

Audit Data Analytics dengan R – Mengambil Sampel
Dalam penugasan audit, yang selalu kekurangan sumberdaya seperti tenaga, waktu dan biaya, hampir menjadi hil yang mustahal untuk melakukan pengujian pada seluruh populasi, karena itu audit sampling (mengambil sebagian dari populasi) adalah keniscayaan.
KODE LIMA DETIK
library(DBI)
library(tidyverse)
con <- dbConnect(odbc::odbc(),
driver = 'ODBC Driver 17 for SQL Server',
server = 'localhost',
database = 'AdventureWorks2019',
UID = 'sa',
PWD = 'pwd')
# Get 2013's Sales ----
sales2013 <- sales %>%
filter(year(OrderDate) == 2013) %>%
collect()
# Statistical Sampling ----
## Simple Random Selection ----
simple_random_selection <- sales2013 %>%
sample_n(size = 30)
# Nonstatistical Sampling ----
## Block Sample Selection ----
block_sample <- sales2013 %>%
group_by(months(OrderDate)) %>%
filter(row_number() < 11)
Definisi
Opini auditor adalah simpulan memadai, buah dari bukti audit yang cukup dan tepat. Darimana datangnya bukti audit yang semacam itu? Dari pengujian yang efektif turun ke hati.
Untuk memilih unsur yang mau diuji, Standar Audit (SA) 500 memberikan tiga pilihan cara.
- Memilih semua unsur (pemeriksaan 100%)
- Memilih unsur tertentu
- Sampling audit
Selanjutnya, masih menurut SA 500, sampling audit dirancang agar auditor mampu menarik simpulan mengenai populasi berdasarkan pengujian suatu sampel. Rincian soal sampling audit ada di SA 530.
SA 530 sendiri mendefinisikan sampling audit sebagai:
Penerapan prosedur audit terhadap kurang dari 100% unsur dalam suatu populasi audit yang relevan sedemikian rupa sehingga semua unit sampling memiliki peluang yang sama untuk dipilih untuk memberikan basis memadai bagi auditor untuk menarik kesimpulan tentang populasi secara keseluruhan.
Sesuai definisi, sampling audit hanya “menangani” sebagian (kecil?) dari populasi dan kemudian memproyeksikan kesalahan penyajian yang ditemukan pada sampel ke populasi (paragraf 14 SA 530).
Metode
Lazimnya “buku kuliah” audit mengenalkan dua metode pengambilan sampel yaitu secara statistik dan non-statistik.
- Statistical Sampling
- Simple random sample selection
- Systematic sample selection
- Probability proportional to size and stratified sample selection
- Nonstatistical Sampling
- Haphazard sample selection
- Block sample selection
Kita bahas sedikit masing-masing metode sembari (lebih sedikit lagi) praktek menggunakan R.
Data
Data yang akan digunakan adalah data langganan kita, AdventureWorks. Kali ini yang digunakan adalah AdventureWorks 2019 yang dapat diunduh di sini. Bagaimana merestore ke MS SQL Server adalah di luar cakupan tulisan ini, namun untuk bagaimana cara R terhubung dengan database server dapat merujuk pada tulisan sebelumnya.
Kode di bawah ini digunakan untuk menjalin hubungan dengan database server pada database bernama AdventureWorks2019.
library(DBI)
library(tidyverse)
con <- dbConnect(odbc::odbc(),
driver = 'ODBC Driver 17 for SQL Server',
server = 'localhost',
database = 'AdventureWorks2019',
UID = 'sa',
PWD = 'pwd')
Jika semua lancar, pada pane Connections akan tampil beberapa database yang ada di server.
Yang jika dibuka pada AdventureWorks2019 akan tampil skema dan tabel yang dikandung oleh database ini.
