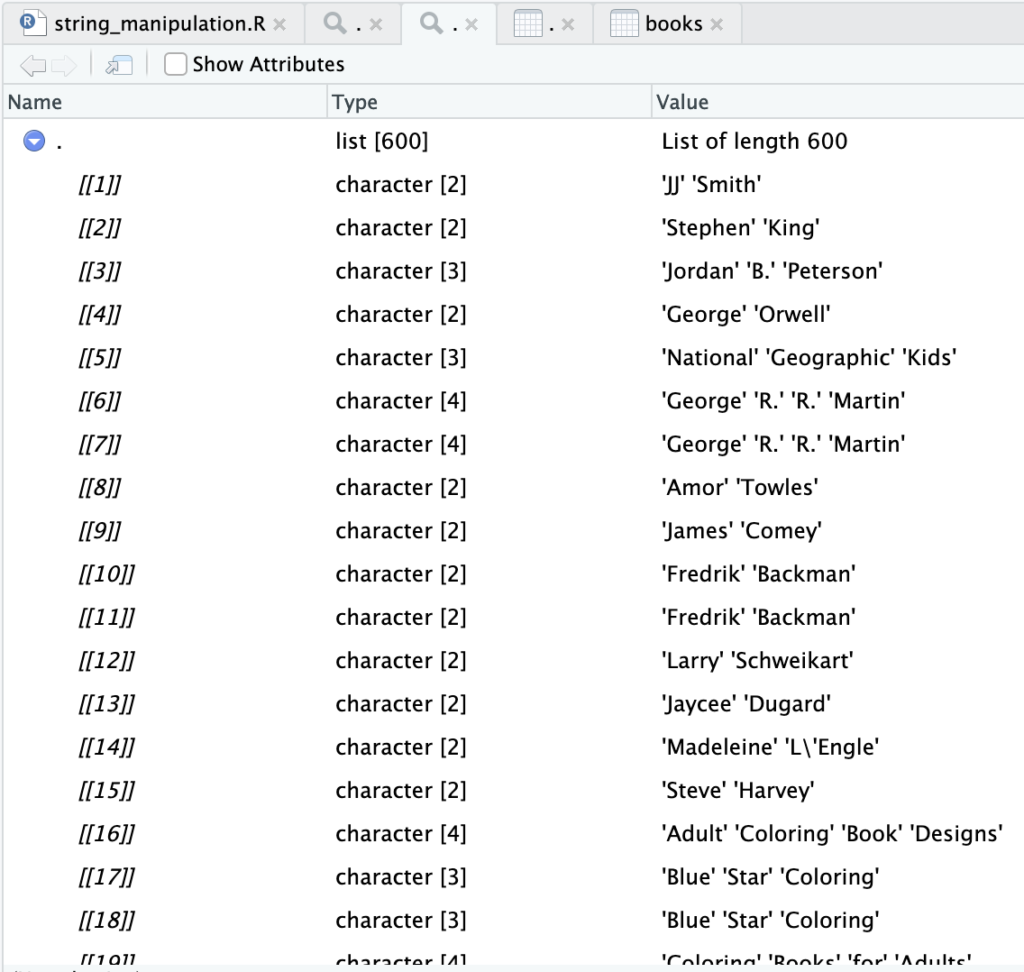
head
Sekarang kita bahas parameter kedua pada fungsi sapply, FUN.
FUN diisi dengan head, yaitu fungsi untuk mendapatkan beberapa (baris) data pertama. Contoh untuk mendapatkan 3 data pertama dari variabel books.
head(books, 3)
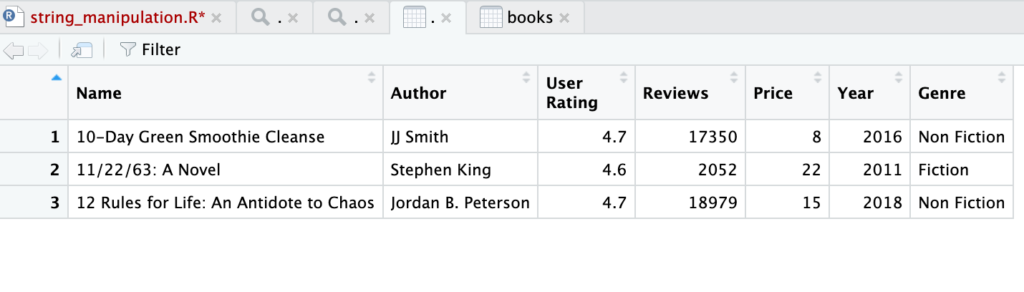
Mendapatkan 5 baris data pertama.
head(books, n = 5)
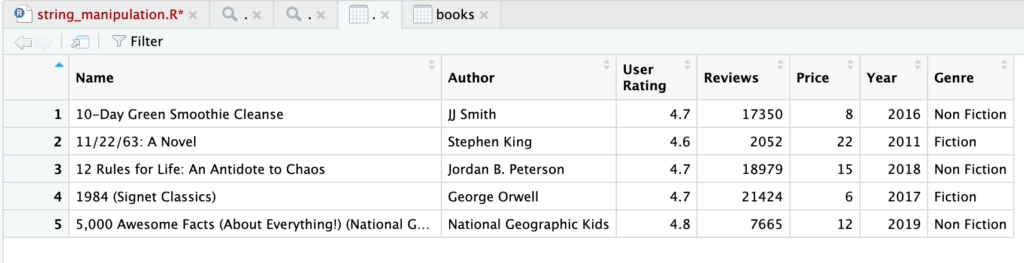
Terlihat parameter n digunakan untuk mendefinisikan berapa banyak data yang akan ditampilkan, 5. Pada kode sebelumnya tidak dituliskan n = 3 namun langsung angka 3 saja. Fungsi head akan otomatis mengidentifikas angka yang mengikuti variabel data (dalam hal ini books) sebagai n.
sapply, lagi
Berhubung telah dijelaskan fungsi sapply dan head, kita dapat meninjau kembali penggunaan sapply untuk mendapatkan nama depan Author, kali ini dengan pengetahuan baru.
books$AuthorNamaDepan <- sapply(str_split(books$Author, pattern = ' '), head, n=1)
Fungsi str_split menyediakan data yang akan diolah oleh sapply. FUN (fungsi yang akan dipanggil) oleh sapply diganti dengan head. Sedangkan n=1 adalah parameter yang akan digunakan oleh head sehingga hanya mengembalikan satu kata.
[
Umumnya pencarian “r get firstname” pada Google akan menghasilkan kode seperti ini.
books$AuthorNamaDepan2 <- sapply(str_split(books$Author, pattern = ' '), '[', 1)
Sedikit berbeda dengan kode yang kita gunakan, head diganti menjadi ‘[‘ dan n=1 cukup ditulis 1. Hasil kode tersebut sama saja.
