

Audit Data Analytics dengan R – Data Transformation
Data tidak pernah hadir dalam bentuk yang kita impikan, selalu begitu. Bisa jadi karena harapan kita yang keliru.
Kode Lima Detik
if(!'tidyverse' %in% installed.packages()) { install.packages('tidyverse', dependencies= TRUE)}
library(tidyverse)
Data di Dunia Nyata
Mentransformasi data adalah kebutuhan semua orang, baik sadar maupun tidak. Auditor sebagai pengguna intensif data adalah pihak yang paling menderita jika data yang ada tidak sesuai dengan kebutuhannya. Jika hari sedang buruk, auditor bisa keliru menarik simpulan “hanya” karena data yang dimiliki menuntunnya ke arah sana.
Keterampilan mentransformasi data yang baik menjadi wajib bagi auditor.
Untungnya teknologi, lagi-lagi, telah siap dengan solusi, hanya menunggu untuk digunakan.
Library
Begitu dikeluarkan dari dusnya, R telah memiliki banyak fungsi untuk mentransformasi data. Fungsi library (package) adalah untuk menambah fungsi atau “membungkus” agar fungsi yang ada makin mudah digunakan.
Salah satu library R yang “wajib diketahui” adalah tidyverse, yang memuat beberapa library seperti dplyr, ggplot2 dan lainnya, untuk memudahkan interaksi dengan data.
Pada tulisan ini kita akan menggunakan tidyverse (persisnya dplyr) untuk belajar mentransformasi data. Struktur tulisan dan penjelasan sangat terinspirasi (baca: menjiplak) buku R for Data Science-nya pak Hadley dan pak Garret.
Instalasi
Jika belum pernah menggunakan, library tidyverse dapat diinstal melalui panel Packages pada RStudio. Klik ikon Install.

Kemudian ketik tidyverse dan klik Install.
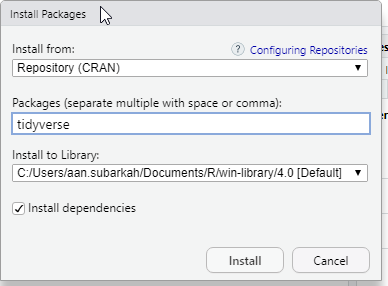
Di atas adalah langkah mudah untuk mengetik ‘install.packages(“tidyverse”)‘ pada R Console.

Alternatif
Sebagai alternatif, kita dapat menggunakan kode di bawah ini yang akan melakukan instalasi tidyverse jika tidak menemukan pada komputer.
if(!'tidyverse' %in% installed.packages()) { install.packages('tidyverse', dependencies= TRUE)}
Data
Data yang akan kita gunakan adalah data penjualan dari Kaggle. Sayangnya tidak banyak informasi yang dideskripsikan, hanya “DB of grocery sales 6M+”. Data ini memang memuat 6.758.125 penjualan pada file sales.csv.
Dengan jumlah data sebanyak itu, tulisan ini sekaligus bertujuan untuk mendemonstrasikan kelebihan R, yaitu menangani data >1.048.576 baris.
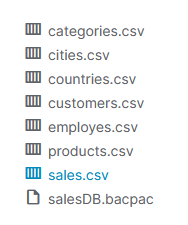
Data penjualan ini memuat 8 berkas namun kali ini kita hanya akan menggunakan sales.csv.
Load Data
Setelah mengunduh data kita buat sebuah R Script dengan nama sales_transformation.R.

Sama seperti tulisan sebelumnya, folder tempat kerja adalah D:\basangdata\audit_with_r_intro (silahkan disesuaikan dengan kondisi pembaca). File sales.csv yang akan digunakan juga disimpan dalam folder tersebut.
Sehingga kode untuk menetapkan default folder, “memanggil” library dan me-load data adalah sebagai berikut.
setwd("D:/basangdata/audit_with_r_intro")
library(tidyverse)
sales <- read.csv('sales.csv', sep = ';')
Proses load data membutuhkan sedikit waktu.
