

Audit Data Analitics dengan R – Query pada Database
You can have data without information, but you cannot have information without data.
DKM
KODE LIMA DETIK
library(odbc)
library(tidyverse)
con <- dbConnect(odbc::odbc(),
driver = 'ODBC Driver 17 for SQL Server',
server = 'localhost',
database = 'AdventureWorksLT2019',
UID = 'sa',
PWD = 'pwd')
customer <- tbl(con, dbplyr::in_schema('SalesLT', 'Customer'))
customer_mr <- tbl(con, sql("SELECT * FROM SalesLT.Customer WHERE Title = 'Mr.'"))
vgetallcategories <- tbl(con, dbplyr::in_schema('SalesLT', 'vGetAllCategories'))
product <- tbl(con, dbplyr::in_schema('SalesLT', 'Product'))
product_category <- tbl(con, dbplyr::in_schema('SalesLT', 'ProductCategory'))
p_cat <- product %>%
left_join(
product_category,
by = 'ProductCategoryID'
)
p_cat %>% show_query()
Tujuan
Dalam tulisan ini kita akan belajar.
- Membuat koneksi ke database, MS SQL
- Membuat query sederhana
- Menyimpan hasil query
Urgensi
Semua organisasi kekiniyan menyimpan data mereka di komputer. Dalam bentuk paling minimal, setidaknya untuk pencatatan transaksi keuangan terdapat perangkat lunak yang digunakan merekam data agar mudah saat penyusunan laporan keuangan.
Ke mana data tersebut bermuara? RDBMS alias database.
Bagi auditor skeptisme adalah nama tengahnya. Semua hal yang disampaikan oleh auditee dipertanyakan, diuji kebenarannya. Tersebab itu tak mengherankan jika auditor ragu pada data yang diberikan padanya.
Bila punya akses langsung ke database, auditor tentu lebih memilih menimba data dari sana. Yang jadi soal sekarang hanya bagaimana cara untuk itu.
Pada tulisan ini kita akan “mencoba” library dbplyr, yang merupakan bagian dari tidyverse, untuk menambang data dari RDBMS.
SQL
Dibaca sequel (atau pelafalan lain untuk memudahkan komunikasi), adalah bahasa yang kita, manusia, gunakan untuk berkomunikasi dengan database. Lantas jika sudah tau SQL mengapa perlu “belajar” dbplyr? Seakan beban hidup yang sekarang masih kurang.
dbplyr is designed to work with database tables as if they were local data frames.
dbplyr doc, usage section
Library ini bekerja di balik tabir, membuat kita seolah bekerja dengan variabel data yang sudah di-load di memory.
Sebagai pengingat, pada tulisan-tulisan sebelumnya kita membaca data dari csv dan MS Excel, yang kemudian disimpan dalam memory dan bekerja dengannya, membaca dan memanipulasi. Semua hal yang kita lakukan pada data dilakukan saat itu juga, pada data itu.
dbplyr menciptakan ilusi yang sama. Seolah bekerja pada data yang ada dalam memory padahal dbplyr mengkonversi perintah-perintah yang kita ketik menjadi SQL, kemudian saat kita sudah siap, barulah dieksekusi, untuk diambil datanya.
Disebut ilusi karena kita mengetik perintah yang sama seperti saat bekerja dengan data yang ada di dalam memory. Sebagai manfaatnya, jika kita sudah tau bagaimana bekerja dengan data (yang ada dalam memory) maka kita dapat pula mengolah data yang ada dalam database meski dengan sedikit (atau tanpa) pengetahuan tentang SQL.
Studi Kasus
Dalam tulisan ini kita akan menggunakan database AdventureWorks yang tersohor. Bedanya kali ini yang akan digunakan adalah versi Liteweightnya yang dapat diunduh di sini.
Tantangan ditingkatkan, alih-alih hanya berkenalan dengan dbplyr dan mencoba sembarang query, kita akan mengerjakan tugas yang diberikan oleh SQLZoo. Soal yang diberikan mulai dari yang mudah seperti menampilkan nama depan pelanggan hingga mencari alamat pengiriman bagi pelanggan yang berkantor di Dallas.
Teknologi Digunakan
Library DBI
Library ini membantu R berhubungan dengan banyak RDBMS. Instalasi dapat melalui Pane Packages kemudian mengetikkan DBI, klik Install.
Atau mengetikkan kode di bawah ini.
install.packages('DBI')
Library dbplyr (tidyverse)
dbplyr merupakan bagian dari tidyverse, karena itu jika sudah melakukan instalasi tidyverse tidak perlu lagi melakukan dplyr secara terpisah.
install.packages('tidyverse')
AdventureWorks Lite
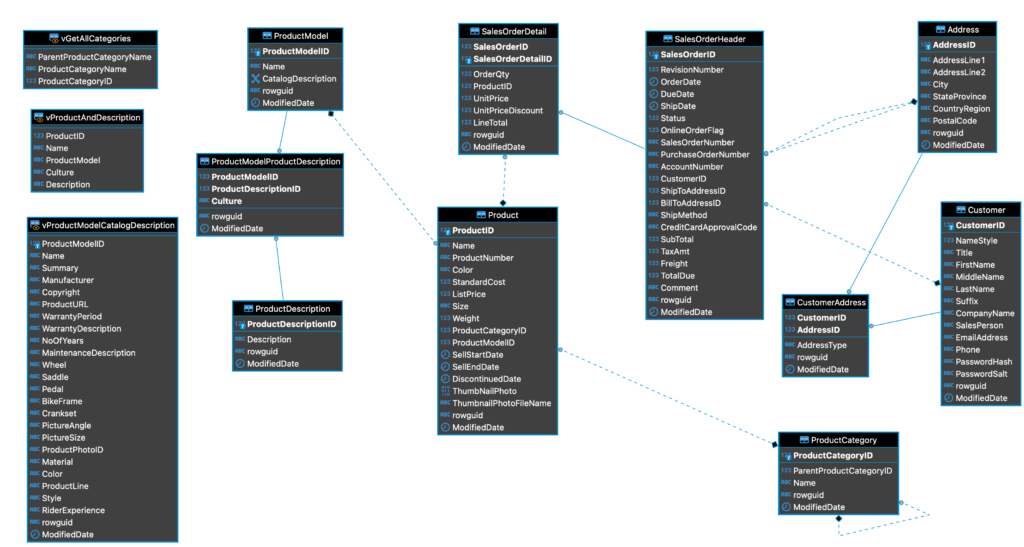
Karena versi ringan dari AdventureWorks, data ini hanya memiliki 13 tabel dan baris data yang lebih sedikit. Konsekuensi logis dari itu adalah, berkas backup database yang kecil, hanya 8,1MB.
Skema tabel AdventureWorksLT2019 kurang lebih seperti ini.
MS SQL ODBC
Agar dapat berhubungan dengan MSSQL kita perlu memiliki ODBC Driver untuk MSSQL. Bagi pengguna Windows dapat mengunduh di sini kemudian melakukan instalasi (yang mudah) seperti biasa.
Semasa tulisan ini dibuat, ODBC Driver terbaru adalah versi ODBC Driver 17 for SQL Server.
Tersebab ingin memastikan proses instalasi ODBC Driver telah berhasil, kita boleh mengetik ODBC pada pencarian windows (kiri bawah sebelah logo Windows) kemudian pilih ODBC Data Sources. Selanjutnya pada ODBC Data Source Administrator pilih tab Drivers.
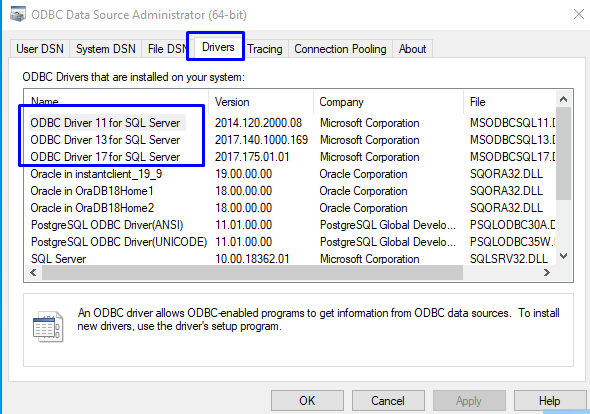
Jika MacOS atau linux adalah tempat bekerja kita, maka freetds dan unixodbc bisa menjadi pilihan selain driver yang disediakan oleh Microsoft.
Pengenalan
Setelah kelar dengan proses instalasi dan restore database, kita dapat mulai bekerja dengan data AdventureWorks. Kode di bawah ini akan me-load library dibutuhkan dan membuat variabel con yang merupakan “koneksi” odbc ke database AdventureWorksLT2019.
UID (User ID) diisi dengan sa, username standar yang ‘biasanya’ ada di MSSQL. Bagian UID dan PWD (Password) tentu harus disesuaikan dengan kondisi yang ditemui.
Oya, bagian lain seperti driver, server dan database juga harus tepat benar sesuai dengan yang sedang dikerjakan.
library(DBI)
library(tidyverse)
con <- dbConnect(odbc::odbc(),
driver = 'ODBC Driver 17 for SQL Server',
server = 'localhost',
database = 'AdventureWorksLT2019',
UID = 'sa',
PWD = 'pwd')
Jika koneksi berhasil, maka di Pane Connections akan muncul daftar database yang ada pada server yang dituju.
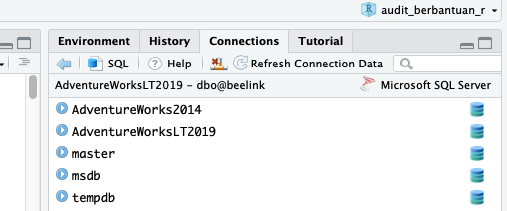
Di sebelah kiri masing-masing database terdapat panah yang dapat diklik, yang akan memunculkan skema yang ada.