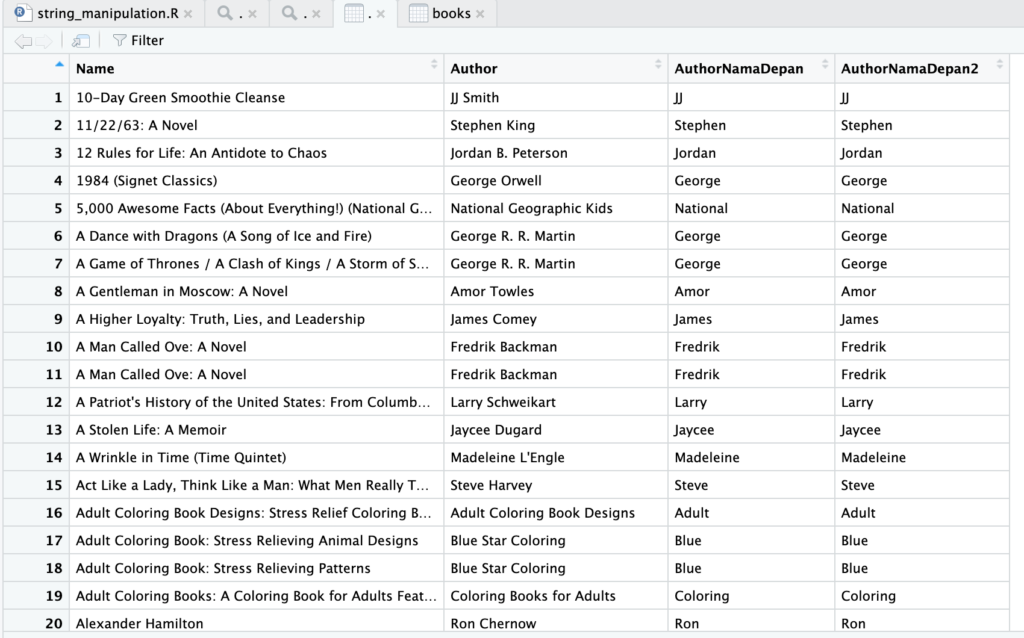
Kita bahas dulu apa kegunaan [ (square bracket).
Kolom Pertama
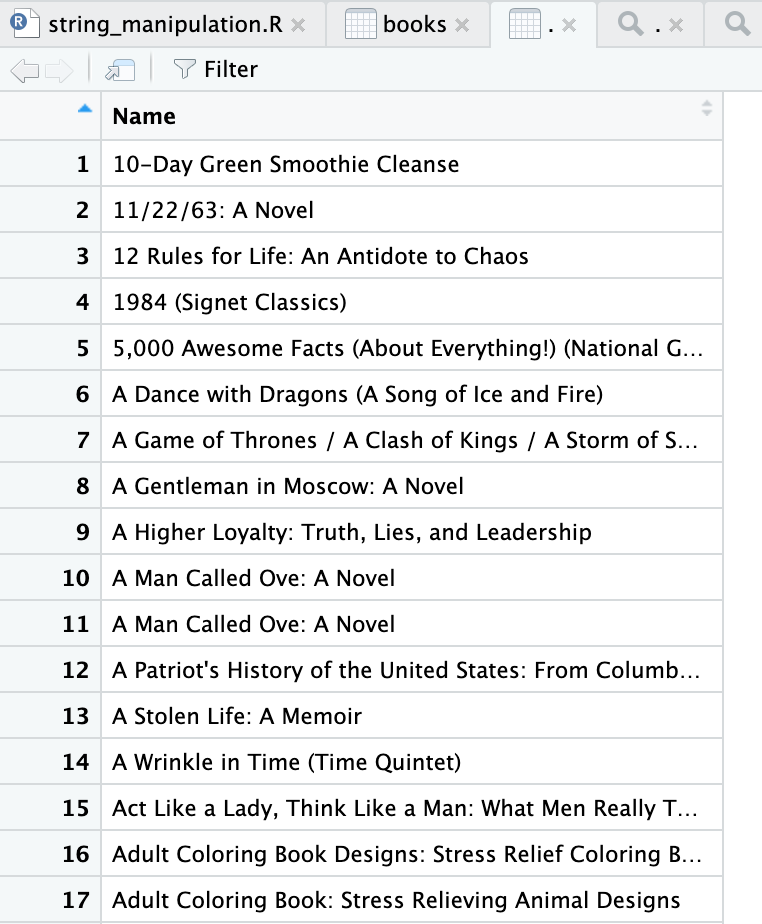
Kurung siku digunakan dalam R untuk mengambil atau mengganti sebagian data. Sebagai contoh, kode di bawah ini akan mengambil kolom pertama (nama buku) dari variabel books.
books[1]
Kolom Kedua
Kode ini untuk mengambil kolom kedua.
books[2]
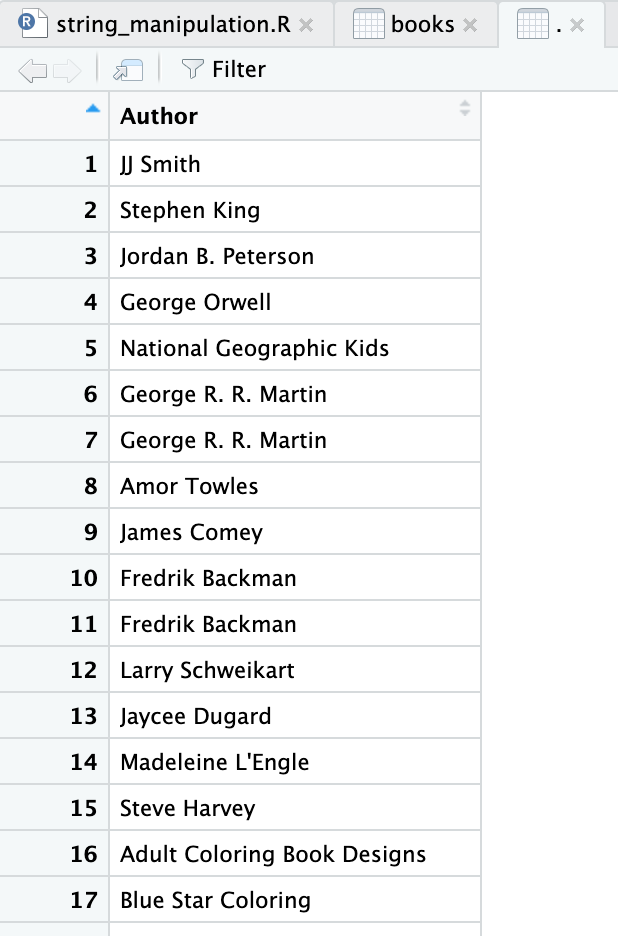
Beberapa Kolom
Beberapa kolom sekaligus dapat pula diambil, di bawah ini kita mengambil kolom pertama hingga ketiga.
books[1:3]
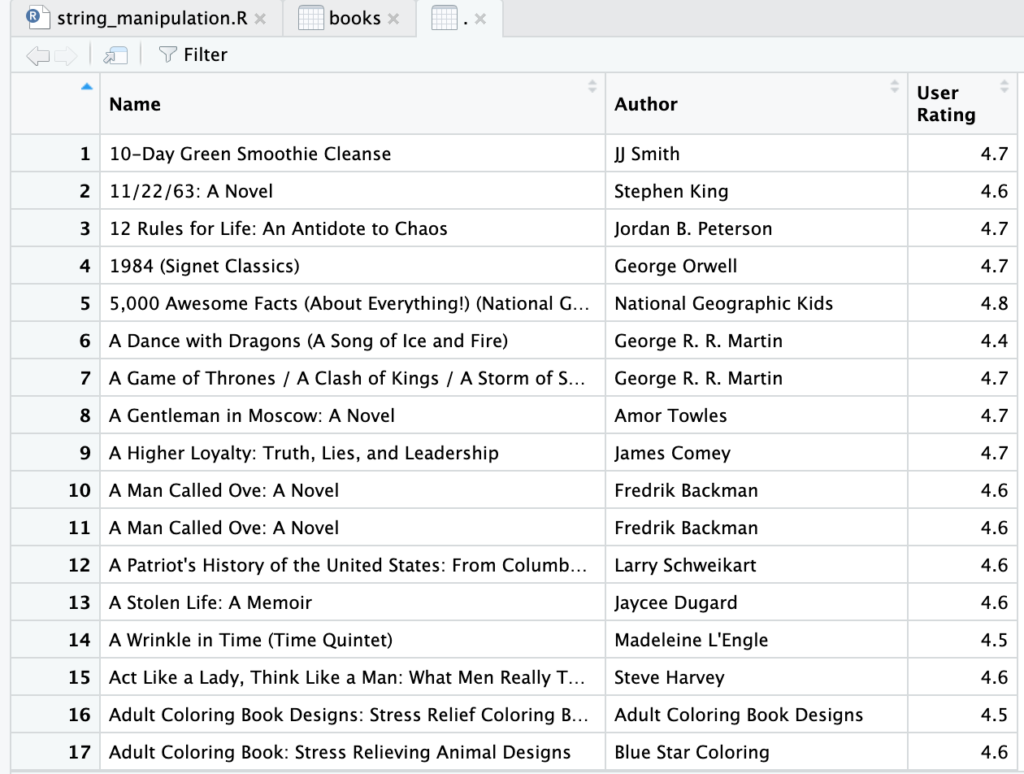
Kolom dan Baris
Untuk mendapatkan data pada cell (posisi baris dan kolom) tertentu, kode yang digunakan seperti di bawah ini.