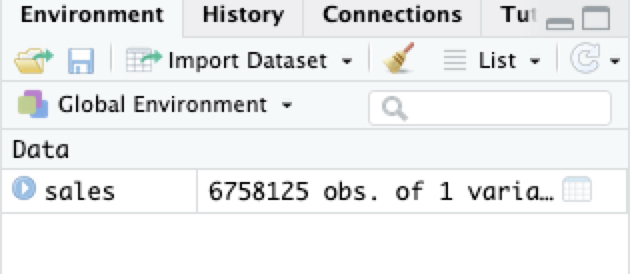

Data terdiri dari 9 kolom dan 6.758.125 baris.
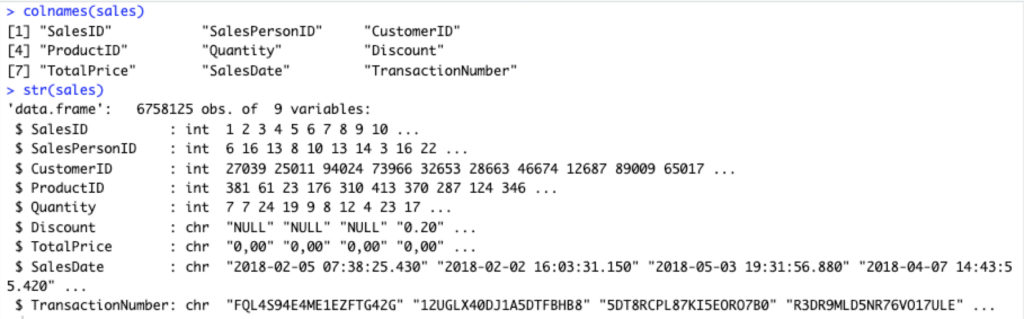
Untuk melihat nama kolom dapat menggunakan fungsi colnames. Sedang jika ingin tahu tipe data masing-masing kolom fungsi str yang dimanfaatkan.
Filter
Untuk dapat menyeleksi/memfilter data, library dplyr menyediakan fungsi filter. Beberapa skenario yang dapat dilakukan saat memfilter adalah sebagai berikut.
Perbandingan
R telah menyediakan operator perbandingan == (sama dengan), != (tidak sama dengan), >, >=, <, dan <=.
Jika ingin mengetahui penjualan yang dilakukan oleh SalesPersonID 6 maka kode berikut digunakan.
filter(sales, SalesPersonID == 6)
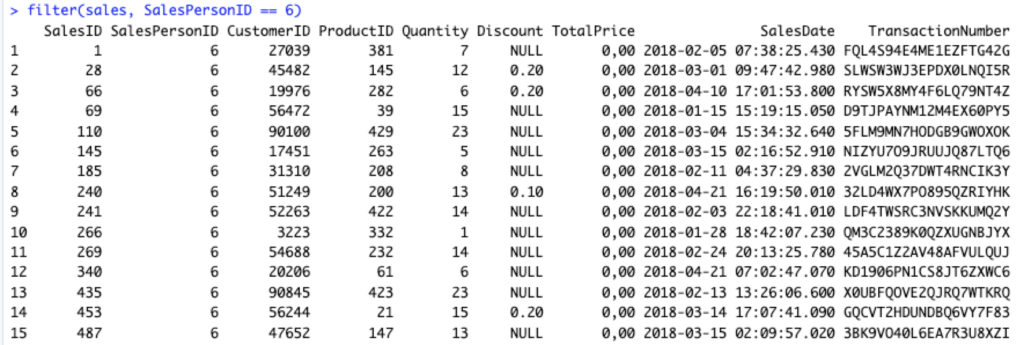
Untuk kenyamanan, kita dapat menggunakan fungsi View saat akan menampilkan data.