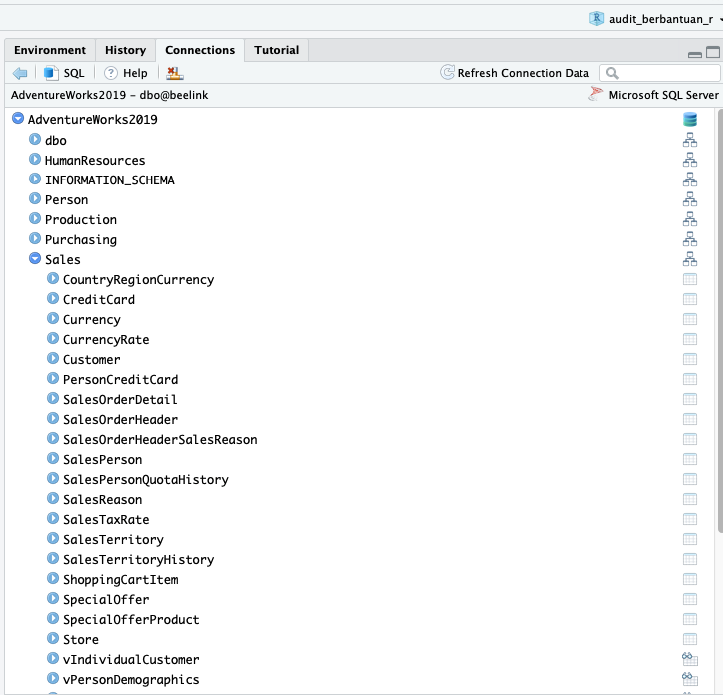
Penjualan
Kali ini kita mendapat penugasan untuk mengaudit penjualan yang dilakukan oleh AdventureWorks, yang ada pada skema Sales khususnya tabel SalesOrderHeader.
Di bawah ini adalah kode untuk mendapatkan data penjualan dari tabel SalesOrderHeader.
sales <- tbl(con, dbplyr::in_schema('Sales', 'SalesOrderHeader'))
Tahun 2013
Tabel SalesOrderHeader memiliki 26 kolom dengan banyak baris.
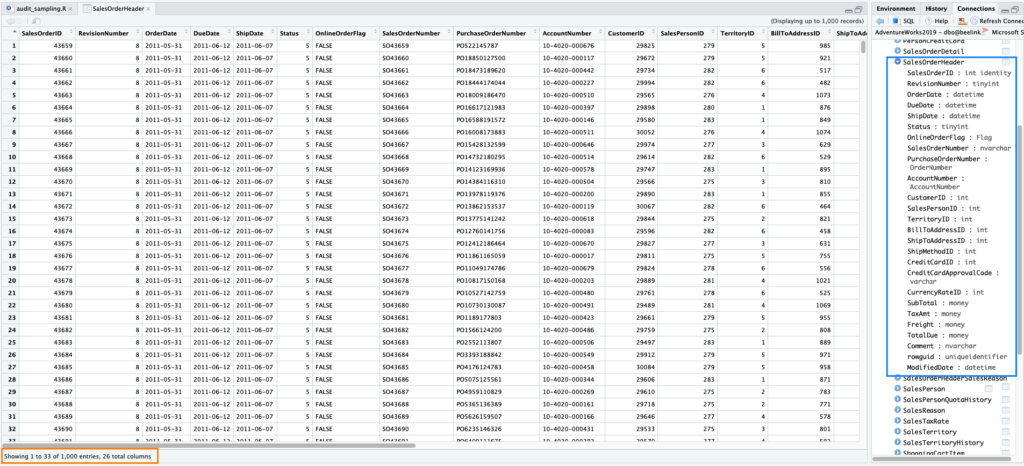
Sesuai kolom OrderDate tabel ini kita tahu data yang termuat adalah dari tahun 2011 sampai 2014 dengan banyak transaksi per masing-masing tahun:
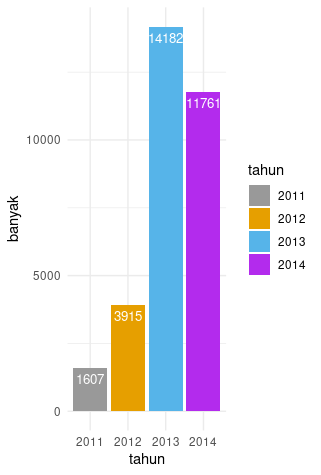
Jika tertarik membuat grafik seperti di atas, kode ini dapat digunakan.
sales_by_year <- sales %>%
count(year(OrderDate)) %>%
collect() %>%
rename(tahun = 1, banyak = 2) %>%
mutate(tahun = as.factor(tahun))
p <- ggplot(data = sales_by_year, aes(x=tahun, y = banyak, fill=tahun)) +
geom_bar(stat = 'identity') +
geom_text(aes(label=banyak), vjust=1.6, color="white", position=position_dodge(0.9), size=3.5) +
theme_minimal() +
scale_fill_manual(values = c("#999999", "#E69F00", "#56B4E9", "#B32BED"))
p
Sales dikelompokkan berdasarkan tahun dan dihitung jumlah transaksi per tahun, ditampung pada variabel sales_by_year.