books[1, 2]
- 1 = baris
- 2 = kolom
Sehingga jika merujuk pada nomor baris dan kolom tersebut, sesuai “peta” di bawah ini, hasil yang kita dapatkan adalah JJ Smith.

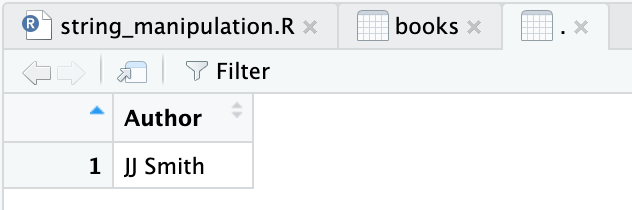
Seluruh Kolom pada suatu Baris
Dari bagian sebelumnya kita tahu bahwa angka pertama (sebelum koma di dalam kurung siku) merujuk pada nomor baris yang ingin diambil sehingga untuk mendapatkan semua kolom pada suatu baris, kita dapat mengosongkan angka kedua, namun tetap menyertakan tanda koma.
books[1,]
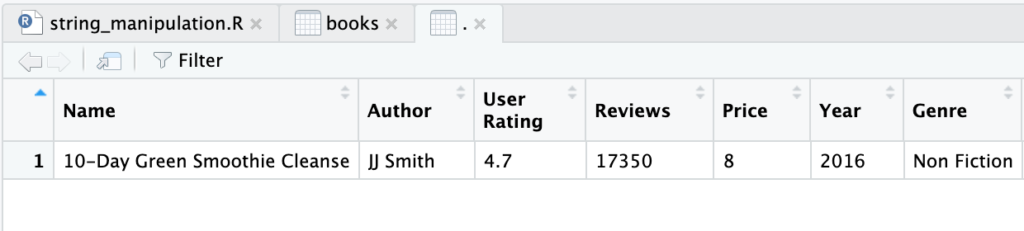
Dengan atau Tanpa Koma
Berdasar contoh di atas, jika hanya ada satu angka dalam kurung siku maka akan diambil kolom yang dirujuk angka tersebut. Jika dalam kurung siku hanya ada satu angka yang diikuti koma maka akan diambil baris yang dirujuk angka itu.
- [2] = data kolom 2 pada semua baris
- [2,] = data baris 2 pada semua kolom
[ lagi
Kita kunjungi lagi kode untuk mengambil nama depan, menggunakan [ sebagai pengganti FUN pada sapply.
books$AuthorNamaDepan2 <- sapply(str_split(books$Author, pattern = ' '), '[', 1)
Kurung siku dan angka 1 pada kode di atas sama dengan:
[1]
Yang artinya mengambil kolom pertama dari data yang disediakan. Untuk membuktikannya, kita dapat bereksperimen, misal dengan mengganti angka 1 menjadi 2 dengan asumsi kita akan mendapatkan kolom kedua (kata kedua pada nama Author).
books$AuthorNamaKedua <- sapply(str_split(books$Author, pattern = ' '), '[', 2)
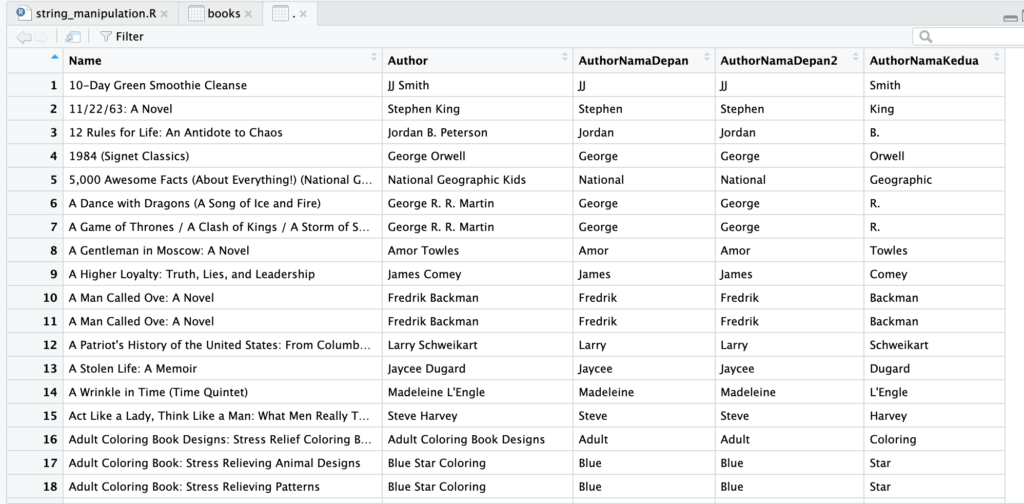
Ye kan, benel kan?
Mendapatkan Nama Keluarga
Setelah mendapatkan nama pertama, biasanya yang perlu dilakukan selanjutnya adalah mendapatkan nama keluarga.
Meski menggunakan ilustrasi mendapatkan nama depan dan nama keluarga namun metode yang kita gunakan dapat diaplikasikan pada banyak skenario yang memerlukan mendapatkan elemen pertama dan elemen terakhir pada data.
Secara intuitif saat ini kita akan mengetahui pasti ada fungsi yang “berlawanan” dengan head, dimana head dipakai untuk mendapatkan elemen pertama dan fungsi satunya untuk mengambil elemen terakhir.
tail
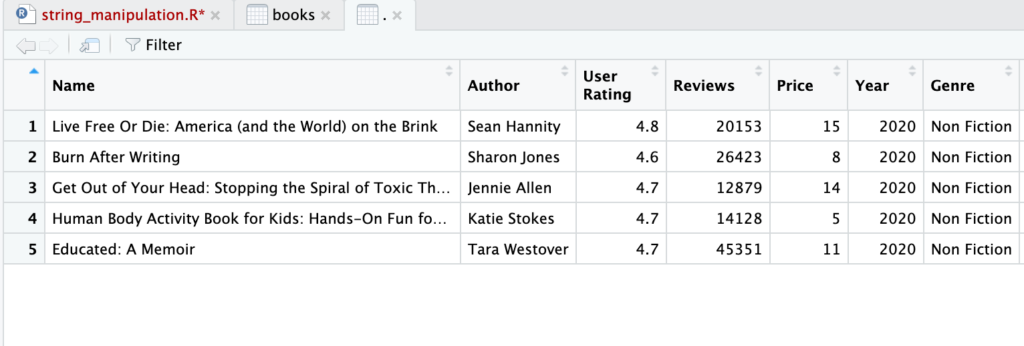
Fungsi untuk mendapatkan beberapa (n) elemen terakhir adalah tail, penggunaan tail mirip dengan head.