View(filter(sales, SalesPersonID == 6))
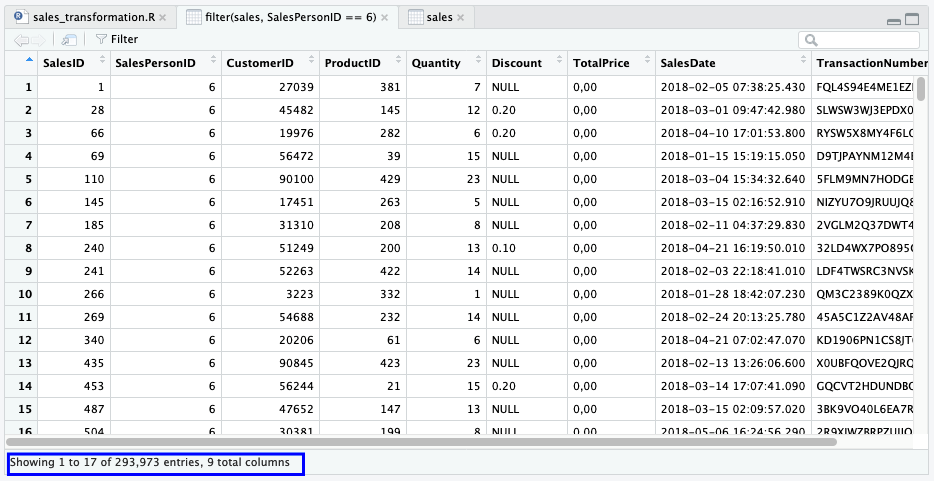
Sebagai bonus, menggunakan View kita mendapat informasi jumlah kolom dan baris data yang ditampilkan.
Untuk mengetahui penjualan yang tidak dilakukan SalesPersonID 6, gunakan operator !=.
filter(sales, SalesPersonID == 6)
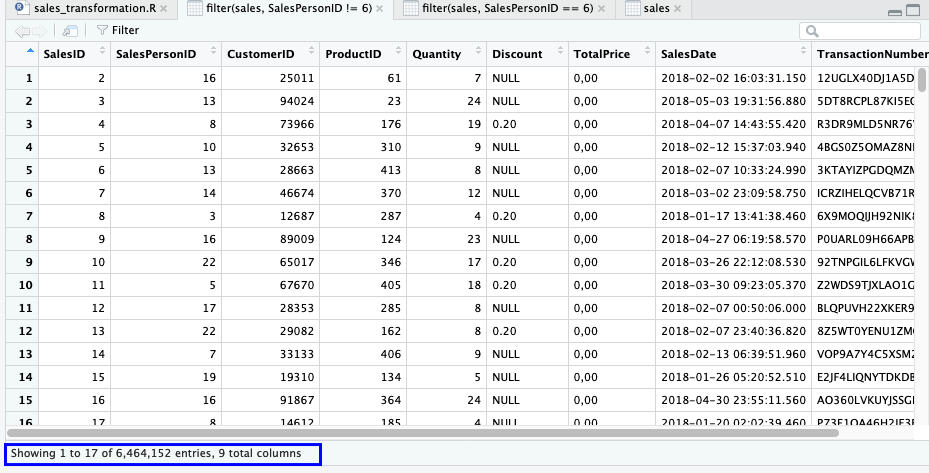
Operator Logika
Operator logika kadang memang membingungkan. Berikut ini visualisasi untuk mempermudah. Bagian berwarna biru adalah data yang akan ditampilkan jika menggunakan operator logika di bawahnya.