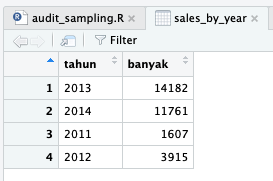
Variabel p adalah grafik yang dibuat menggunakan ggplot2 (bagian dari tidyverse). Kita akan membahas library ini (ggplot2) secara khusus di tulisan-tulisan mendatang.
Tahun finansial yang diaudit adalah 2013. Variabel sales2013 kita gunakan untuk menampung data tersebut.
sales2013 <- sales %>% filter(year(OrderDate) == 2013) %>% collect()
Statistical Sampling
Pendekatan sampling disebut statistical sampling (sampling statistik) jika memiliki karakteristik seperti ini:
- Pemilihan unsur-unsur sampel dilaksanakan secara acak; dan
- Penggunaan teori probabilitas untuk menilai hasil sampel, termasuk untuk mengukur risiko sampling.
Jika tidak memiliki karakteristik di atas maka dianggap sebagai nonstatistical sampling (sampling nonstatistik).
Jika dipikir-pikir, kriteria kedua-lah yang sulit. Karena untuk memilih secara acak kita dapat menyerahkan kepada komputer, misal dengan menggunakan automatic random generation macam fungsi RAND atau RANDBETWEEN pada Ms Excel.
Untuk kriteria kedua, ini lebih berat karena sekurangnya kita perlu mengingat-ingat lagi kelas statistik yang pernah diikuti.
Simple Random Selection
Sesuai namanya, ini adalah cara termudah, pilih secara acak data dari populasi. Semua datum pada populasi punya kesempatan yang sama untuk terpilih.
Auditor menggunakan metode ini jika tidak ada kebutuhan untuk penekanan pada satu atau lebih jenis/kategori data pada populasi.
Karena sederhana dan populer, ada banyak alat bantu di komputer untuk mengambil sampel secara acak. Menggunakan R, salah satu fungsi untuk itu adalah dengan menggunakan fungsi sample_n dari tidyverse.
Cukup tentukan saja jumlah sampel yang akan diambil, dengan cara memberikan nilai pada parameter size. Di bawah ini adalah kode untuk mendapatkan 30 sampel dari penjualan tahun 2013.
simple_random_selection <- sales2013 %>% sample_n(size = 30)
Systematic Sample Selection
Pada metode ini, auditor menghitung interval kemudian memilih sampel berdasarkan interval tersebut.
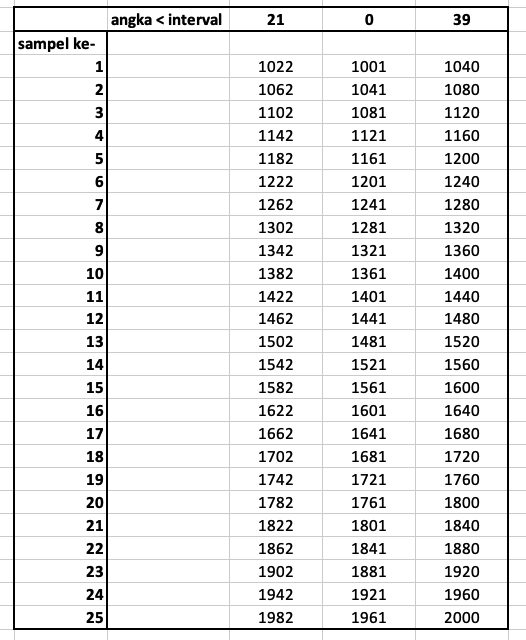
Sebagai ilustrasi, terdapat penjualan dengan nomor urut (SalesOrderID) 1001 hingga 2000, berikut cara penentuan sampelnya.
1. Tentukan Jumlah Sampel
Dari 1000 transaksi dengan nomor urut 1001 sampai 2000 akan diambil 25 sampel.
2. Hitung Interval
Caranya dengan membagi jumlah transaksi dengan banyak sampel yang akan diambil. Sehingga interval yang digunakan adalah 40 [(2000 – 1000) / 25].
3. Pilih Sampel Pertama
Pilih satu angka acak antara 0 sampai 39 (angka kurang dari interval). Taruhlah 21 sebagai angka terpilih maka sampel pertama adalah transaksi dengan nomor urut 1022 (1001 + 21).