tail(books, n = 5)
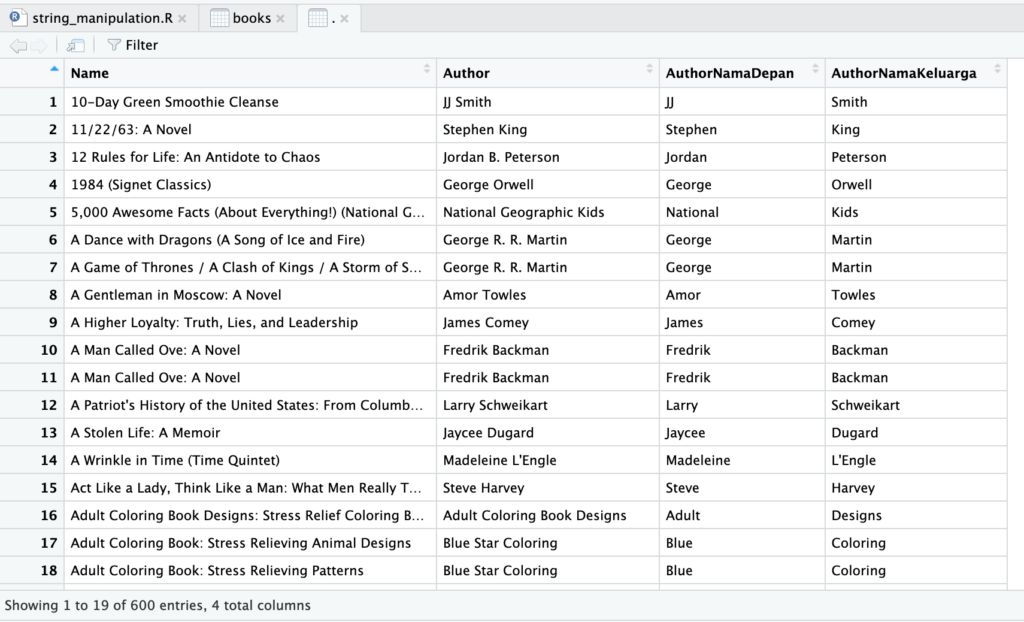
Berbekal tail, kita dapat membuat kolom baru berisi nama keluarga.
books$AuthorNamaKeluarga <- sapply(str_split(books$Author, pattern = ' '), tail, n=1)
Mengenali Pola
Kebutuhan lain saat berhadapan dengan teks adalah mengetahui apakah terdapat pola tertentu yang dimuat. Kemudian melakukan filter atau mengekstraksi data berdasar pola tersebut.
Pengarang dengan Huruf a
Kita mulai dengan yang ringan dulu, bagaimana mengidentifikasi jika suatu baris data mengandung huruf tertentu. Katakanlah kita ingin mengetahui apakah kolom Author mengandung huruf a.
Library stringr menyediakan fungsi str_detect untuk, seperti namanya, mendeteksi apakah terdapat pola tertentu pada teks.
Omong-omong stringr memiliki cheatsheet yang dapat diunduh di sini sehingga kita dapat dengan cepat “mengintip” fungsi-fungsi apa saja yang dapat kita gunakan untuk menangani teks.
Penggunaan str_detect mirip dengan str_split, yaitu parameter pertama adalah data yang diproses dan parameter kedua berisi pattern (pola) yang digunakan. Untuk menguji apakah sebuah baris data pada kolom Author mengandung huruf a kita dapat menggunakan kode di bawah ini.
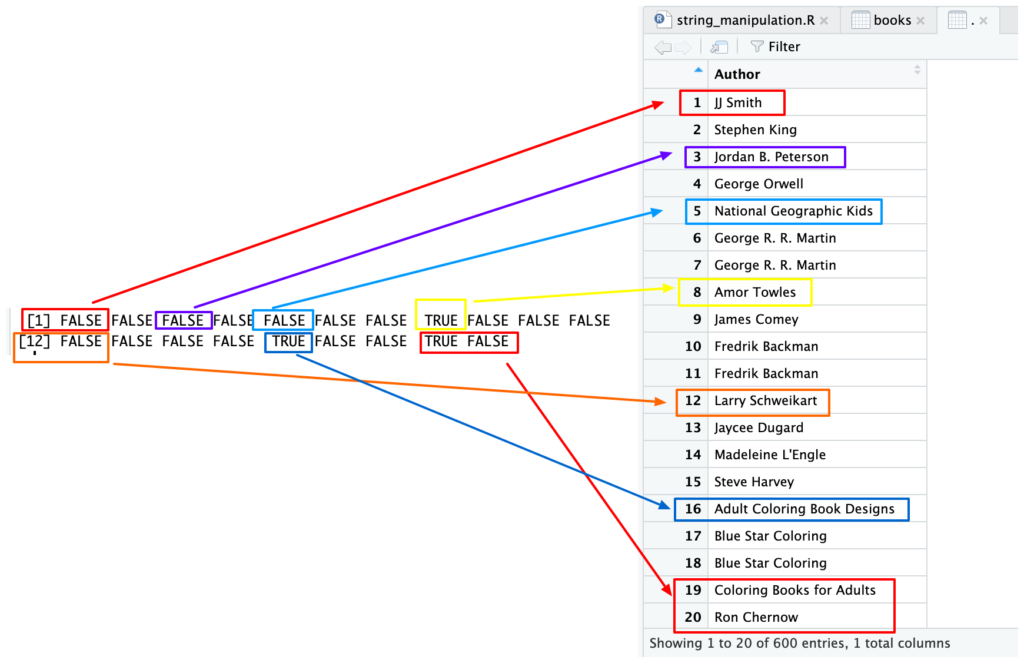
str_detect(books$Author, 'a')
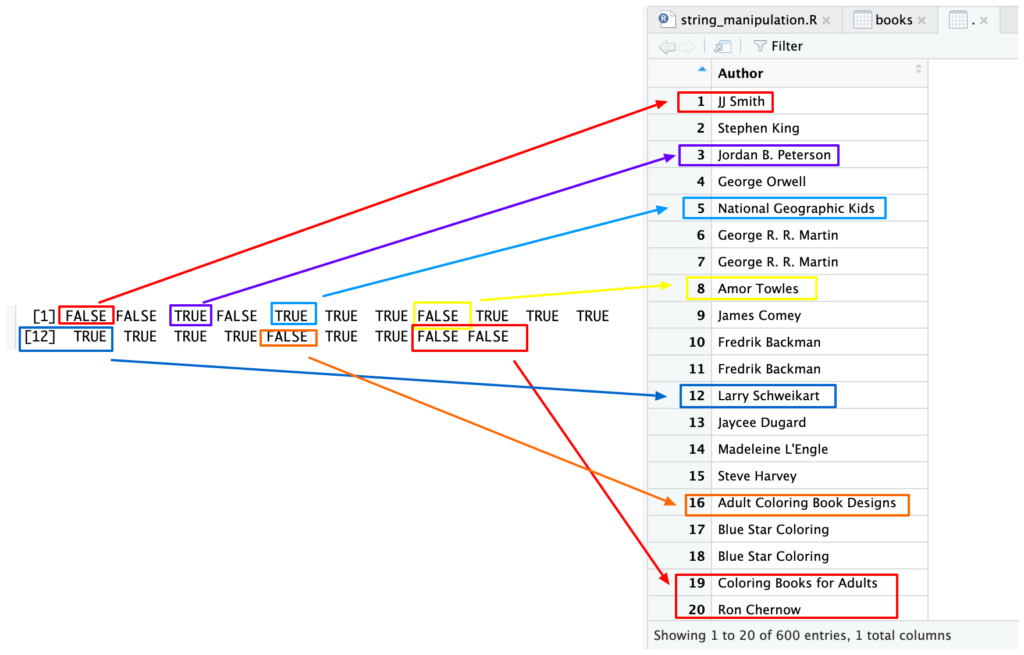
JJ Smith tidak menggunakan huruf a sehingga FALSE, sebaliknya Jordan B. Peterson dan National Geographic Kids menghasilkan TRUE. Namun Amor Towles, Adult Coloring Book Designs dan Coloring Books for Adults dianggap FALSE padahal terdapat huruf A?