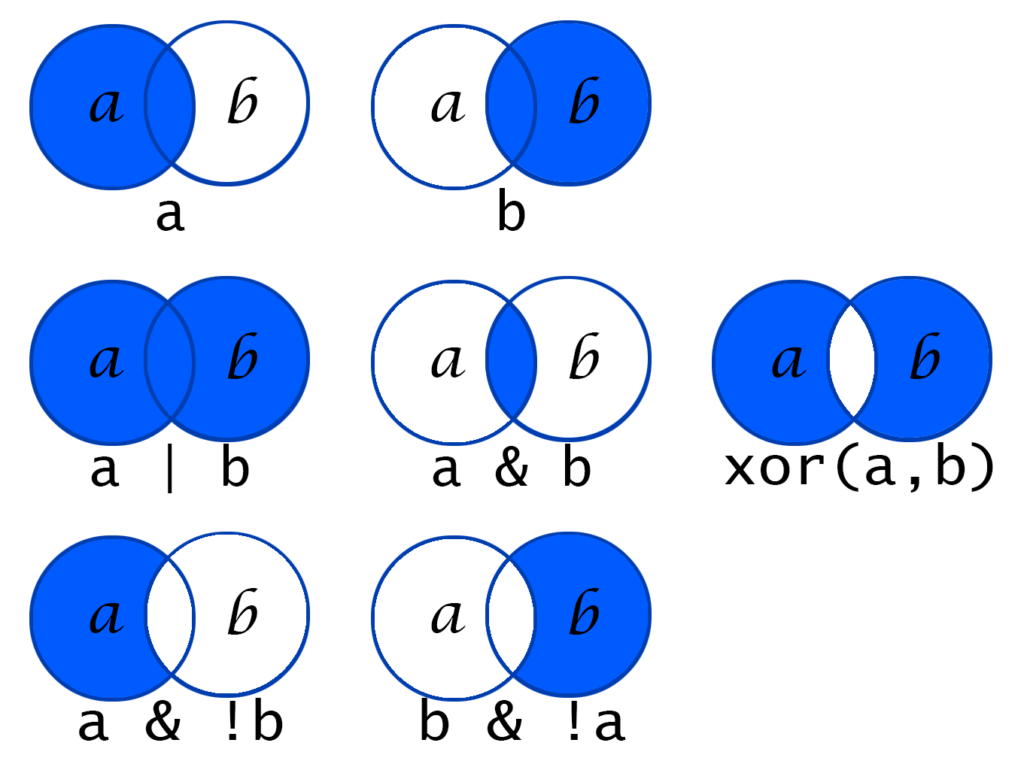
a | b
Ingin melihat penjualan yang dilakukan SalesPersonID 6 dan SalesPersonID 13? Gunakan operator | (or/atau).
filter(sales, SalesPersonID == 6 | SalesPersonID == 13)
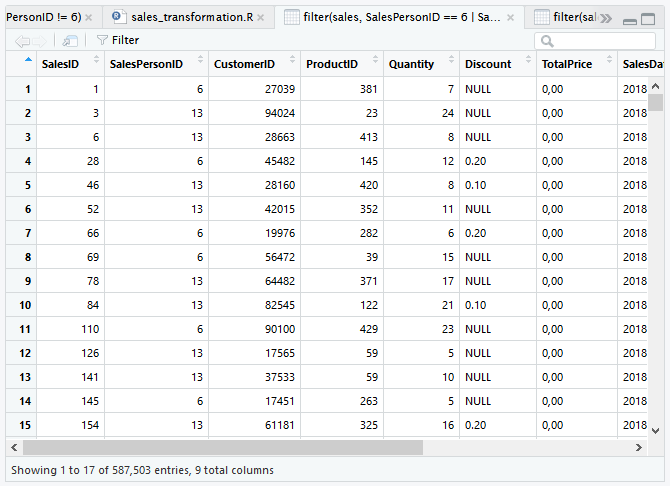
Sebagai alternatif kita dapat menggunakan %in%.
filter(sales, SalesPersonID %in% c(6, 13))
Sehingga untuk melihat penjualan SalesPersonID 6, 13 dan 8 dapat menggunakan kode.