4. Dapatkan Sampel Selanjutnya
Sampel selanjutnya didapatkan dengan menambahkan interval pada urutan sampel sebelumnya. Sampel kedua adalah 1062 (1022 + 40), ketiga 1102 (1062 + 40), keempat 1142 (1102 + 40) dan seterusnya hingga sampel terakhir pada nomor urut 1982.
Berikut ilustrasi sampel yang didapatkan jika menggunakan angka acak (angka kurang dari interval) 21, 0 dan 39.
Kode R
Tentukan Jumlah Sampel
Dari 14.182 transaksi penjualan pada tahun 2013 kita akan mengambil 100 sampel.
n_sample <- 100
Hitung Interval
Untuk mendapatkan interval, kita membagi banyaknya transaksi dengan rencana sampel yang akan diambil.
interval_sample <- ceiling(nrow(sales2013) / n_sample)
Fungsi nrow akan memberikan jumlah baris pada data sales2013 sedang fungsion ceiling berguna untuk pembulatan angka. Fungsi ceiling ini selalu melakukan pembulatan angka ke atas (misal 1,1 menjadi 2). Berikut rincian kode di atas jika dibagi per langkah.
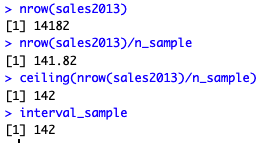
Seperti terlihat, interval yang kita dapatkan adalah 142.
Pilih Angka Acak untuk Sampel Pertama
interval_sample_min_one <- interval_sample - 1 random_num_less_than_interval <- sample(0:interval_sample_min_one, 1)

Sampel Pertama
Jika sampel pertama adalah transaksi pada baris ke-109 maka sampel kedua adalah transaksi pada baris ke-251 (109 + 142), demikian seterusnya hingga mendapatkan 100 transaksi yang akan dijadikan sampel audit.
Pertama kita perlu membuat sebuah variabel yang berisi daftar baris transaksi yang akan diambil sebagai sampel. Fungsi seq digunakan untuk membuat daftar nomor yang urut, dengan interval tertentu.
no_baris <- seq( from = 1 + random_num_less_than_interval, to = nrow(sales2013), by = interval_sample)
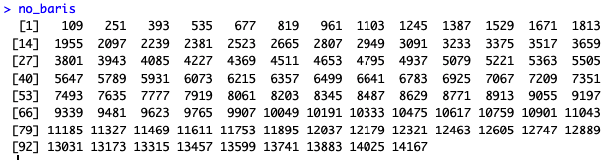
Selepas itu, fungsi slice dari dplyr digunakan untuk mengambil transaksi tertentu dari sales2013. Yang dimaksud dengan tertentu adalah transaksi dengan nomor baris yang ada pada daftar no_baris.
systematic_sample_selection <- sales2013 %>% slice(no_baris)
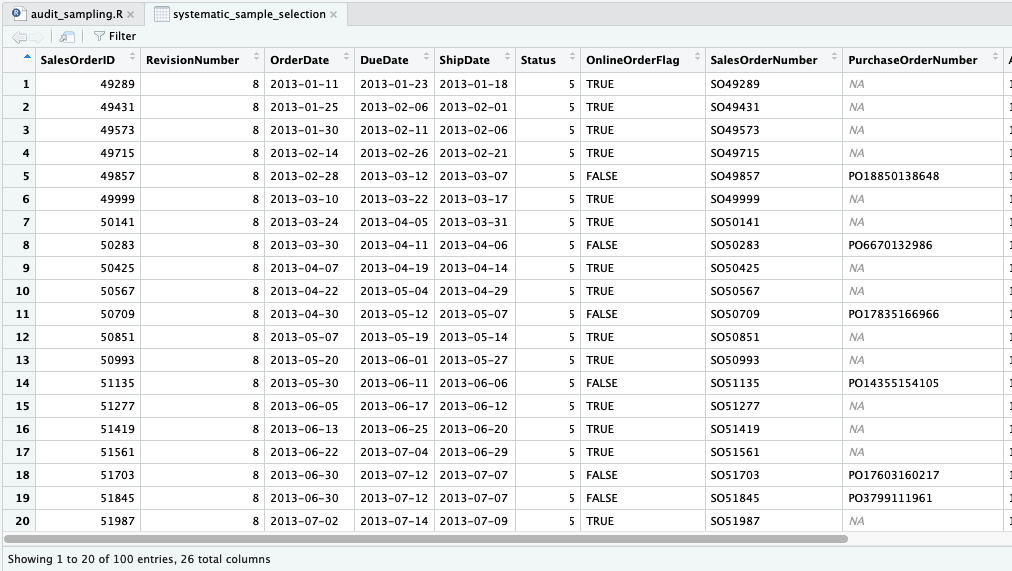
Sekarang kita punya variabel systematic_sample_selection yang menampung 100 transaksi yang akan disampel.