Hal tersebut karena fungsi str_detect (dan banyak hal pada komputer) case sensitive, huruf besar dan kecil menjadi entitas yang berbeda satu sama lain.
Sehingga jika pola yang digunakan adalah A, bukan a seperti sebelumnya, hasilnya seperti ini.
str_detect(books$Author, 'A')
Bagaimana jika kita tidak peduli huruf besar atau kecil, “pokonya mau liat nyang ada a-nye“.
Case Insensitive
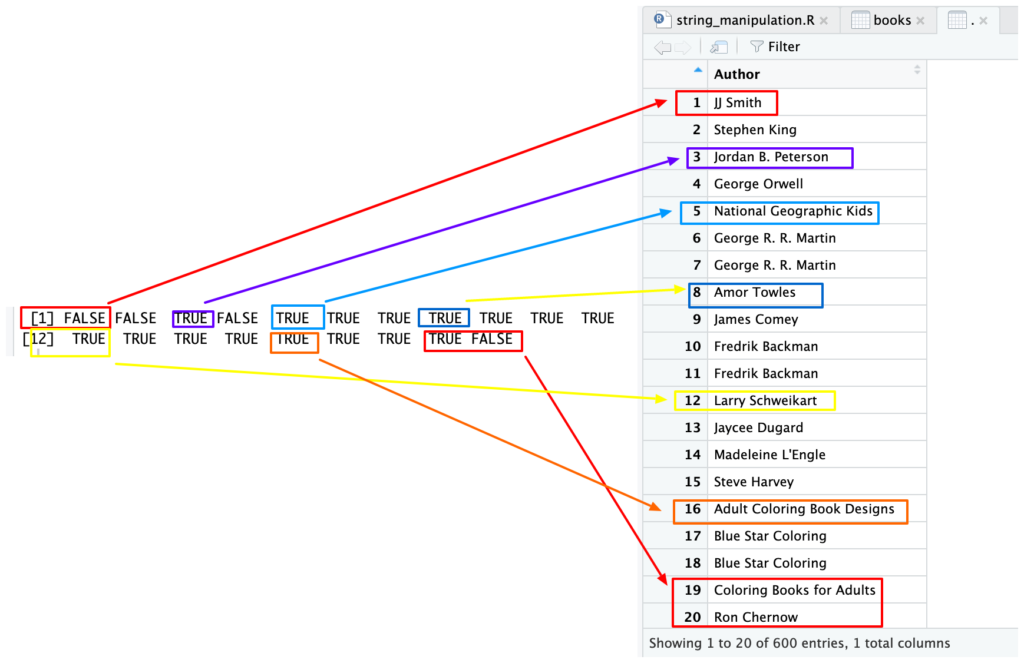
Ingin mengabaikan case sensitivity? Gunakan regex dan ubah parameter ignore_case-nya jadi TRUE.
str_detect(books$Author, regex('a', ignore_case = TRUE))
Filter
Salah satu kegunaan praktis dari pendeteksian pola pada teks adalah untuk menyaring hanya data yang mengandung (atau tidak) pola tertentu.
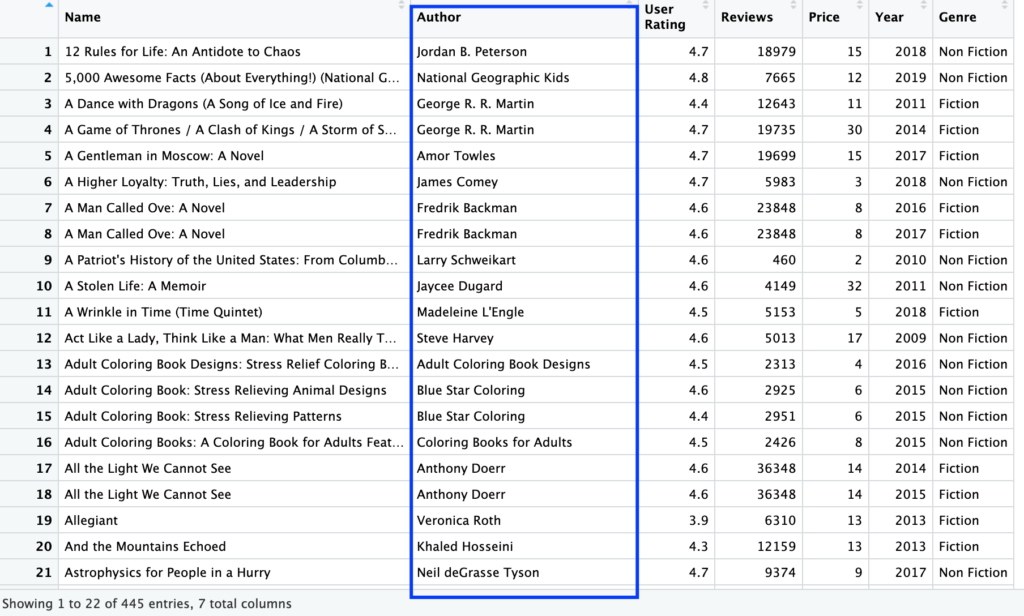
Melanjutkan sebelumnya, hasil berupa daftar TRUE/FALSE sepertinya kurang informatif bagi manusia, namun daftar tersebut dapat dimanfaatkan untuk menyaring data. Seperti menampilkan data jika kolom Author yang memiliki huruf a (baik BESAR maupun ketjil).
books %>%
filter(str_detect(books$Author, regex('a', ignore_case = TRUE)))
Negasi
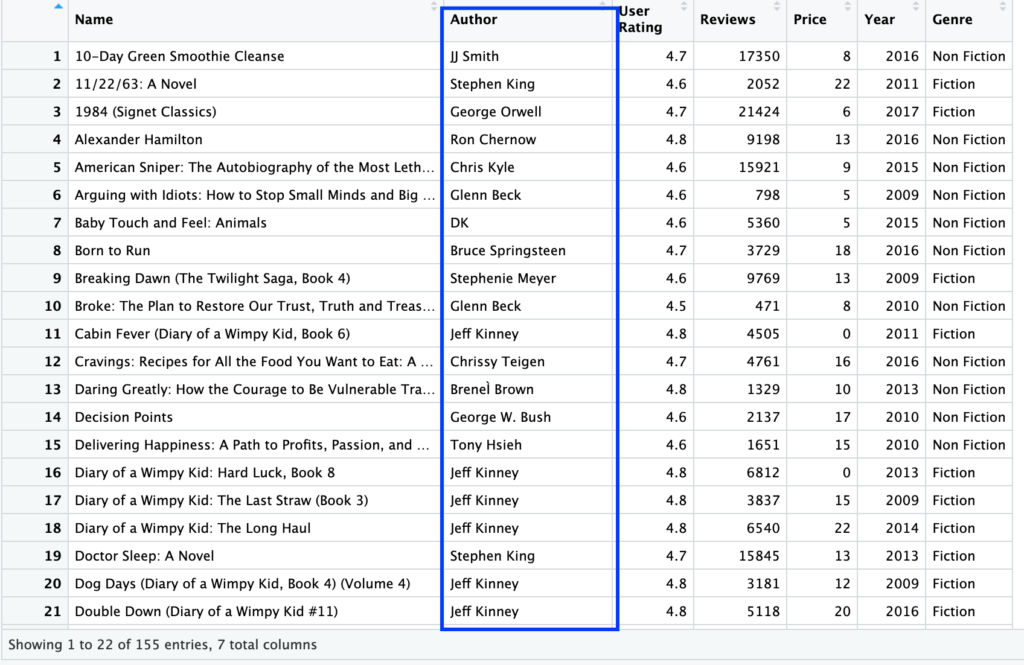
Kalau ingin menampilkan data yang kolom Authornya tidak mengandung huruf a, bagaimana?