filter(sales, SalesPersonID %in% c(6, 13, 8))
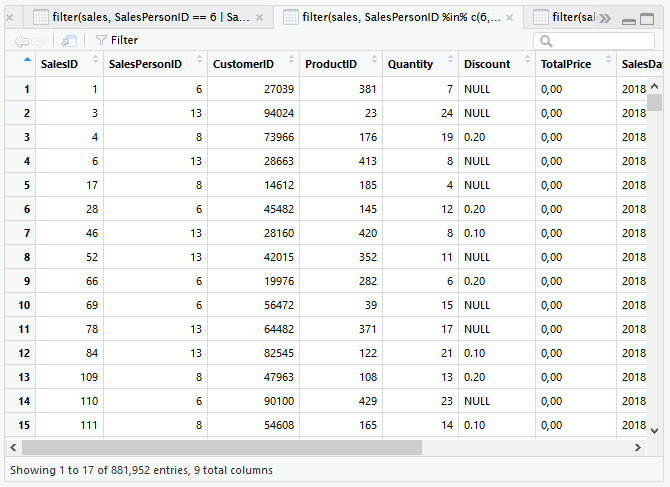
a & b
Ada berapa banyak penjualan ProductID 381 oleh SalesPersonID 6? Operator & (and) yang kita gunakan.
filter(sales, ProductID == 381 & SalesPersonID == 6)
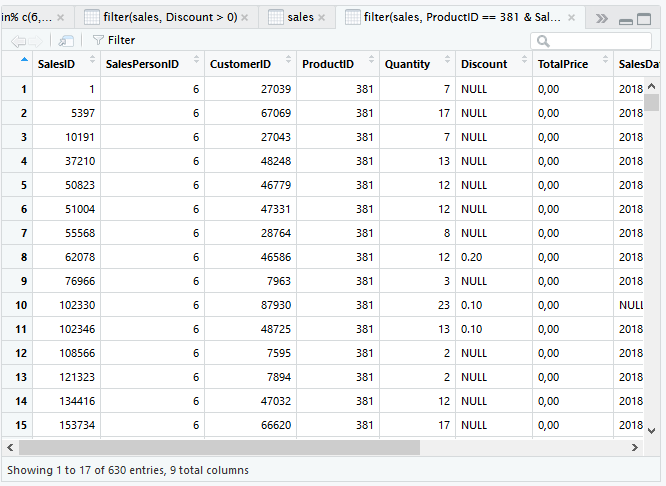
xor(a, b)
Penjualan oleh SalesPersonID 6 (kecuali ProductID 381) dan penjualan produk ProductID 381 oleh semua SalesPersonID (selain SalesPersonID 6).
filter(sales, xor(SalesPersonID == 6, ProductID == 381))
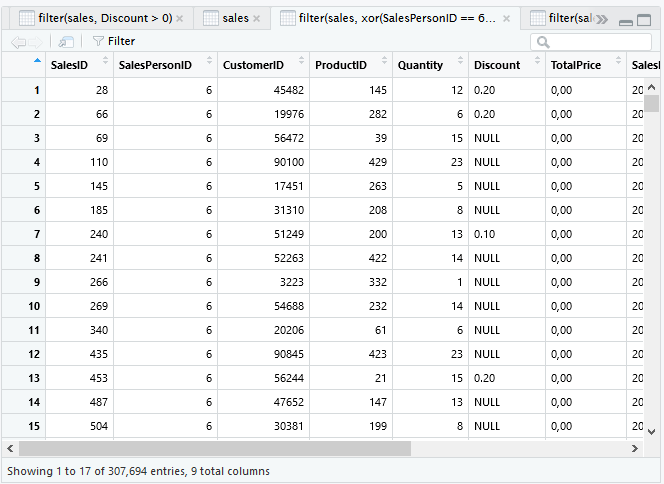
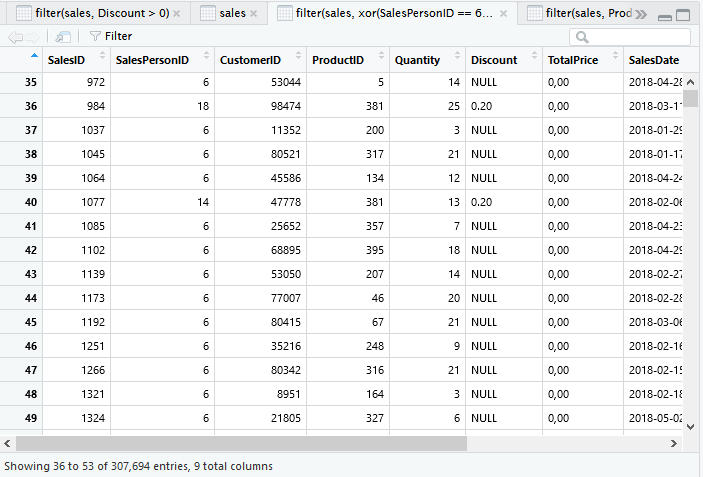
a & !b
Penjualan oleh SalesPersonID 6 kecuali ProductID 381.