Probability Proportional to Size and Stratified Sample Selection
Monetary Unit Sampling (MUS)
Monetary Unit Sampling (MUS) adalah metode sampling statistik yang secara khusus dikembangkan untuk audit. MUS paling sering digunakan (setidaknya menurut Pak Arens) untuk melakukan pengujian saldo akun rinci. Hal tersebut karena MUS menawarkan kesederhanaan (metode statistik yang digunakan) layaknya attribute sampling namun menyediakan hasil statistik dalam bentuk mata uang (rupiah atau mata uang lain).
Pembahasan lebih rinci akan dilakukan karena MUS adalah konsep yang cukup besar. Untuk sementara kita cukupkan pemahaman bahwa MUS adalah metode sampling khusus untuk audit.
Probability Proportional to Size Sample Selection
MUS dipilih dengan probability proportional to size sample selection (PPS).
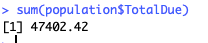
Dalam MUS, sampling unit adalah 1 satuan mata uang, rupiah jika di negeri sendiri, dan 1 dolar pada kasus AdventureWorks. Sedangkan populasi adalah total jumlah moneternya, USD48,965,888 untuk penjualan AdventureWorks pada 2013.

Untuk memudahkan ilustrasi, kita akan mengambil 25 transaksi awal dari penjualan 2013 yang dianggap populasi, kemudian mengambil sampel dari populasi tersebut.
“Populasi”
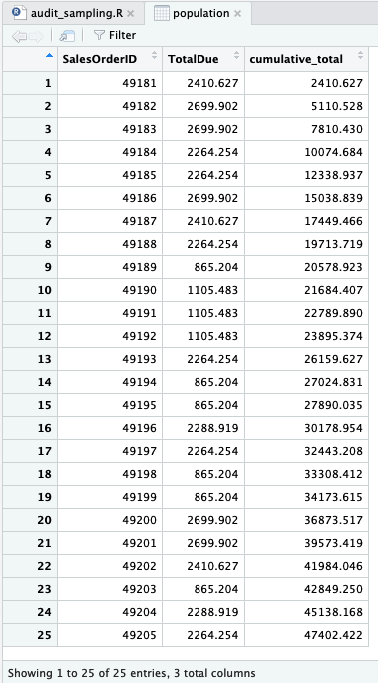
population <- sales2013 %>% slice_head(n = 25) %>% select(SalesOrderID, TotalDue)
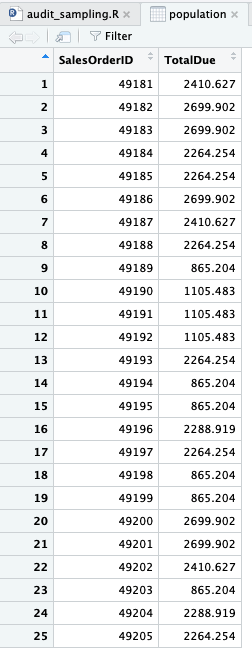
Seperti terlihat, keseluruhan populasi adalah 25 transaksi. Unit sampling adalah sebesar USD1 dan populasi senilai USD47,402.42.
Cumulative Total
Tambahkan nilai kumulatif di samping setiap transaksi.
population$cumulative_total <- cumsum(population$TotalDue)
Interval
Menggunakan Systematic Sample Selection, auditor ingin mengambil 4 sampel dari populasi di atas, sehingga interval sampel adalah 11,851 (47,402.422 / 4).
interval_sample <- ceiling(sum(population$TotalDue)/4)
Sampel Pertama
Pilih angka acak dalam rentang interval 11,851. Jika 10,160 yang didapatkan, maka angka tersebut, ditambah satu, adalah sampel pertama.
interval_sample_min_one <- interval_sample - 1 random_num_less_than_interval <- sample(0:interval_sample_min_one, 1)
Sampel Selanjutnya
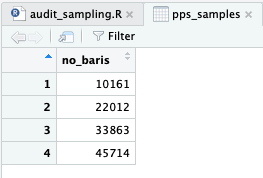
no_baris <- seq( from = 1 + random_num_less_than_interval, to = sum(population$TotalDue), by = interval_sample)

Jika dalam bentuk dataframe, berikut daftar sampel yang akan kita ambil.
pps_samples <- data.frame(no_baris)
Ambil Sampel
Sekarang tinggal “memetakan” daftar sampel tersebut ke populasi data.