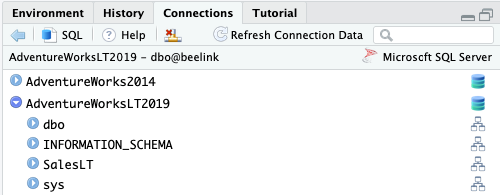
Seperti terlihat pada gambar di atas, database AdventureWorksLT2019 memiliki empat skema, dbo, INFORMATION_SCHEMA, SalesLT dan sys. Jika panah di kiri nama skema diklik maka akan ditampilkan tabel untuk masing-masingnya. Dari keempat skema, SalesLT adalah tempat data yang akan kita gunakan sehingga jika dibeber akan tampil daftar tabel seperti Address, Customer dan view seperti vGetAllCategories dan vProductAndDescription.
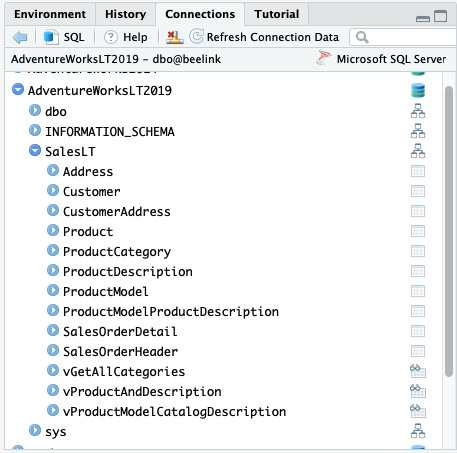
Pada masing-masing nama tabel terdapat ikon tabel yang jika diklik akan menampilkan data yang dimuatnya. Misal pada tabel Customer kita mendapati data berikut.
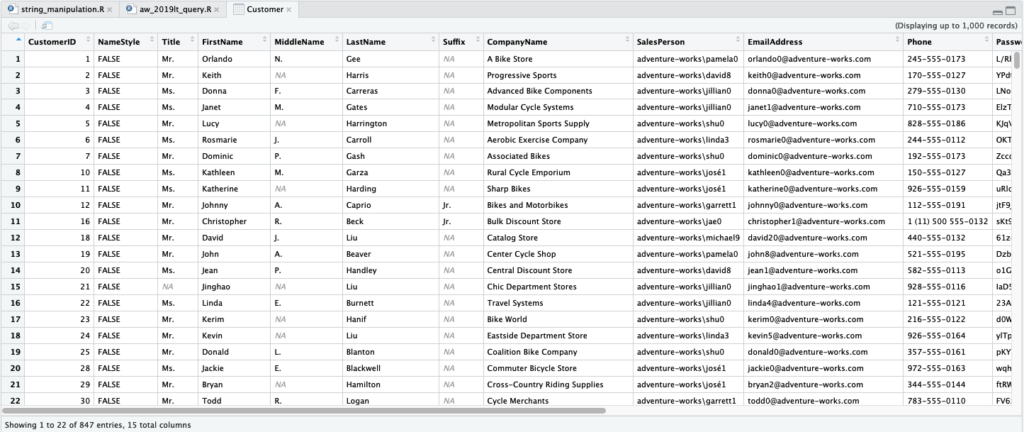
Fitur RStudio ini tentu memudahkan karena kita tidak perlu berpindah ke aplikasi lain jika sekedar hanya ingin melihat data apa yang ada pada tabel.
Tabel
Umumnya pada R kita membuat sebuah variabel untuk menampung data. Seperti di bawah ini, variabel datum digunakan untuk menampung data tiga baris.
datum <- data.frame(custID = c(1, 2, 3), Name = c('Orlando', 'Keith', 'Donna'))
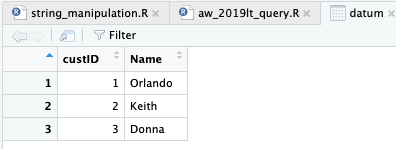
Pada RDBMS, data tersimpan pada tabel. Oleh karena itu tentu kita ingin membuat variabel untuk ‘menampung’ tabel itu. Fungsi yang disediakan dbplyr untuk ini adalah tbl. Penggunaannya cukup mengisi variabel koneksi (con) dan nama tabel. Jika hanya ada satu skema dalam database maka dapat langsung dipanggil nama tabel, misal untuk tabel Customer.
customer <- tbl(con, 'Customer')
AdventureWorksLT2019 memiliki empat skema. Karena itu kita perlu mendefinisikan skema yang digunakan, sebelum nama tabelnya. Fungsi in_schema ada untuk kebutuhan itu. Begini contoh kode digunakan.
customer <- tbl(con, dbplyr::in_schema('SalesLT', 'Customer'))
Jika kode tersebut dijalankan, kita akan mendapat sebuah variabel customer dengan tipe List, yang jika dibuka melalui klik pada Pane Environment tidak akan menampilkan data pada tabel.
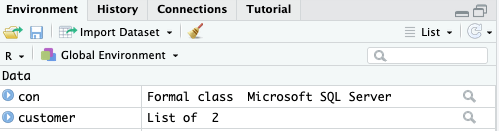
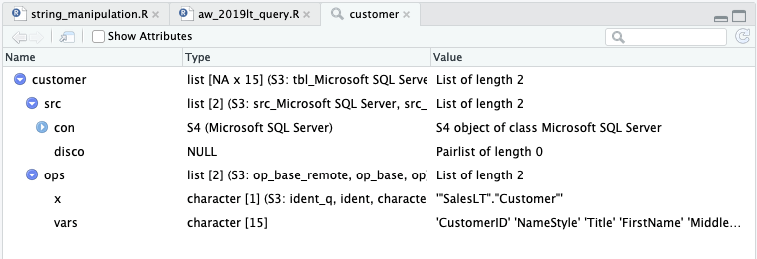
All dplyr calls are evaluated lazily, generating SQL that is only sent to the database when you request the data.
dbplyr doc
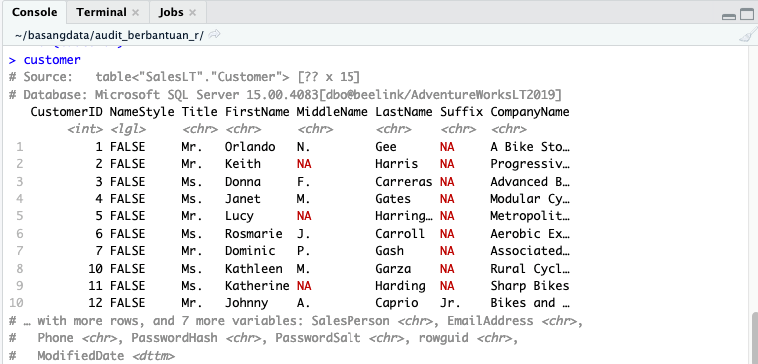
Adalah penyebabnya. Klik pada nama variabel di Pane Environment (atau penggunaan fungsi View() pada kode) tidak dianggap data request. Namun jika nama variabel dijalankan pada console, kita akan mendapat 10 baris data, cukup untuk mendapatkan gambaran mengenai data pada tabel.
Tabel dengan Filter
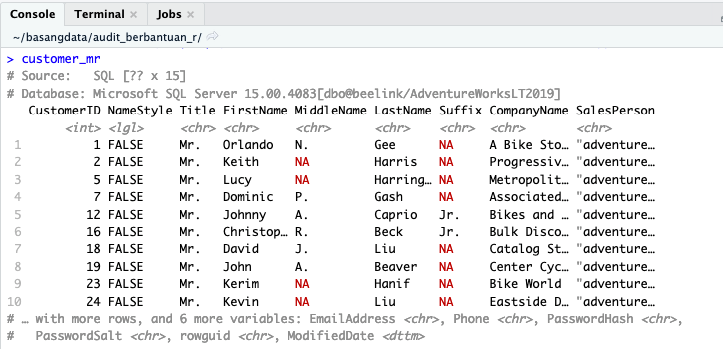
Atau lebih tepatnya menggunakan SQL untuk mendapatkan data yang lebih spesifik. Seperti jika ingin hanya customer dengan Title Mr. saja yang ingin ‘ditampung’ pada variabel.
customer_mr <- tbl(con, sql("SELECT * FROM SalesLT.Customer WHERE Title = 'Mr.'"))
View
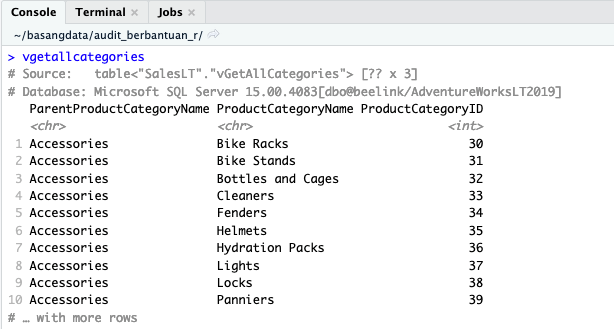
Semudah membuat penampung tabel, View pun hanya butuh sebaris kode untuk dibuatkan variabelnya. Misal untuk view vGetAllCategories.
vgetallcategories <- tbl(con, dbplyr::in_schema('SalesLT', 'vGetAllCategories'))
Relasi
Database, umumnya relational database, mensyaratkan normalisasi. Dalam bahasa sederhanya, data terpisah pada beberapa tabel. Sebagai efeknya bila ingin mendapatkan satu data yang merepresentasikan sebuah kejadian, kerapkali kita perlu merelasikan beberapa tabel.