Cukup menambahkan ! sebelum fungsi str_detect.
books %>%
filter(!str_detect(books$Author, regex('a', ignore_case = TRUE)))
Angk4 pada T3ks
Kebutuhan pengenalan pola makin meningkat, bagaimana jika ingin menyaring judul buku yang mengandung angka? Tidak seperti huruf atau karakter, angka bisa berapa saja, dimana saja, dalam bentuk apa saja (satuan, puluhan, ratusan, pecahan).
Gunakan regex. Tentu saja.
books %>% filter(str_detect(books$Name, '[0-9]+'))
Mengambil Teks
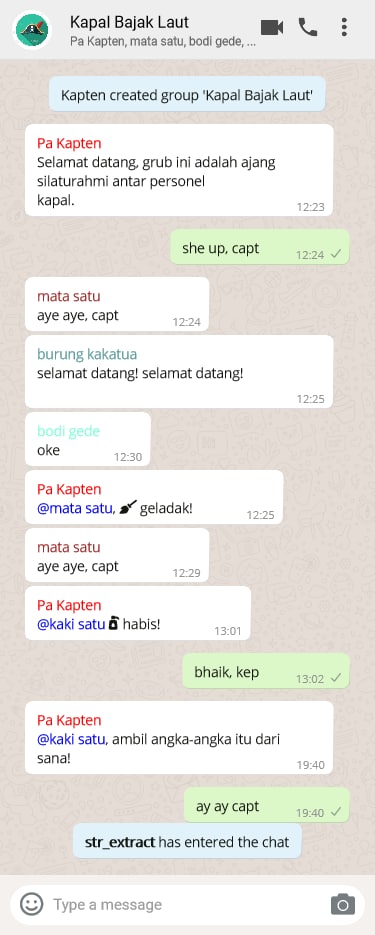
Stringr punya fungsi yang dapat didayagunakan untuk memenuhi jenis permintaan begitu, str_extract. Kaki satu dapat segera memenuhi perintah pa kapten karena pola penggunaan str_extract mirip dengan fungsi-fungsi stringr lainnya yaitu nama kolom yang akan diambil diikuti dengan pattern yang digunakan.
books$angka <- str_extract(books$Name, '[0-9]+')
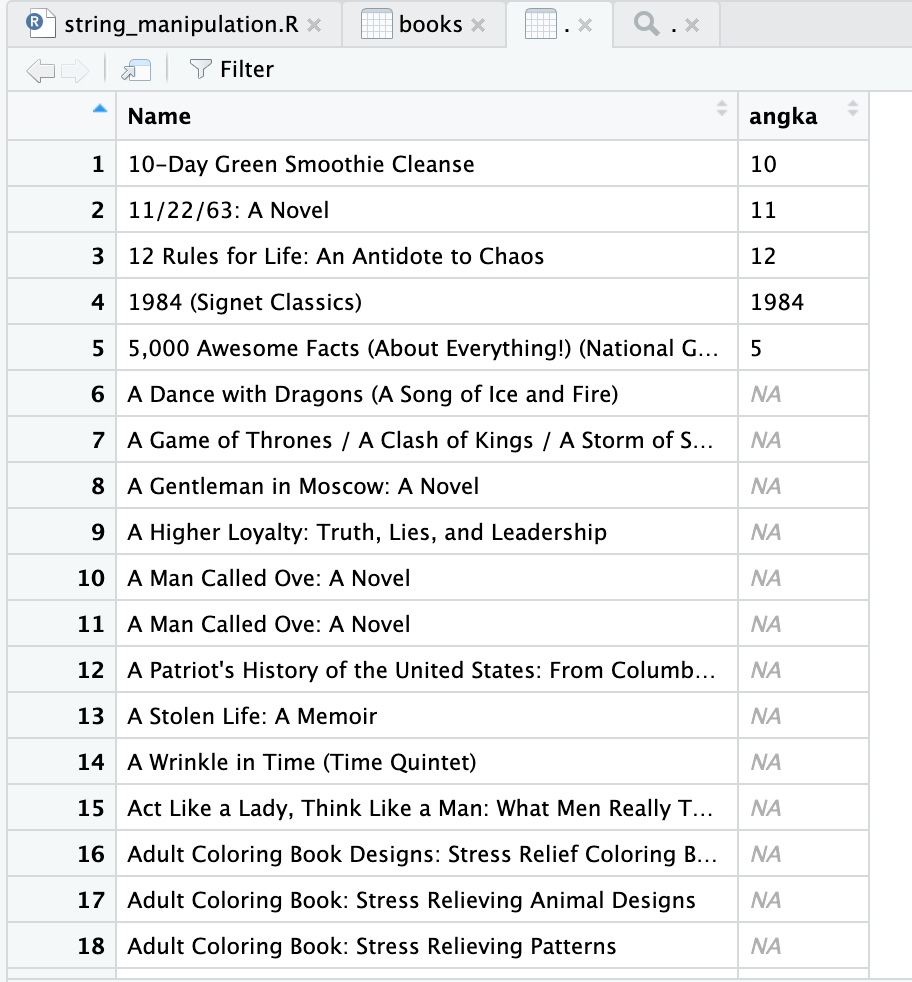
Wah, ternyata ada teks yang memiliki angka yang dipisahkan oleh tanda baca yaitu garis miring (baris ke-2) dan koma (baris ke-5). Fungsi str_extract hanya mengambil angka pertama saja.
str_extract_all
Kaki satu tak khawatir jika pa kapten meluaskan perintahnya menjadi dapatkan semua angka, karena ada fungsi str_extract_all yang dapat mengatasi hal tersebut.
books$angkasemua <- str_extract_all(books$Name, '[0-9]+')

Mengganti Teks
Jikalau ingin mengganti teks stringr memiliki fungsi str_replace dan str_replace_all. Contohnya untuk mengubah spasi pada nama buku menjadi garis bawah.