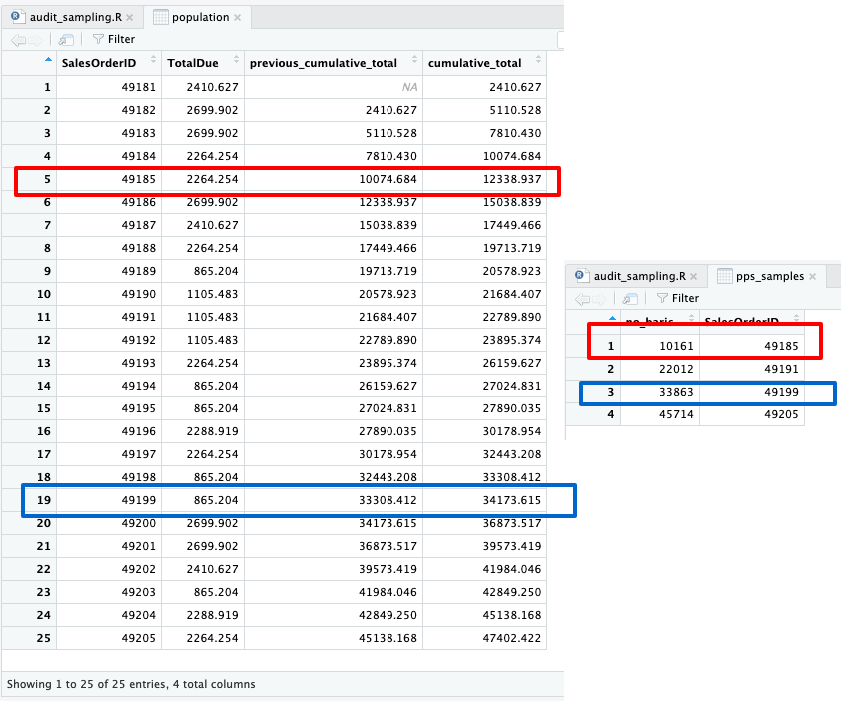
Karena hanya 4 vs 25, secara visual kita dapat mengenali transaksi mana saja yang akan dijadikan sampel. Yaitu transaksi dengan SalesOrderID 49,185, 49,191, 49,199 dan 49,205.
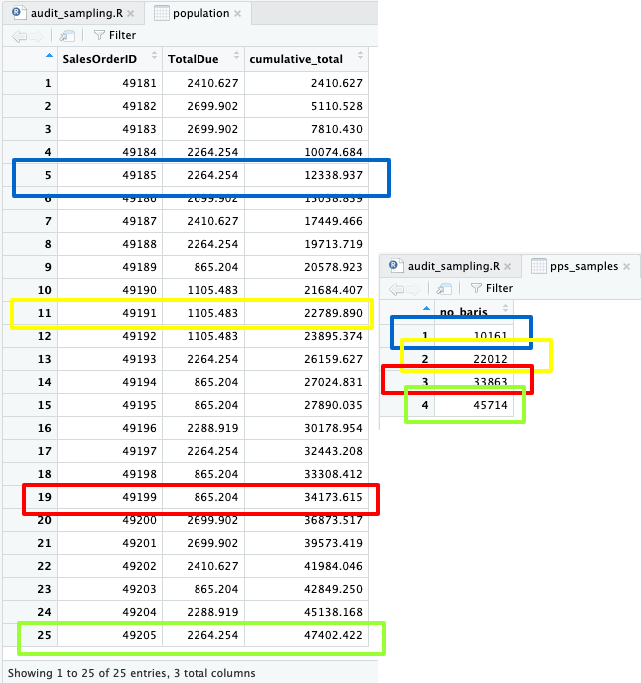
Namun apa gunanya belajar R jika tetap melakukan hal tersebut secara manual?
Selain itu, tentu menyiksa diri jika kita harus melakukan langkah tersebut untuk data berjumlah ratusan atau bahkan lebih.