filter(sales, SalesPersonID == 6 & ProductID != 381)
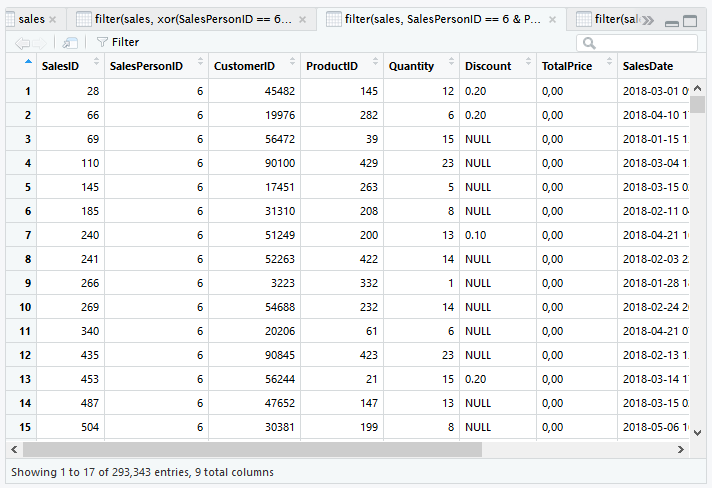
Arrange
Mengurutkan data dapat dilakukan pada berapapun kolom, menggunakan fungsi arrange. Untuk satu kolom, kita contohkan mengurutkan data berdasarkan kolom SalesPersonID.
arrange(sales, SalesPersonID)
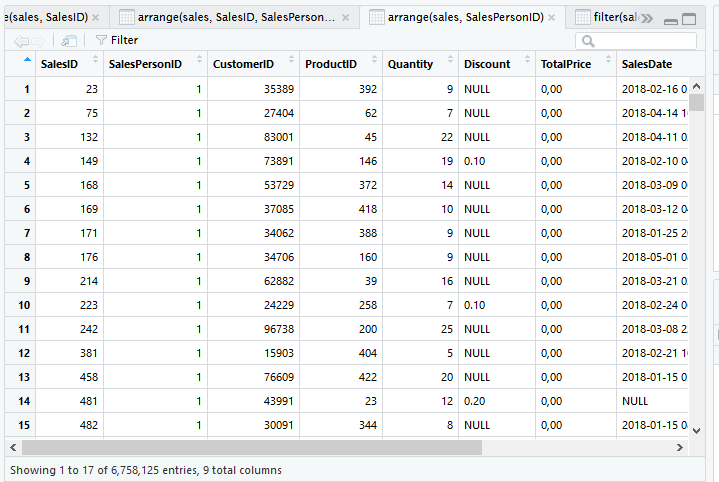
Urutkan berdasarkan SalesPersonID, ProductID dan Quantity.