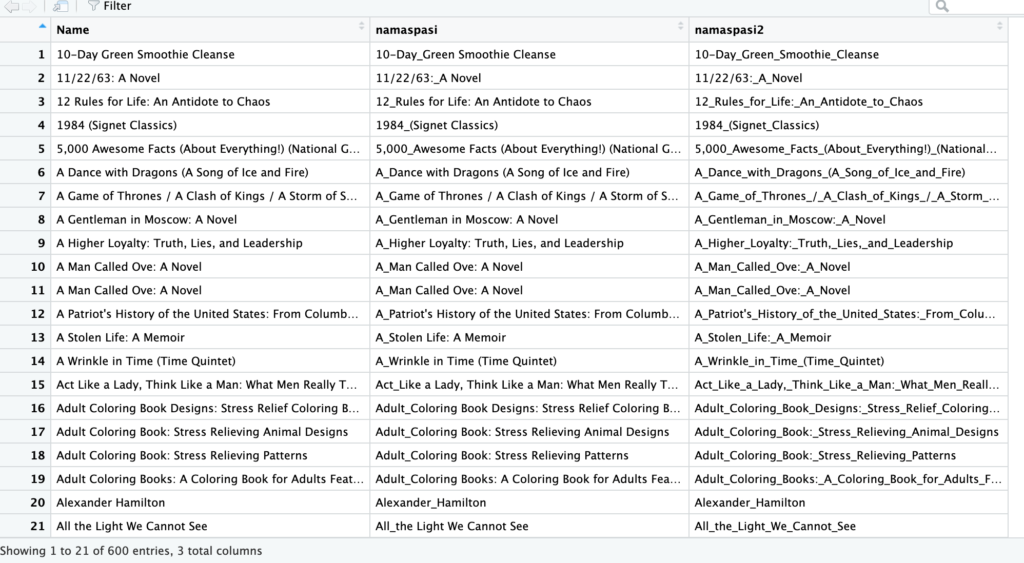
books$namaspasi <- str_replace(books$Name, ' ', '_')
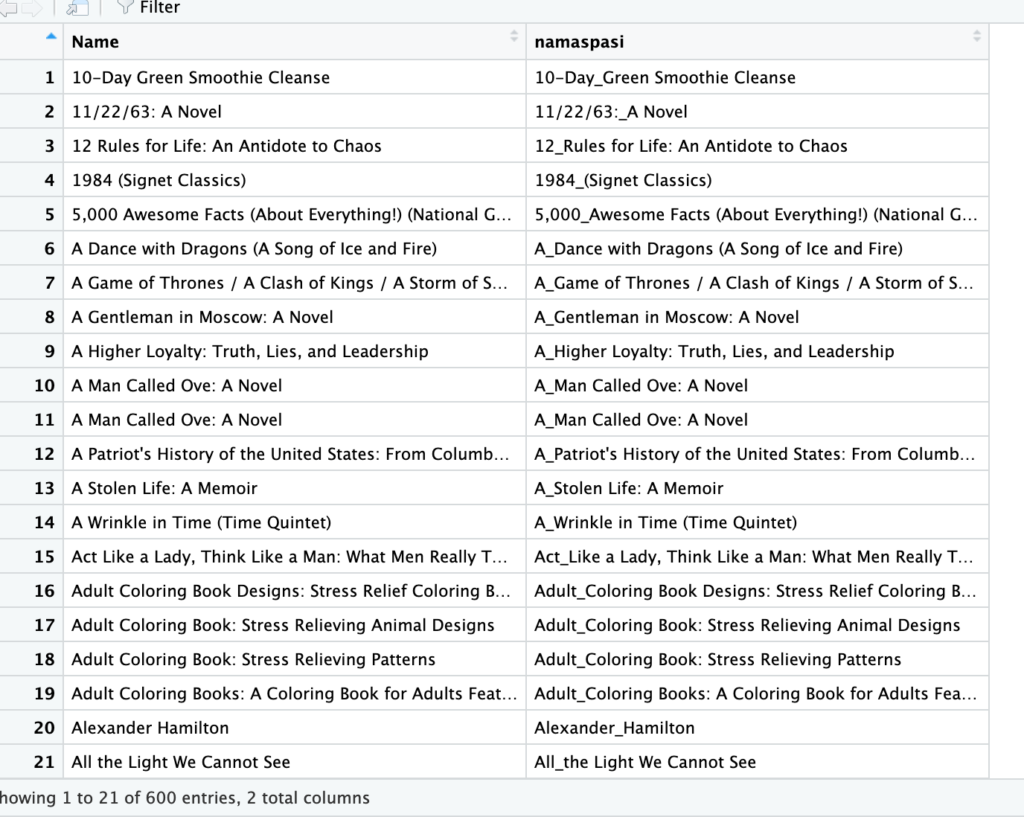
Seperti dugaan fungsi str_replace hanya mengubah pola pertama yang ditemukan. Untuk mengubah semua, perlu menggunakan str_replace_all.
books$namaspasi2 <- str_replace_all(books$Name, ' ', '_')
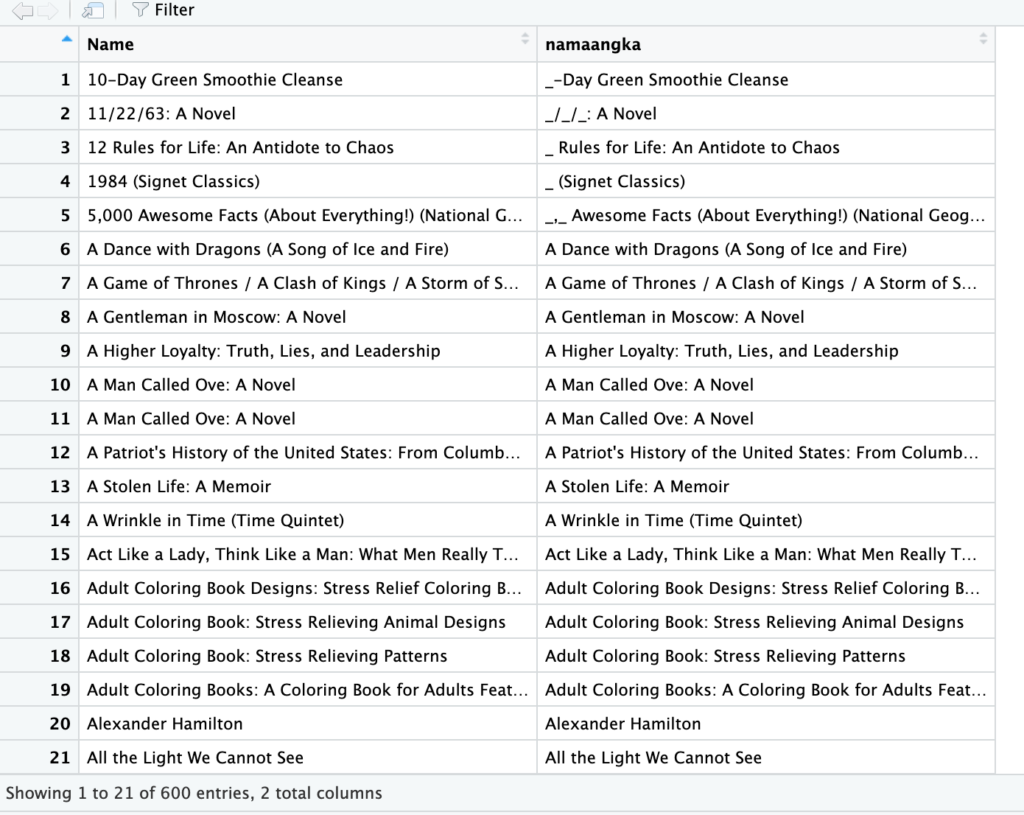
Sama seperti fungsi yang sebelum-sebelumnya, pola yang digunakan (sebenarnya) adalah regex sehingga kita dapat memodifikasi pola tersebut menjadi serumit yang dapat kita bayangkan dilakukan oleh regex. Semisal mengenali angka (itu cukup rumit menurut penulis) dan menggantinya dengan garis bawah (underscore).
books$namaangka <- str_replace_all(books$Name, '[0-9]+', '_')
Simpulan
Teks ada di mana-mana karenanya dapat kita pastikan bahwa teknologi apapun pasti memiliki banyak alat untuk menanganinya.
Best Practice – RStudio Project
Sebagai pengayaan, di bawah ini akan diterangkan langkah-langkah untuk membuat sebuah Project di RStudio. Salah satu alasan utama membuat Project adalah kita dapat mudah mengorganisir pekerjaan dan ubo rampenya.