Pada AdventureWorksLT2019 jika ingin mendapatkan nama dan kategori produk kita perlu merelasikan tabel Product dan ProductCategory. Pertama kita buat variabel untuk masing-masing tabel.
product <- tbl(con, dbplyr::in_schema('SalesLT', 'Product'))
product_category <- tbl(con, dbplyr::in_schema('SalesLT', 'ProductCategory'))
Kemudian kedua tabel tersebut direlasikan menggunakan fungsi join dari dplyr, misal di bawah ini digunakan left_join dengan kolom ProductCategoryID sebagai penghubung.
p_cat <- product %>%
left_join(
product_category,
by = 'ProductCategoryID'
)
Sama seperti variabel penampung tabel dan view, variabel hasil relasi juga belum berisi data, pemanggilan variabel pada console hanya akan menampilkan 10 data teratas.
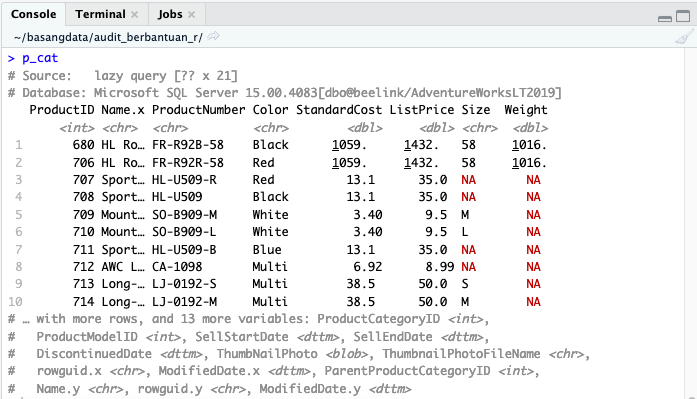
Query
Tugas dbplyr adalah menerjemahkan dialek tidyverse menjadi SQL. Fungsi untuk melihat script SQL yang diproduksi dbplyr adalah show_query().
p_cat %>% show_query()

Ambil Data
Sampai pada titik tertentu kita bosan tak jua punya data untuk dilihat. Fungsi collect() ada untuk menyelesaikan keresahan itu dengan mengambil data dari database ke R.
p_data <- p_cat %>% collect()
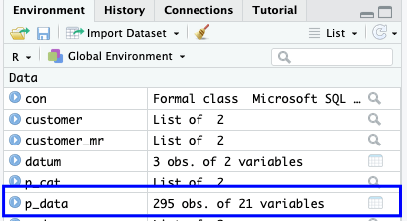
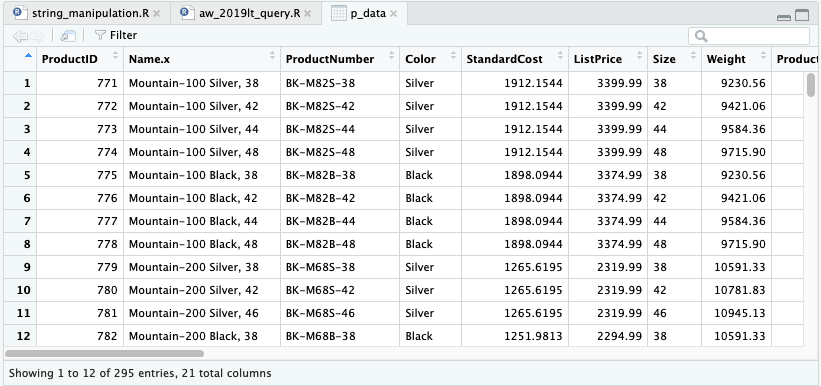
Sebelum mengambil data menggunakan collect() sebaiknya pastikan (komputer) kita sudah siap menangani jumlah data tersebut.
Fungsi Lain
Sebelum mulai mengerjakan soal dari SQLZoo kita dapat beranjangsana ke halaman ini untuk mengetahui fungsi-fungsi apa saja yang disediakan oleh dbplyr agar makin lengkap khasanah yang dimiliki.
Raw SQL
Bagi sesiapa yang ingin menggunakan SQL langsung dan mengambil data dapat menggunakan fungsi dbGetQuery dari package DBI. Meski bukan fungsi dari dbplyr namun menurut penulis dbGetQuery patut disebutkan mengingat DBI terlanjur digunakan dan kemudahan yang didapatkan.
Kemudahannya antara lain satu kode untuk memilih dan mendapat data; kepastian query SQL yang akan dikirimkan ke database; dan eksekusi query kompleks yang sudah dimiliki.
Sebagai ilustrasi, berikut kode untuk mendapatkan data dari relasi tabel Product dan ProductCategory.
raw_sql <- dbGetQuery(con, "SELECT p.ProductID, p.Name, p.ProductCategoryID,
pc.Name AS Category_Name FROM SalesLT.Product p LEFT JOIN
SalesLT.ProductCategory pc ON p.ProductCategoryID = pc.ProductCategoryID")
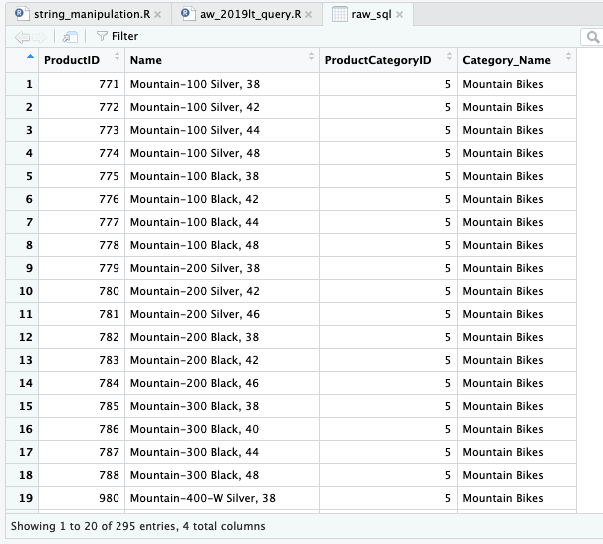
Jawaban Pertanyaan SQLZoo
Variabel Koneksi dan Tabel
Di bagian awal kode, kita membuat variabel untuk masing-masing tabel. Variabel ini yang akan digunakan pada proses selanjutnya.
library(DBI)
library(tidyverse)
con <- dbConnect(odbc::odbc(),
driver = 'ODBC Driver 17 for SQL Server',
server = 'localhost',
database = 'AdventureWorksLT2019',
UID = 'sa',
PWD = 'pwd')
aw_customer <- con %>%
tbl(dbplyr::in_schema('SalesLT', 'Customer'))
aw_address <- con %>%
tbl(dbplyr::in_schema('SalesLT', 'Address'))
aw_customer_address <- con %>%
tbl(dbplyr::in_schema('SalesLT', 'CustomerAddress'))
aw_product <- con %>%
tbl(dbplyr::in_schema('SalesLT', 'Product'))
aw_product_category <- con %>%
tbl(dbplyr::in_schema('SalesLT', 'ProductCategory'))
aw_product_description <- con %>%
tbl(dbplyr::in_schema('SalesLT', 'ProductDescription'))
aw_product_model <- con %>%
tbl(dbplyr::in_schema('SalesLT', 'ProductModel'))
aw_product_model_product_description <- con %>%
tbl(dbplyr::in_schema('SalesLT', 'ProductModelProductDescription'))
aw_sales_order_detail <- con %>%
tbl(dbplyr::in_schema('SalesLT', 'SalesOrderDetail'))
aw_sales_order_header <- con %>%
tbl(dbplyr::in_schema('SalesLT', 'SalesOrderHeader'))
aw_all_categories <- con %>%
tbl(dbplyr::in_schema('SalesLT', 'vGetAllCategories'))
aw_product_and_description <- con %>%
tbl(dbplyr::in_schema('SalesLT', 'vProductAndDescription'))
aw_product_model_catalog_description <- con %>%
tbl(dbplyr::in_schema('SalesLT', 'vProductModelCatalogDescription'))
Mudah
Pertanyaan ke-1
Show the first name and the email address of customer with CompanyName ‘Bike World’
q1 <- aw_customer %>%
filter(CompanyName == 'Bike World') %>%
select(FirstName, EmailAddress) %>%
collect()
q1d <- dbGetQuery(con, "SELECT FirstName, EmailAddress
FROM SalesLT.Customer WHERE CompanyName = 'Bike World'")

Variabel q1 menggunakan dialek tidyverse sedang q1d menggunakan raw SQL melalui dbGetQuery, hasilnya saja sama. Pembaca dari dunia tidyverse mungkin merasa q1 lebih intuitif, yang berangkat dari SQL bisa jadi merasa q1d lebih mudah dimengerti.
Bagian raw SQL akan tetap ditampilkan sebagai pembanding namun pembahasan hanya akan dilakukan pada dialek tidyverse.
Untuk mendapatkan informasi first name dan email address pelanggan dengan nama perusahaan Bike World, variabel q1 pada bagian pertama memanggil variabel aw_customer (yang menampung tabel Customer), kemudian memfilter hanya jika kolom CompanyName berisi data Bike World. Selanjutnya dipilih hanya kolom FirstName dan EmailAddress (untuk ditampilkan) dan data diambil menggunakan fungsi collect().