Ambil Sampel (tydac manual)
Salah satu cara untuk mengidentifikasi transaksi yang akan diambil sebagai sampel adalah dengan menambahkan kolom nilai kumulatif baris sebelumnya, pada dataframe populasi.
population$previous_cumulative_total <- lag(population$cumulative_total, n=1) population <- population %>% relocate(previous_cumulative_total, .before = cumulative_total)
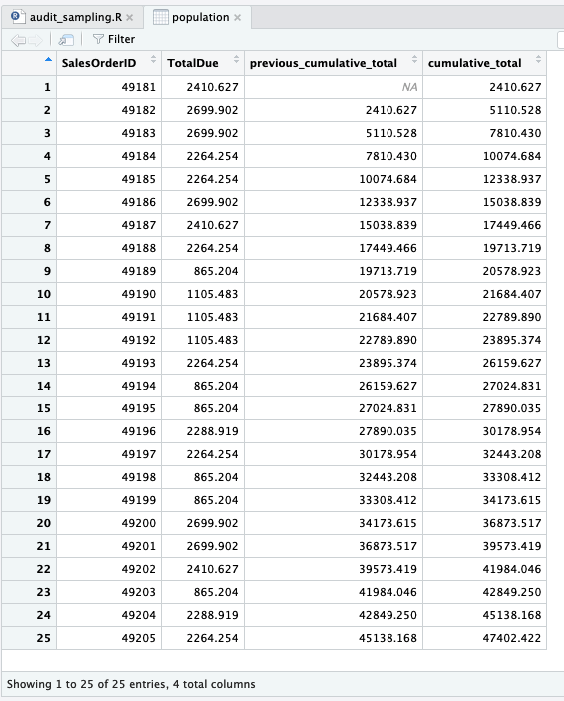
Kolom previous_cumulative_total dan cumulative_total menciptakan rentang nilai. Jika rentang tersebut mencakup nilai yang akan disampel, misal 10,161, maka transaksi tersebut (SalesOrderID 49185 yang mencakup rentang 10,074 – 12,338) akan terpilih.
f <- function(vec) {
if(length(.x <- which(vec >= population$previous_cumulative_total & vec <= population$cumulative_total))) .x else NA
}
pps_samples$SalesOrderID <- population$SalesOrderID[sapply(pps_samples$no_baris, f)]
Kode di atas akan menambahkan kolom SalesOrderID pada dataframe pps_samples. Kolom baru tersebut berisi SalesOrderID dari dataframe populasi, dengan syarat memiliki rentang nilai yang sesuai dengan kolom no_baris (pada dataframe pps_samples).
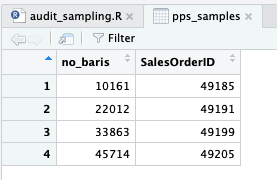
Jika dibandingkan dengan data populasi.
Stratified Sampling
Auditor dapat membagi populasi menjadi dua atau lebih subpopulasi sebelum mengambil sampel. Tiap subpopulasi tersebut disebut pula stratum. Dengan membuat stratifikasi, auditor dapat memberi penekanan (emphasize) pada bagian tertentu dari populasi.
Pada penjualan tahun 2013, berdasarkan tanggal order, kita dapat membuat stratifikasi bulanan, seperti ini.
sales_by_month <- sales2013 %>% count(months(OrderDate)) %>% rename(bulan= 1, banyak = 2) %>% arrange(match(bulan, month.name)) #mutate(bulan = factor(bulan, levels = month.name)) p <- ggplot(data = sales_by_month, aes(x=bulan, y = banyak, fill=bulan)) + geom_bar(stat = 'identity', show.legend = FALSE) + geom_text(aes(label=banyak), vjust=1.6, color="white", position=position_dodge(0.9), size=3.5) + theme_minimal() + scale_x_discrete(limits = month.name) + theme(axis.text.x=element_text(angle=45, vjust=0.5, hjust=1)) p
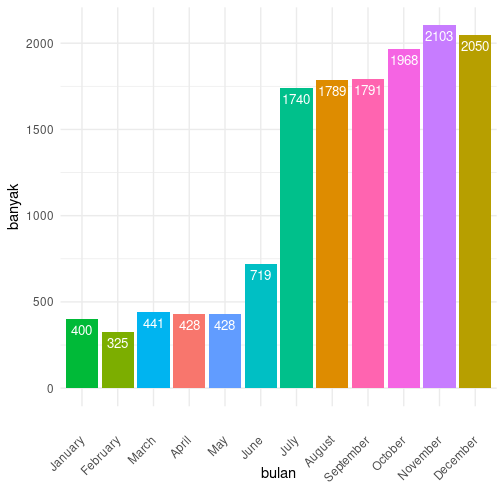
Bila ingin memberi penekanan pada bulan-bulan dengan transaksi yang banyak maka dapat dipilih transaksi dari Juli hingga Desember. Atau mengambil sampel dengan porsi yang lebih banyak, sesuai dengan banyaknya transaksi di tiap stratum.