Misalkan hari-hari ini kita sedang bergelud dengan teks dari Excel, kita dapat mengisolir semua hal yang berkaitan dengan itu (RScript, dokumen sumber data dan sebagainya) pada satu folder tertentu. Kemudian jika di masa depan kita punya kebutuhan untuk melihat kembali pekerjaan tersebut, tinggal klik saja file RStudio Projectnya maka kita akan kembali ke “titik terakhir” pekerjaan itu.
Bila mengerjakan tema lain, tempat kerja kita di RStudio tidak akan “tercemar” oleh proyek lain sehingga kita dapat lebih fokus dan terorganisir dalam bekerja.
Workspace
Agar tidak tercemar dan mencemari pekerjaan kita di tiap sesi, Pak Wickham menyarankan agar kita mengatur RStudio agar tidak “mengingat” data yang dikerjakan pada tiap sesi.
Pada menu Tools, pilih Global Options.
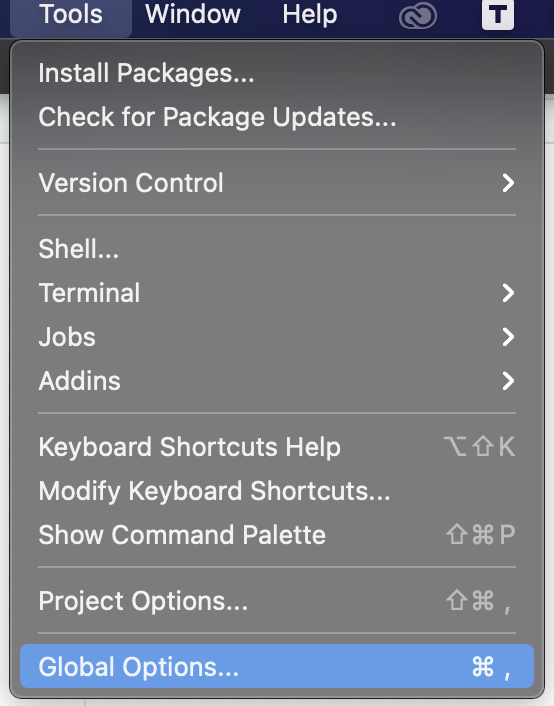
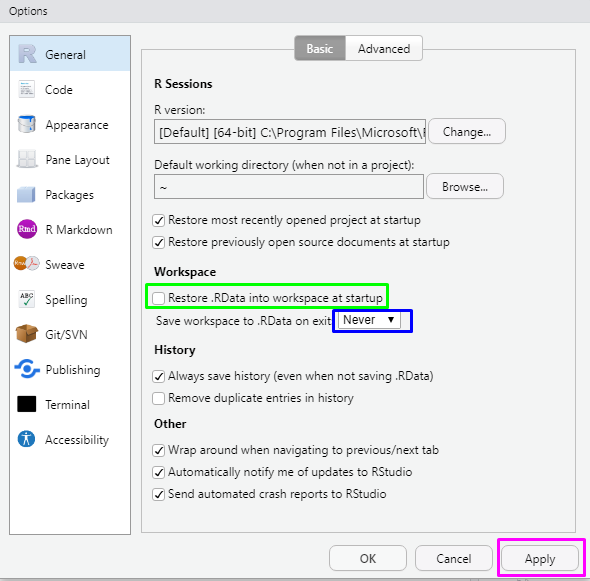
Kemudian pada menu General, hilangkan centang pada Restore .RData into workspace at startup. Dan pilih Never pada Save workspace to .RData on exit.
New Project
Untuk membuat Project, pada menu File pilih New Project.
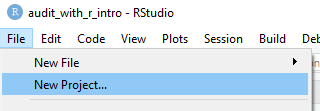
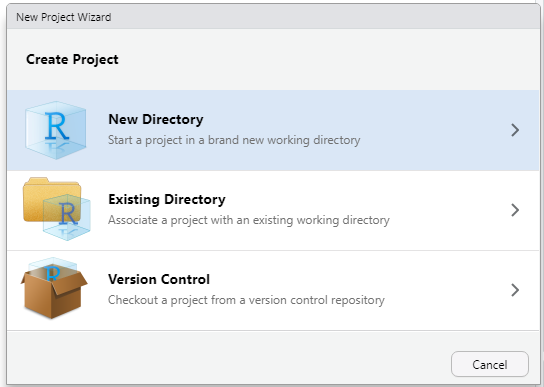
Kemudian pilih apakah Project akan disimpan dalam folder baru (New Directory) atau pada folder yang sudah ada. Atau pilih Version Control jika sudah menggunakannya.
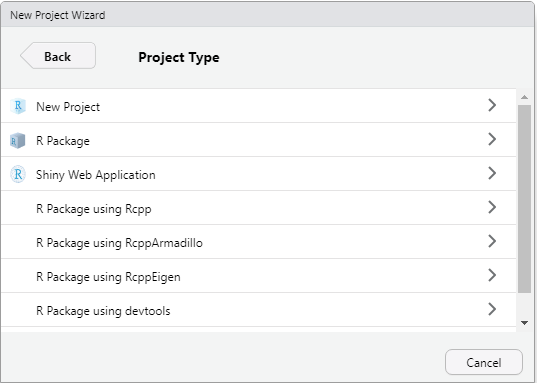
Selanjutnya pilih jenis Project dan beri nama.
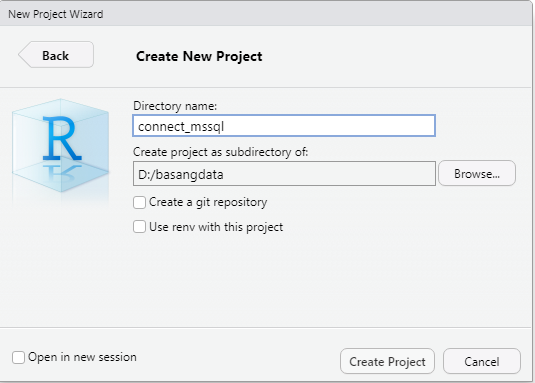
Di akhir proses kita akan mendapati sebuah file baru dengan ekstensi .Rproj. File inilah yang perlu kita buka untuk mengakses Project yang dibuat.

Cover Photo by Pixabay from Pexels
Langganan dan Saran
Jika suka tulisan di sini boleh berlangganan agar kami dapat mengirimkan pemberitahuan tulisan baru. Punya saran atau keluhan terhadap blog ini, sila ajukan langsung pada kami.
Referensi
- https://stringr.tidyverse.org/
- https://r4ds.had.co.nz/strings.html
- https://github.com/rstudio/cheatsheets/blob/master/strings.pdf
- https://r4ds.had.co.nz/workflow-projects.html
- https://www.kaggle.com/palanjali007/amazons-top-50-bestselling-novels-20092020?select=AmazonBooks.xlsx
- https://stackoverflow.com/questions/19321673/extracting-first-names-in-r/19321809
- https://stackoverflow.com/questions/47576458/extract-last-name-from-a-full-name-using-r
- https://www.rdocumentation.org/packages/base/versions/3.6.2/topics/lapply
- https://stackoverflow.com/questions/19260951/using-square-bracket-as-a-function-for-lapply-in-r
- https://stackoverflow.com/questions/77434/how-to-access-the-last-value-in-a-vector
- https://stackoverflow.com/questions/57412700/whats-the-difference-between-the-str-detect-function-in-stringer-and-grepl-and
One Reply to “Audit Data Analytics dengan R – Mengelola Teks”