Pertanyaan ke-2
Show the first CompanyName for all customers with an address in City ‘Dallas’
q2 <- aw_customer %>%
select(CustomerID, CompanyName) %>%
left_join(
aw_customer_address %>%
select(CustomerID, AddressID),
by = 'CustomerID'
) %>%
left_join(
aw_address %>%
select(AddressID, City)
) %>%
filter(
City == 'Dallas'
) %>%
select(-c(CustomerID, AddressID, City)) %>%
arrange(CompanyName) %>%
collect()
q2d <- dbGetQuery(con,
"SELECT cc.CompanyName FROM SalesLT.Address a
LEFT JOIN SalesLT.CustomerAddress c ON a.AddressID = c.AddressID
LEFT JOIN SalesLT.Customer cc ON c.CustomerID = cc.CustomerID
WHERE a.City = 'Dallas' ORDER BY cc.CompanyName")
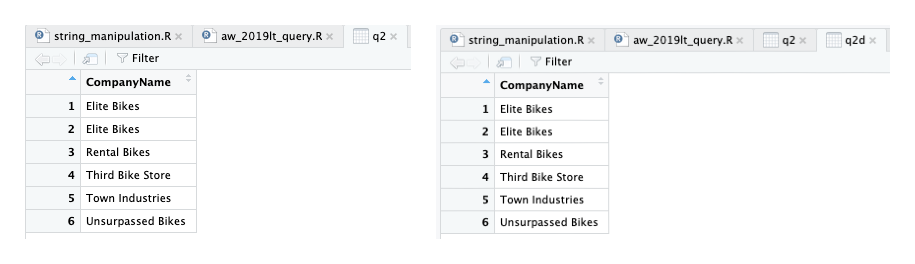
Meski masih merupakan kategori soal mudah, soalan kedua ini mulai memerlukan relasi pada lebih dari dua tabel sehingga kode yang diperlukan makin panjang.
Untuk penulis yang menarik adalah bagian join dimana kita punya kendali atas tabel yang akan dijoin. Di bawah ini join dilakukan pada tabel CustomerAddress, yang dipilih hanya pada kolom CustomerID dan AddressID.
left_join(
aw_customer_address %>%
select(CustomerID, AddressID),
by = 'CustomerID'
) %>%
Kebebasan menggunakan pipa %>% pada join membuat skenario join menjadi tak terbatas. Ini semacam subquery pada SQL, bedanya lebih mudah dicerna, setydacknya menurut penulis.
Kode di atas perlu belasan baris. Untuk kepentingan belajar, jika terasa membingungkan dapat dipotong-potong per pipa dan ditampilkan data yang ada.
Pipa 0
q2 <- aw_customer
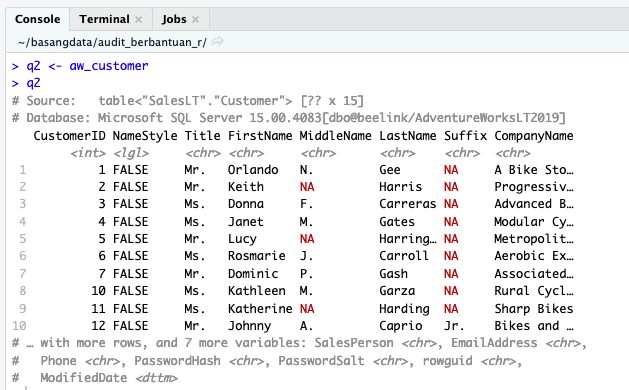
Variabel q2 menampung tabel Customer sebagaimana adanya.
Pipa 1
q2 <- aw_customer %>% select(CustomerID, CompanyName)
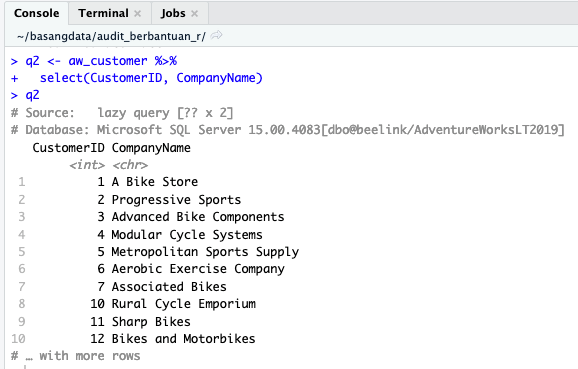
Pada pipa pertama ini fungsi select digunakan untuk memilih hanya dua kolom yang akan diperlukan untuk proses selanjutnya.
Pipa 2
q2 <- aw_customer %>%
select(CustomerID, CompanyName) %>%
left_join(
aw_customer_address %>%
select(CustomerID, AddressID),
by = 'CustomerID'
)
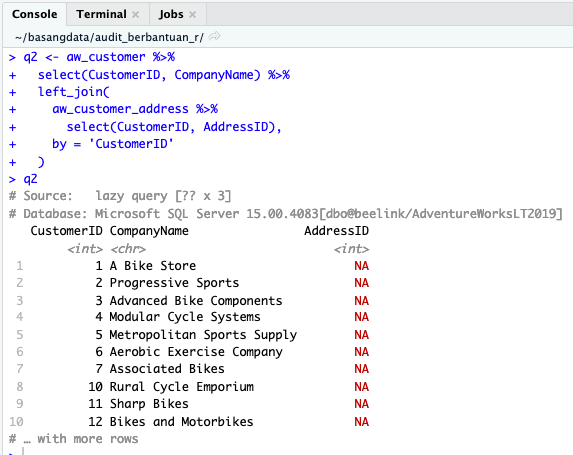
Pada tabel CustomerAddress hanya dipilih kolom CustomerID dan AddressID. Saat tabel tersebut direlasikan dengan tabel Customer (diwakili variabel aw_customer). Setelah berelasi, kolom CustomerID hanya ditampilkan sekali, yang berasal dari tabel Customer, sehingga hanya terdapat tiga kolom yang ditampilkan.
Pipa 3
q2 <- aw_customer %>%
select(CustomerID, CompanyName) %>%
left_join(
aw_customer_address %>%
select(CustomerID, AddressID),
by = 'CustomerID'
) %>%
left_join(
aw_address %>%
select(AddressID, City)
)
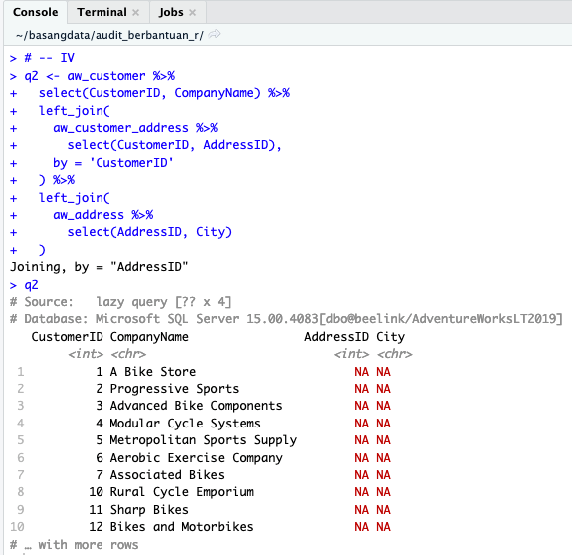
Hasil dari proses sebelumnya direlasikan dengan tabel Address karena nama kota ada di tabel ini.
Pipa 4
q2 <- aw_customer %>%
select(CustomerID, CompanyName) %>%
left_join(
aw_customer_address %>%
select(CustomerID, AddressID),
by = 'CustomerID'
) %>%
left_join(
aw_address %>%
select(AddressID, City)
) %>%
filter(
City == 'Dallas'
)
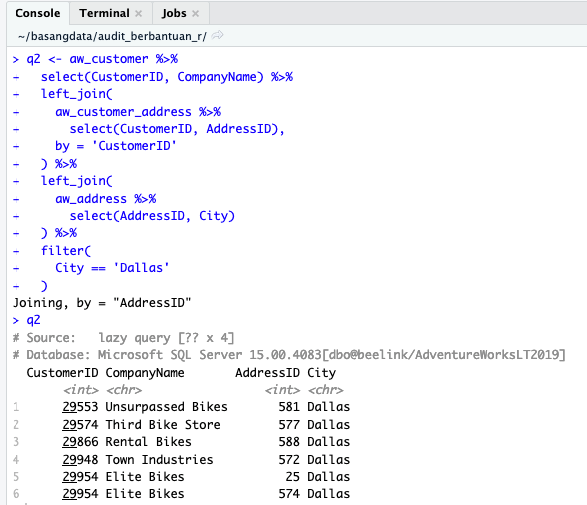
Setelah pipa ke-4 ini hasil dari proses sebelumnya disaring hanya jika kolom City berisi kata Dallas. Sampai di sini sebenarnya kita sudah mendapatkan hasil yang diperlukan.
Pipa 5
q2 <- aw_customer %>%
select(CustomerID, CompanyName) %>%
left_join(
aw_customer_address %>%
select(CustomerID, AddressID),
by = 'CustomerID'
) %>%
left_join(
aw_address %>%
select(AddressID, City)
) %>%
filter(
City == 'Dallas'
) %>%
select(-c(CustomerID, AddressID, City))
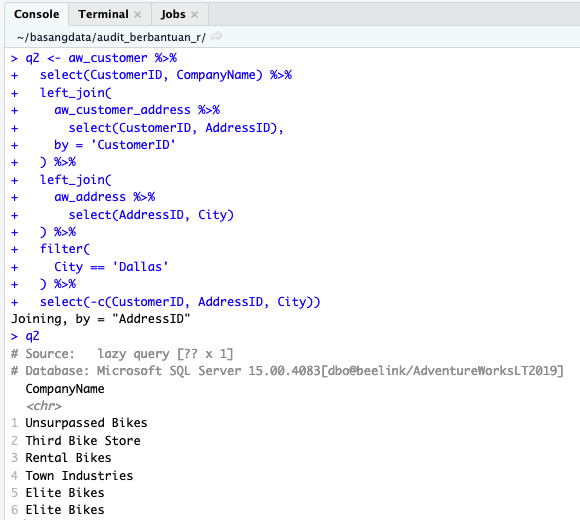
Agar lebih fokus, kolom CustomerID, AddressID dan City tidak ditampilkan.