Nonstatistical Sampling
Haphazard Sample Selection
Manapun transaksi dapat terpilih, tanpa memerhatikan ukuran, sumber atau karakter lain. Syaratnya hanya auditor dituntuk untuk tak punya bias, yang disadari, saat memilih sampel.
Rasa-rasanya tidak perlu menggunakan bahasa pemrograman untuk mengambil sampel jenis ini. Bahkan di sini dicontohkan pengambilan sampel dengan langsung mengambil secara acak kertas invoice dalam folder.
Block Sample Selection
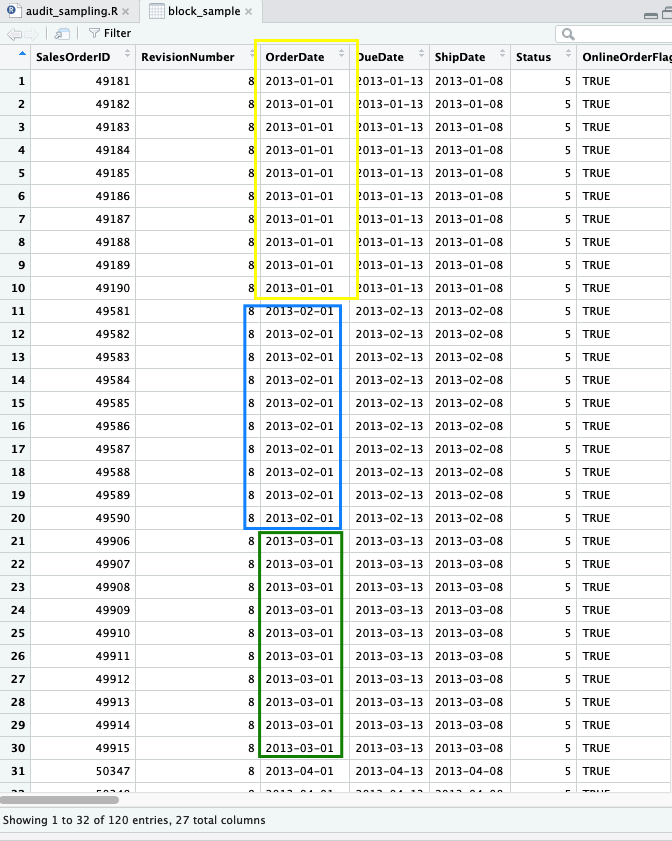
Sampel dipilih adalah transaksi dengan urutan yang berdekatan. Pak Louwers mencontohkan: pada daftar keanggotaan dipilih 10 anggota pertama pada masing-masing halaman (yang berisi daftar anggota). Jika daftar tersebut setebal 5 halaman, maka akan didapatkan 50 sampel.
Jika diaplikasikan pada penjualan AdventureWorks tahun 2013, kita dapat akan mengambil 10 transaksi pertama di tiap bulan sehingga total akan terdapat 120 sampel.
block_sample <- sales2013 %>% group_by(months(OrderDate)) %>% filter(row_number() < 11)
Cover Photo by Scott Graham on Unsplash
Referensi
- Auditing and Assurance Services, an Integrated Approach. 16th Ed, Arens A.
- Auditng & Assurance Services. 7th Ed, Louwers.
- https://www.cpajournal.com/2017/10/20/greatest-hits-monetary-unit-sampling-using-microsoft-excel/
- https://docplayer.info/47615576-Standar-audit-sa-500-bukti-audit.html
- https://docplayer.info/51782421-Standar-audit-sa-530-sampling-audit.html
- https://dplyr.tidyverse.org/reference/sample.html
- https://stackoverflow.com/questions/39536807/r-check-if-value-from-dataframe-is-within-range-other-dataframe
Berlangganan
Suka tulisan di sini, silahkan mengisi formulir di bawah ini untuk berlangganan agar kami dapat mengirim pemberitahuan tulisan baru.