arrange(sales, SalesPersonID, ProductID, Quantity)
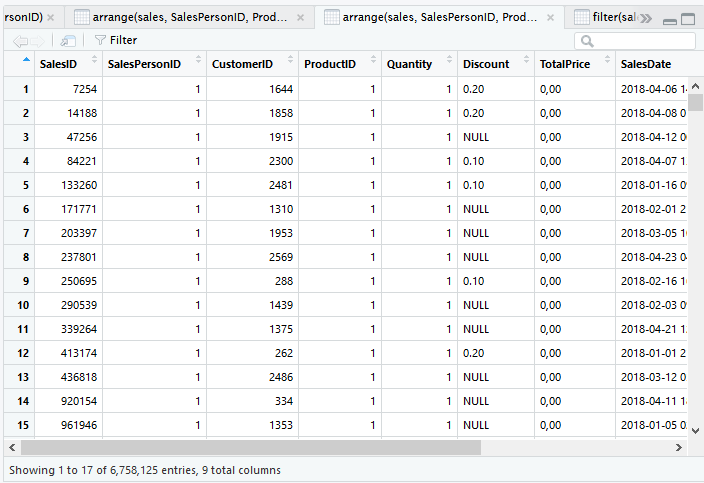
Untuk mengurutkan dari belakang, gunakan desc. Seperti sebelumnya, urutkan berdasarkan SalesPersonID, ProductID dan Quantity, namun Quantity dari terbanyak ke tersedikit.
arrange(sales, SalesPersonID, ProductID, desc(Quantity))
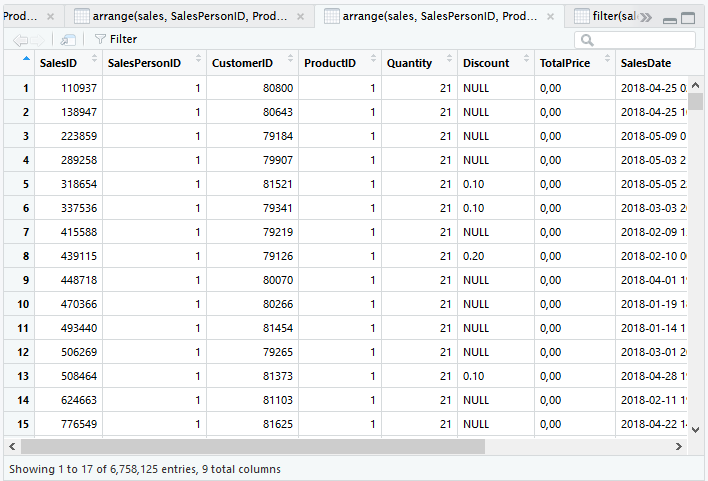
Select
Fungsi select disediakan untuk memilih kolom yang ditampilkan. Meski terdengar sederhana namun banyak skenario yang dapat ditempuh.
Tampilkan hanya kolom SalesID, SalesPersonID dan CustomerID.
select(sales, SalesID, SalesPersonID, CustomerID)

Tampilkan kolom dari SalesID hingga Quantity.
select(sales, SalesID:Quantity)
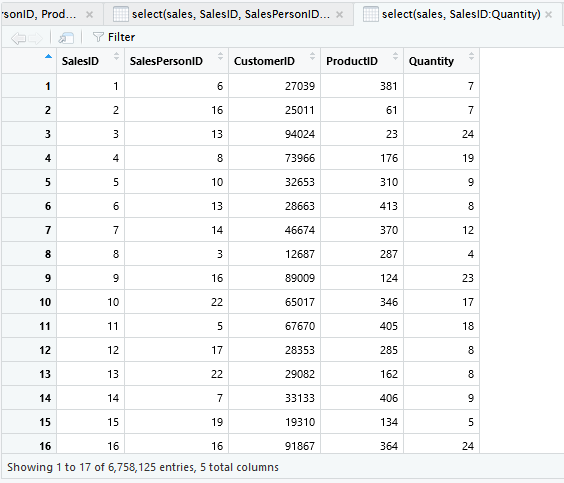
Tampilkan semua kolom selain dari SalesPersonID hingga ProductID.