Pipa 6
q2 <- aw_customer %>%
select(CustomerID, CompanyName) %>%
left_join(
aw_customer_address %>%
select(CustomerID, AddressID),
by = 'CustomerID'
) %>%
left_join(
aw_address %>%
select(AddressID, City)
) %>%
filter(
City == 'Dallas'
) %>%
select(-c(CustomerID, AddressID, City)) %>%
arrange(CompanyName)
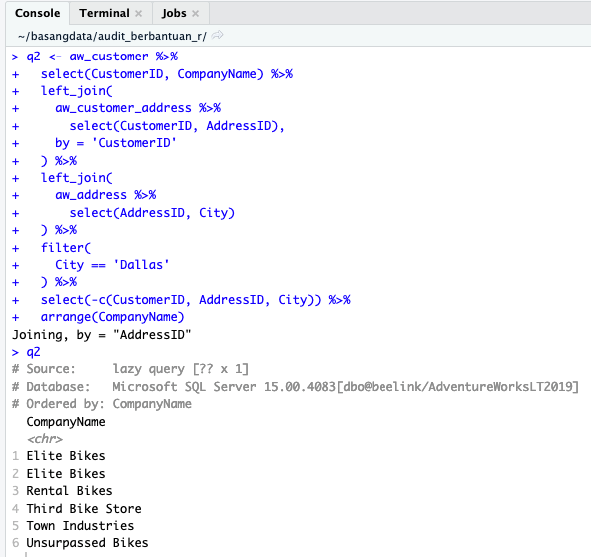
Agar lebih informatif, kolom CompanyName diurutkan menggunakan fungsi arrange().
Pipa 7
q2 <- aw_customer %>%
select(CustomerID, CompanyName) %>%
left_join(
aw_customer_address %>%
select(CustomerID, AddressID),
by = 'CustomerID'
) %>%
left_join(
aw_address %>%
select(AddressID, City)
) %>%
filter(
City == 'Dallas'
) %>%
select(-c(CustomerID, AddressID, City)) %>%
arrange(CompanyName) %>%
collect()

Di pipa terakhir digunakan fungsi collect untuk menarik data dan menyimpannya pada variabel q2.
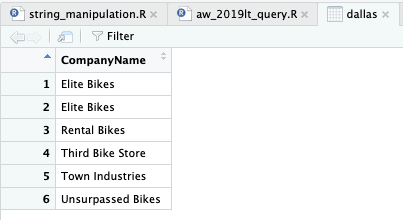
Sebagai pengingat, selalu ada banyak ragam cara untuk mencapai sesuatu. Dalam hal ini, berikut salah satu alternatif yang dapat digunakan untuk mendapatkan daftar perusahaan berdomisili di Dallas.
dallas <- aw_address %>%
filter(City == 'Dallas') %>%
left_join(
aw_customer_address,
by = "AddressID") %>%
left_join(
aw_customer,
by = "CustomerID"
) %>%
select(CompanyName) %>%
arrange(CompanyName) %>%
collect()
Pertanyaan ke-3
How many items with ListPrice more than $1000 have been sold?
Ada orang yang bilang “tau permasalahan jauh lebih penting dari tau solusinya”. Pertanyaan ke-3 ini adalah salah satu bahan renungan pernyataan orang itu.
Berapa banyak item yang ditanyakan ini mangsudnya berapa jumlah total produk terjual atau berapa jenis produk yang terjual. Jika produk A terjual sebanyak 3 dan produk B terjual 2, maka jawaban mangsud pertama adalah 5. Bila yang benar adalah mangsud ke dua, maka jawabannya adalah 2.
Apatah ini adalah permasalahan lost in translation? Untuk sementara kita cukupkan dua interpretasi saja.
Skenario pertama, jika yang ditanyakan jumlah total produk terjual, dengan syarat harga masing-masing produk melebihi $1.000.
q3a<- aw_product %>% filter(ListPrice > 1000) %>% inner_join(aw_sales_order_detail, by = "ProductID") %>% summarise(sum = sum(OrderQty, na.rm=TRUE)) %>% collect() q3ad <- dbGetQuery(con, "SELECT SUM(s.OrderQty) FROM SalesLT.Product p INNER JOIN SalesLT.SalesOrderDetail s ON p.ProductID = s.ProductID WHERE p.ListPrice > 1000;")

Yang berbeda pada kode di atas dengan kode-kode sebelumnya adalah penggunaan fungsi summarise dan sum untuk mendapatkan jumlah total produk yang terjual. Parameter na.rm = TRUE digunakan untuk memastikan baris data berisi NA tidak ikut diproses, toh tidak berarti dalam proses penambahan.
Skenario kedua jika hanya ingin mengetahui berapa jenis produk terjual maka kode di bawah ini yang digunakan.
q3b <- aw_product %>% filter(ListPrice > 1000) %>% inner_join(aw_sales_order_detail, by = "ProductID") %>% summarise(total = n()) %>% collect() product_exp4 <- dbGetQuery(con, "SELECT COUNT(*) FROM SalesLT.Product p INNER JOIN SalesLT.SalesOrderDetail s ON p.ProductID = s.ProductID WHERE p.ListPrice > 1000;")

Fungsi n() digunakan untuk mendapatkan berapa banyak (baris) data yang ada, ekuivalen dengan COUNT pada SQL.
Seperti terlihat, skenario, terjemahan pertanyaan, pertama menghasilkan 508 sedangkan skenario kedua 144. Ini jenis pertanyaan yang baik (atau tidak, tergantung berapa banyak waktu yang kita punya untuk memikirkannya) karena terbuka pada lebih dari satu pilihan jawaban.
Pertanyaan ke-4
Give the CompanyName of those customers with orders over $100000. Include the subtotal plus tax plus freight
q4 <- aw_customer %>% left_join(aw_sales_order_header, by = 'CustomerID') %>% filter((SubTotal + TaxAmt + Freight) > 100000) %>% select(CompanyName) %>% collect() q4d <- dbGetQuery(con, 'SELECT Customer.CompanyName FROM SalesLT.SalesOrderHeader JOIN SalesLT.Customer ON SalesOrderHeader.CustomerID = Customer.CustomerID WHERE SalesOrderHeader.SubTotal + SalesOrderHeader.TaxAmt + SalesOrderHeader.Freight > 100000;')

Pertanyaan ke-5
Find the number of left racing socks (‘Racing Socks, L’) ordered by CompanyName ‘Riding Cycles’
q5 <- aw_sales_order_detail %>%
left_join(aw_sales_order_header, by = 'SalesOrderID') %>%
semi_join(
aw_product %>%
filter(Name == 'Racing Socks, L'),
by = 'ProductID'
) %>%
semi_join(
aw_customer %>%
filter(CompanyName == 'Riding Cycles'),
by = 'CustomerID'
) %>%
select(OrderQty) %>%
collect()
q5d <- dbGetQuery(con, "SELECT SalesOrderDetail.OrderQty
FROM SalesLT.Product JOIN SalesLT.SalesOrderDetail ON Product.ProductID = SalesOrderDetail.ProductID
JOIN SalesLT.SalesOrderHeader ON SalesOrderDetail.SalesOrderID = SalesOrderHeader.SalesOrderID
JOIN SalesLT.Customer ON SalesOrderHeader.CustomerID = Customer.CustomerID
WHERE Product.Name = 'Racing Socks, L' AND Customer.CompanyName = 'Riding Cycles';")

Fungsi semi_join() baru pertama kali digunakan, sejauh ini. Gunanya adalah untuk memfilter berdasarkan keberadaan data di tabel yang direlasikan. Seperti mengatakan tampilkan semua data pada tabel A jika data itu ADA di tabel B. Untuk kebutuhan tampilkan semua data pada tabel A jika data itu TIDAK ADA di tabel B, gunakan fungsi anti_join().
Untuk memvisualkan, kita potong kode di atas per pipa.
Pipa 1
q5 <- aw_sales_order_detail %>% left_join(aw_sales_order_header, by = 'SalesOrderID')
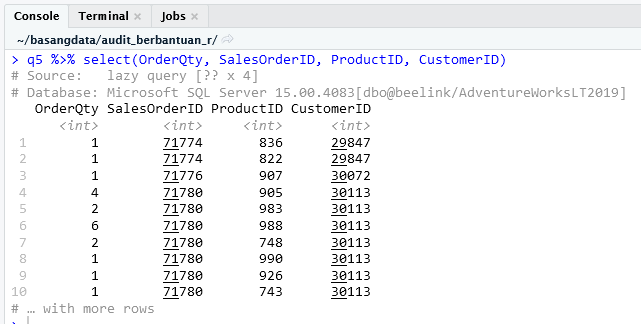
Di bagian ini tabel SalesOrderDetail dihubungkan dengan tabel SalesOrderHeader menggunakan kolom SalesOrderID. Hasilnya banyak, lebih dari 10 baris.
Pipa 2
q5 <- aw_sales_order_detail %>%
left_join(aw_sales_order_header, by = 'SalesOrderID') %>%
semi_join(
aw_product %>%
filter(Name == 'Racing Socks, L'),
by = 'ProductID'
)
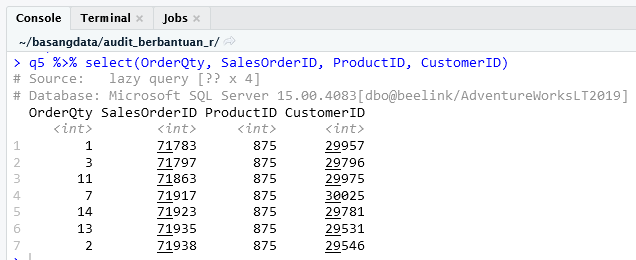
Dari tabel Product saring yang bernama Racing Socks, L, hasilnya digunakan sebagai saringan bagi data dari pipa 1. Jika ProductID hasil dari pipa 1 ada pada tabel Product, yang sudah disaring, maka tampilkan. Di titik ini kita punya 7 data.
Pipa 3
q5 <- aw_sales_order_detail %>%
left_join(aw_sales_order_header, by = 'SalesOrderID') %>%
semi_join(
aw_product %>%
filter(Name == 'Racing Socks, L'),
by = 'ProductID'
) %>%
semi_join(
aw_customer %>%
filter(CompanyName == 'Riding Cycles'),
by = 'CustomerID'
)
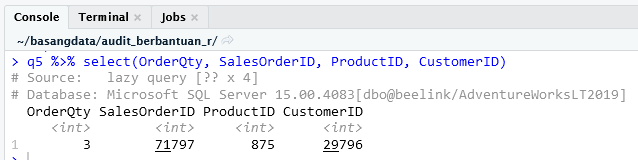
Pada tabel Customer hanya tampilkan jika CompanyName adalah “Riding Cycles“. Hasil saringan itu digunakan sebagai filter bagi data dari pipa 2. Sekarang kita hanya tinggal punya 1 data.
Penggunaan semi_join hanyalah satu alternatif, kita tetap bisa menempuh jalur “sederhana” dengan merelasikan beberapa tabel, kemudian memfilter hasil relasi tersebut.
Sedang
Pertanyaan ke-6
A “Single Item Order” is a customer order where only one item is ordered. Show the SalesOrderID and the UnitPrice for every Single Item Order.
q6 <- aw_sales_order_detail %>% group_by(SalesOrderID) %>% filter(n() == 1) %>% select(SalesOrderID, UnitPrice) %>% collect() q6d <- dbGetQuery(con, 'SELECT MAX(s.salesOrderID) as salesOrderId, MAX(s.UnitPrice) as UnitPrice FROM SalesLT.SalesOrderDetail s GROUP BY s.SalesOrderID HAVING COUNT(*) = 1;')
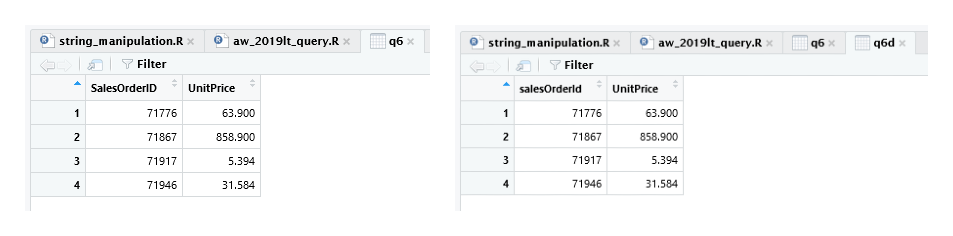
Fungsi group_by() baru digunakan di sini, gunanya untuk, apalagi kalau bukan, mengelompokkan berdasarkan kolom tertentu.
Pertanyaan ke-7
Where did the racing socks go? List the product name and the CompanyName for all Customers who ordered ProductModel ‘Racing Socks’.
q7 <- aw_sales_order_detail %>%
left_join(select(aw_product, Name, ProductID, ProductModelID), by = 'ProductID') %>%
semi_join(aw_product_model %>%
filter(Name == 'Racing Socks'), by = 'ProductModelID') %>%
left_join(select(aw_sales_order_header, SalesOrderID, CustomerID), by = 'SalesOrderID') %>%
left_join(select(aw_customer, CompanyName, CustomerID), by = 'CustomerID') %>%
select(Name, CompanyName) %>%
collect()
q7d <- dbGetQuery(con, "SELECT
Product.name, Customer.CompanyName
FROM
SalesLT.ProductModel
JOIN
SalesLT.Product
ON ProductModel.ProductModelID = Product.ProductModelID
JOIN
SalesLT.SalesOrderDetail
ON SalesOrderDetail.ProductID = Product.ProductID
JOIN
SalesLT.SalesOrderHeader
ON SalesOrderDetail.SalesOrderID = SalesOrderHeader.SalesOrderID
JOIN
SalesLT.Customer
ON SalesOrderHeader.CustomerID = Customer.CustomerID
WHERE
ProductModel.Name = 'Racing Socks';")
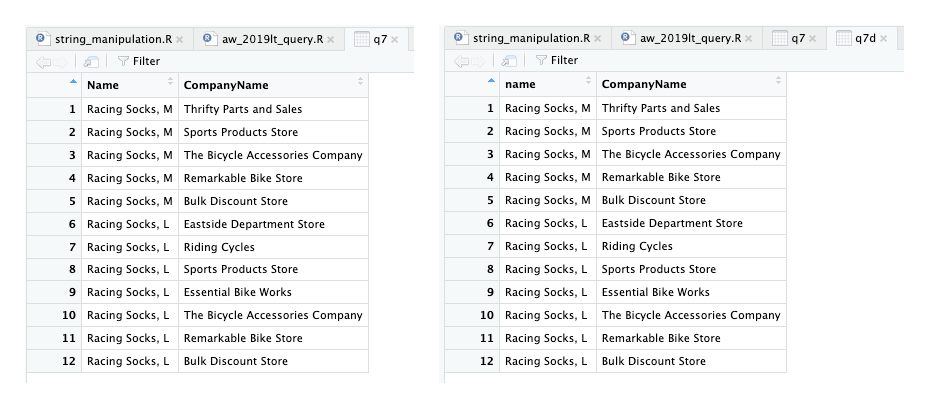
Fungsi select() digunakan secara berbeda di sini. Cara penggunaan yang banal adalah data %>% select(kolom1, kolom2). Sebenarnya fungsi ini memungkinkan digunakan dengan urutan pemanggilan select(data, kolom1, kolom2). Keuntungan dari cara kedua adalah lebih sedikit kode yang perlu diketik dan dalam kasus ini kode dapat dibuat menjadi satu baris sehingga lebih mudah dibaca.
Pertanyaan ke-8
Show the product description for culture ‘fr’ for product with ProductID 736.
q8 <- aw_product_description %>%
left_join(select(aw_product_model_product_description, Culture, ProductDescriptionID, ProductModelID), by = 'ProductDescriptionID') %>%
left_join(select(aw_product, ProductModelID, ProductID), by = 'ProductModelID') %>%
filter(
Culture == 'fr',
ProductID == 736
) %>%
select(Description) %>%
collect()
q8d <- dbGetQuery(con, 'SELECT
ProductDescription.Description
FROM
SalesLT.ProductDescription
JOIN
SalesLT.ProductModelProductDescription
ON ProductDescription.ProductDescriptionID = ProductModelProductDescription.ProductDescriptionID
JOIN
SalesLT.ProductModel
ON ProductModelProductDescription.ProductModelID = ProductModel.ProductModelID
JOIN
SalesLT.Product
ON ProductModel.ProductModelID = Product.ProductModelID
WHERE
ProductModelProductDescription.culture = \'fr\'
AND Product.ProductID = \'736\';')

Pertanyaan ke-9
Use the SubTotal value in SaleOrderHeader to list orders from the largest to the smallest. For each order show the CompanyName and the SubTotal and the total weight of the order.
q9a <- aw_sales_order_detail %>%
left_join(select(aw_product, ProductID, Weight), by = 'ProductID') %>%
left_join(select(aw_sales_order_header, SalesOrderID, CustomerID, SubTotal), by = 'SalesOrderID') %>%
left_join(select(aw_customer, CustomerID, CompanyName)) %>%
mutate(TotalWeight = Weight * OrderQty) %>%
group_by(SalesOrderID, SubTotal, CompanyName) %>%
summarise(total_weight = sum(TotalWeight)) %>%
ungroup() %>%
select(CompanyName, SubTotal, total_weight) %>%
arrange(desc(SubTotal)) %>%
collect()
q9b <- aw_sales_order_detail %>%
left_join(select(aw_product, ProductID, Weight), by = 'ProductID') %>%
left_join(select(aw_sales_order_header, SalesOrderID, CustomerID, SubTotal), by = 'SalesOrderID') %>%
mutate(TotalWeight = Weight * OrderQty) %>%
group_by(SalesOrderID, SubTotal, CustomerID) %>%
summarise(total_weight = sum(TotalWeight)) %>%
left_join(select(aw_customer, CustomerID, CompanyName)) %>%
arrange(desc(SubTotal)) %>%
ungroup() %>%
select(CompanyName, SubTotal, total_weight) %>%
collect()
q9d <- dbGetQuery(con, 'SELECT
Customer.CompanyName,
SalesOrderHeader.SubTotal,
SUM(SalesOrderDetail.OrderQty * Product.weight)
FROM
SalesLT.Product
JOIN
SalesLT.SalesOrderDetail
ON Product.ProductID = SalesOrderDetail.ProductID
JOIN
SalesLT.SalesOrderHeader
ON SalesOrderDetail.SalesOrderID = SalesOrderHeader.SalesorderID
JOIN
SalesLT.Customer
ON SalesOrderHeader.CustomerID = Customer.CustomerID
GROUP BY
SalesLT.SalesOrderHeader.SalesOrderID, SalesOrderHeader.SubTotal, Customer.CompanyName
ORDER BY
SalesLT.SalesOrderHeader.SubTotal DESC;')
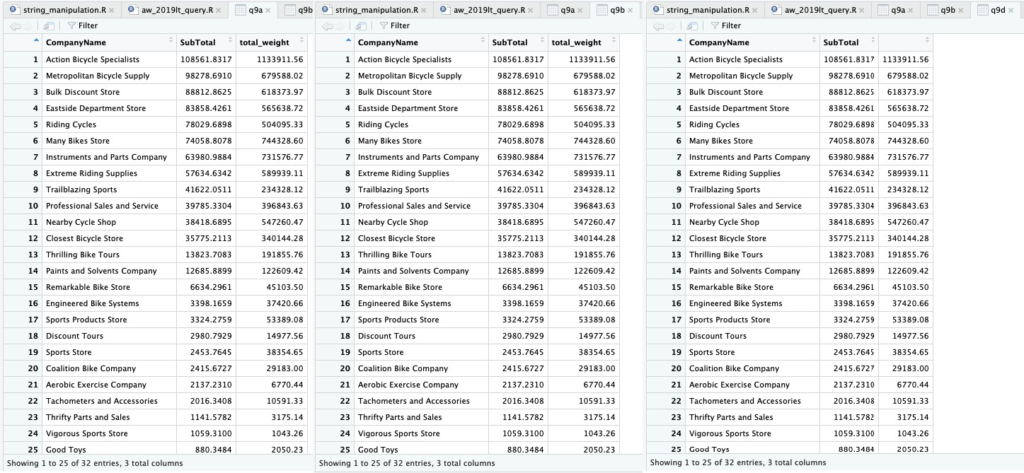
Kita punya 2 pendekatan di sini, hasilnya sama. Dari sisi dialek, yang baru digunakan adalah mutate() untuk membuat kolom baru berdasarkan kolom-kolom yang ada.
Fungsi ungroup() digunakan untuk, apalagi kalau bukan, mentidakkelompokkan data. Fungsi ungroup kadang diperlukan jika masih perlu memproses data setelah dikelompokkan. Pada kode di atas, jika tidak menggunakan ungroup maka kita akan kesulitan mengatur kolom yang akan ditampilkan.
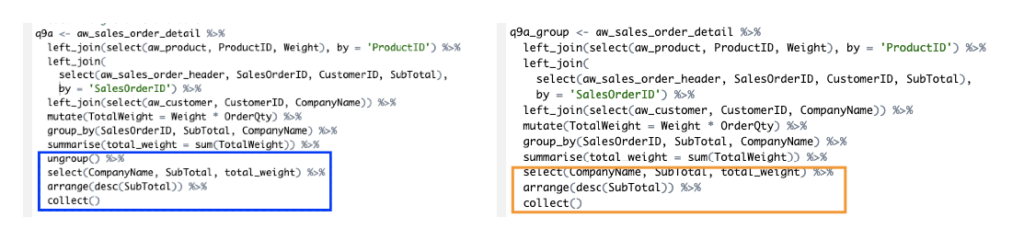
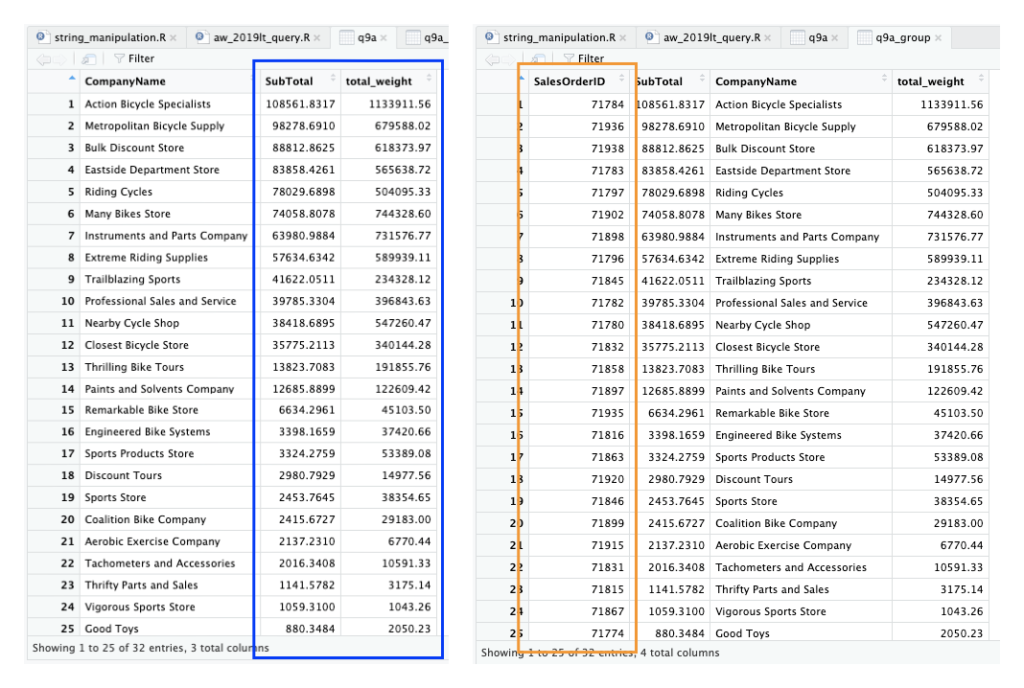
Fungsi desc() digunakan di dalam arrange() untuk mengurutkan dari belakang.
Pertanyaan ke-10
How many products in ProductCategory ‘Cranksets’ have been sold to an address in ‘London’?
q10 <- select(aw_sales_order_detail, ProductID, SalesOrderID, OrderQty) %>%
left_join(
select(aw_sales_order_header, SalesOrderID, ShipToAddressID),
by = 'SalesOrderID') %>%
left_join(
select(aw_address, AddressID, City),
by = c('ShipToAddressID' = 'AddressID')
) %>%
left_join(
select(aw_product, ProductID, ProductCategoryID),
by = 'ProductID'
) %>%
left_join(
select(aw_product_category, ProductCategoryID, Name),
by = 'ProductCategoryID'
) %>%
filter(
Name == 'Cranksets',
City == 'London'
) %>%
summarise(total = sum(OrderQty)) %>%
collect()
q10d <- dbGetQuery(con, "SELECT
SUM(SalesOrderDetail.OrderQty) AS total
FROM
SalesLT.ProductCategory
JOIN
SalesLT.Product
ON ProductCategory.ProductCategoryID = Product.ProductCategoryID
JOIN
SalesLT.SalesOrderDetail
ON Product.ProductID = SalesOrderDetail.ProductID
JOIN
SalesLT.SalesOrderHeader
ON SalesOrderDetail.SalesOrderID = SalesOrderHeader.SalesorderID
JOIN
SalesLT.Address
ON SalesOrderHeader.ShipToAddressID = Address.AddressID
WHERE
SalesLT.Address.City = 'London'
AND SalesLT.ProductCategory.Name = 'Cranksets';")

Sulit
Pertanyaan ke-11
For every customer with a ‘Main Office’ in Dallas show AddressLine1 of the ‘Main Office’ and AddressLine1 of the ‘Shipping’ address – if there is no shipping address leave it blank. Use one row per customer.
q11 <- select(aw_customer, CustomerID, CompanyName) %>%
left_join(
select(aw_customer_address, CustomerID, AddressID, AddressType),
by = 'CustomerID') %>%
left_join(
select(aw_address, AddressID, City, AddressLine1),
by = 'AddressID'
) %>%
filter(
AddressType == 'Main Office',
City == 'Dallas'
) %>%
left_join(
aw_customer_address %>%
rename(AddressIDShipping = AddressID) %>%
filter(
AddressType == 'Shipping'
) %>%
select(AddressIDShipping, CustomerID),
by = 'CustomerID'
) %>%
left_join(
aw_address %>%
rename(AddressLine1Shipping = AddressLine1) %>%
select(AddressID, AddressLine1Shipping),
by = c('AddressIDShipping' = 'AddressID')
) %>%
select(CompanyName, AddressLine1, AddressLine1Shipping) %>%
arrange(CompanyName) %>%
collect()
q11d <- dbGetQuery(con, "SELECT
Customer.CompanyName,
MAX(CASE WHEN AddressType = 'Main Office' THEN AddressLine1 ELSE '\' END) AS 'Main Office Address',
MAX(CASE WHEN AddressType = 'Shipping' THEN AddressLine1 ELSE '\' END) AS 'Shipping Address'
FROM
SalesLT.Customer
JOIN
SalesLT.CustomerAddress
ON Customer.CustomerID = CustomerAddress.CustomerID
JOIN
SalesLT.Address
ON CustomerAddress.AddressID = Address.AddressID
WHERE
Address.City = 'Dallas'
GROUP BY
Customer.CompanyName;")

Di sini kita melihat kemudahan yang ditawarkan oleh pipa %>% di dalam join. Bermacam hal bisa dilakukan pada tabel CustomerAddress, sebelum diproses pada data lain. Fungsi rename() digunakan untuk merubah nama kolom, data (pada tabel CustomerAddress) disaring, kemudian dipilih hanya kolom AddressIDShipping dan CustomerID.
%>%
left_join(
aw_customer_address %>%
rename(AddressIDShipping = AddressID) %>%
filter(
AddressType == 'Shipping'
) %>%
select(AddressIDShipping, CustomerID),
by = 'CustomerID'
)
Pertanyaan ke-12
For each order show the SalesOrderID and SubTotal calculated three ways:
1. From the SalesOrderHeader
2. Sum of OrderQty * UnitPrice
3. Sum of OrderQty * ListPrice
q12 <- aw_sales_order_header %>%
select(SalesOrderID, SubTotal) %>%
rename(SubTotal_from_Header = SubTotal) %>%
left_join(
aw_sales_order_detail %>%
select(SalesOrderID, OrderQty, UnitPrice) %>%
mutate(SubTotalDetail = OrderQty * UnitPrice) %>%
group_by(SalesOrderID) %>%
summarise(SubTotal_from_Detail = sum(SubTotalDetail)),
by = 'SalesOrderID'
) %>%
left_join(
aw_sales_order_detail %>%
select(SalesOrderID, OrderQty, ProductID) %>%
left_join(
aw_product %>%
select(ProductID, ListPrice),
by = 'ProductID'
) %>%
mutate(SubTotalProduct = OrderQty * ListPrice) %>%
group_by(SalesOrderID) %>%
summarise(SubTotal_from_Product = sum(SubTotalProduct)),
by = 'SalesOrderID'
) %>%
collect()
q12 %>% db_show()
q12d <- dbGetQuery(con, 'SELECT
SalesOrderHeader.SalesOrderID,
SalesOrderHeader.SubTotal,
SUM(SalesOrderDetail.OrderQty * SalesOrderDetail.UnitPrice) AS SubTotalDetail,
SUM(SalesOrderDetail.OrderQty * Product.ListPrice) AS SubTotalProduct
FROM
SalesLT.SalesOrderHeader
JOIN
SalesLT.SalesOrderDetail
ON SalesOrderHeader.SalesOrderID = SalesOrderDetail.SalesOrderID
JOIN
SalesLT.Product
ON SalesOrderDetail.ProductID = Product.ProductID
GROUP BY
SalesOrderHeader.SalesOrderID,
SalesOrderHeader.SubTotal;')
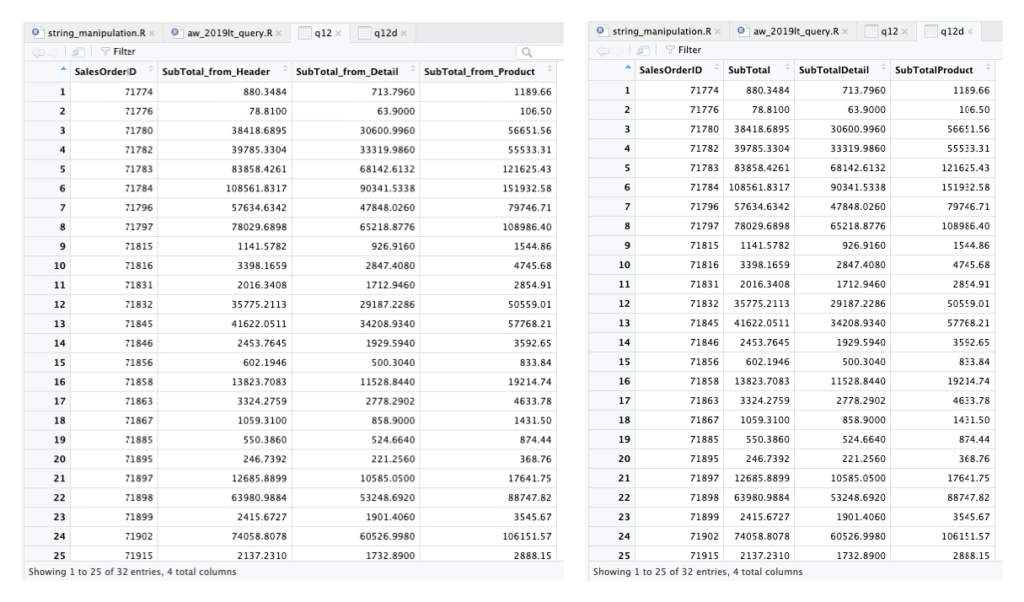
Pertanyaan ke-13
Show the best selling item by value.
q13 <- aw_sales_order_detail %>%
select(ProductID, OrderQty, UnitPrice) %>%
mutate(SubTotal = OrderQty * UnitPrice) %>%
left_join(
aw_product %>%
select(ProductID, Name),
by = 'ProductID'
) %>%
group_by(ProductID, Name) %>%
summarise(Value = sum(SubTotal)) %>%
ungroup() %>%
select(Name, Value) %>%
arrange(desc(Value)) %>%
collect()
q13d <- dbGetQuery(con, 'SELECT
Product.Name,
SUM(SalesOrderDetail.OrderQty * SalesOrderDetail.UnitPrice) AS Total_Sale_Value
FROM
SalesLT.Product
JOIN
SalesLT.SalesOrderDetail
ON Product.ProductID = SalesOrderDetail.ProductID
GROUP BY
Product.Name
ORDER BY
Total_Sale_Value DESC;')
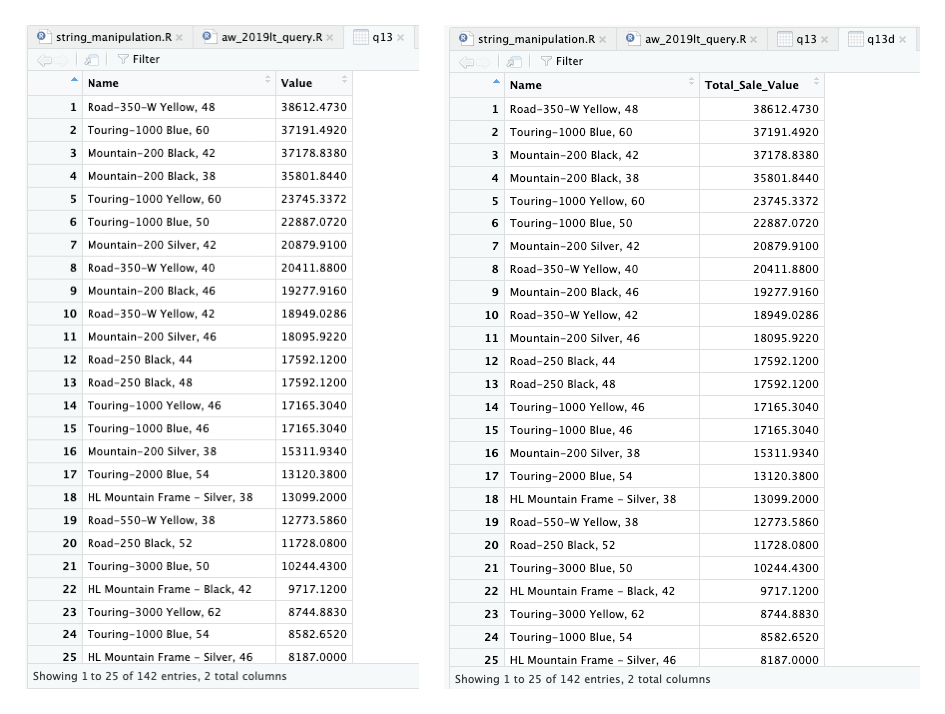
Pertanyaan ke-14
Show how many orders are in the following ranges (in $):
q14 <- aw_sales_order_header %>%
select(SalesOrderID, SubTotal) %>%
mutate(Range = case_when(
SubTotal < 100 ~ '0 - 99',
SubTotal > 99 & SubTotal < 1000 ~ '100 - 999',
SubTotal > 1000 & SubTotal < 9999 ~ '1000 - 9999',
SubTotal > 10000 ~ '10000 -',
TRUE ~ 'Error'
)) %>%
group_by(Range) %>%
summarise(
Num_Orders = n(),
Total_Value = sum(SubTotal)
) %>%
collect()
q14d <- dbGetQuery(con, "SELECT
t.range AS 'RANGE',
COUNT(t.Total) AS 'Num Orders',
SUM(t.Total) AS 'Total Value'
FROM
(
SELECT
CASE
WHEN
SalesOrderHeader.SubTotal BETWEEN 0 AND 99
THEN
'0-99'
WHEN
SalesOrderHeader.SubTotal BETWEEN 100 AND 999
THEN
'100-999'
WHEN
SalesOrderHeader.SubTotal BETWEEN 1000 AND 9999
THEN
'1000-9999'
WHEN
SalesOrderHeader.SubTotal > 10000
THEN
'10000-'
ELSE
'Error'
END AS 'Range',
SalesOrderHeader.SubTotal AS Total
FROM
SalesLT.SalesOrderHeader
) t
GROUP BY
t.range;")
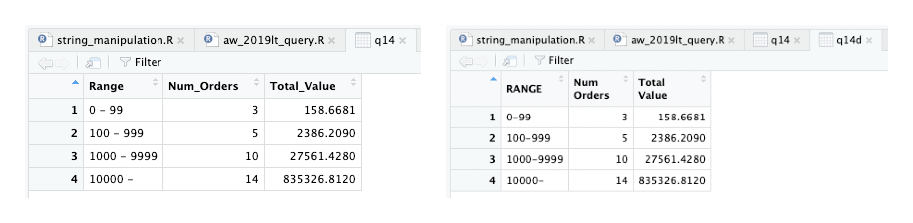
Pada fungsi mutate terdapat fungsi case_when() untuk membuat kolom baru berdasarkan pelbagai kriteria.
Yang perlu diingat adalah tidak semua fungsi di R dapat dieksekusi (diubah menjadi SQL) oleh dtplyr.
Pertanyaan ke-15
Identify the three most important cities. Show the break down of top level product category against city.
Penulis gagal memahami pertanyaan yang diajukan. Sekian.
Simpulan
Melalui dbplyr, pengguna tidyverse dimanjakan (lagi) saat mengelola data dari database. Selain kode untuk membuat koneksi, tidak ada hal yang perlu dipelajari khusus, selama sudah terbiasa dengan dialek dplyr (tidyverse).
Cukup banyak fungsi di R (baik fungsi dari base R maupun fungsi dari package) yang dapat diterjemahkan menjadi SQL oleh dbplyr namun kita tak perlu terkejut jika ada (banyak) fungsi yang sebaliknya. Yang perlu dilakukan hanya mencari padanan kode untuk fungsi-fungsi tersebut.
Langganan dan Saran
Jika suka tulisan di sini boleh berlangganan agar kami dapat mengirimkan pemberitahuan tulisan baru. Punya saran atau keluhan terhadap blog ini, sila ajukan langsung pada kami.
Cover Photo by benjamin lehman on Unsplash
One Reply to “Audit Data Analitics dengan R – Query pada Database”