select(sales, -(SalesPersonID:ProductID))
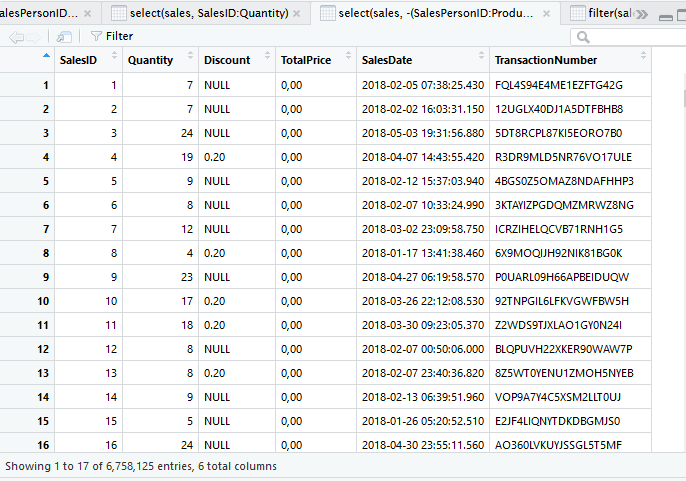
Tampilkan kolom yang dimulai dengan S.
select(sales, starts_with('S'))
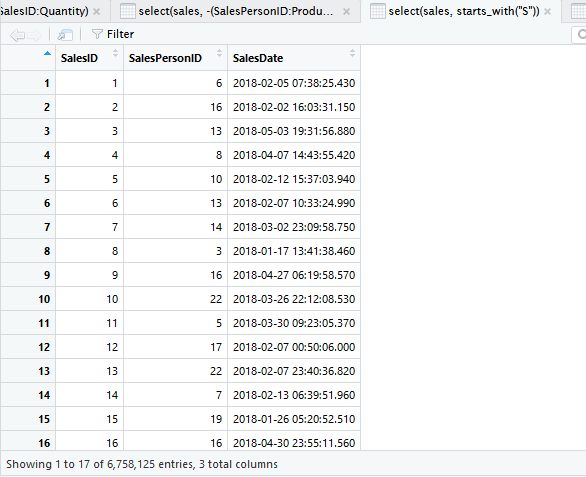
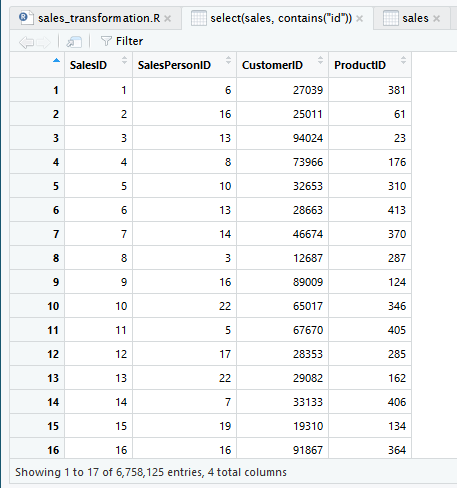
Tampilkan kolom yang memuat “id”.
select(sales, contains('id'))
Add Column(s)
Kolom yang ada seringnya belum memadai, masih perlu ditambahkan. Library dplyr menyediakan mutate untuk melakukan itu. Penggunaannya mudah, hanya perlu nama variabel penampung data (sales) dan kolom baru yang akan ditambahkan. Misal menambah kolom num yang nilainya adalah nilai kolom SalesID + 1.
mutate(sales, num = SalesID + 1)
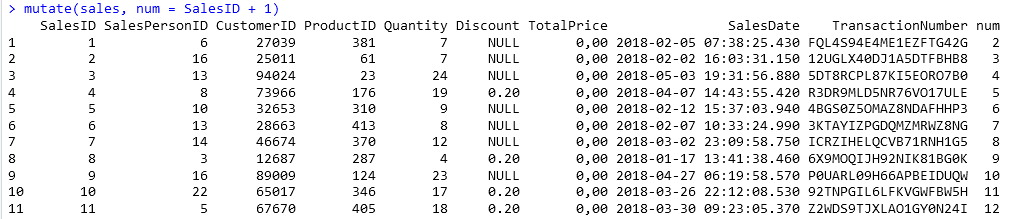
Perlu dicatat, fungsi mutate tidak merubah data.
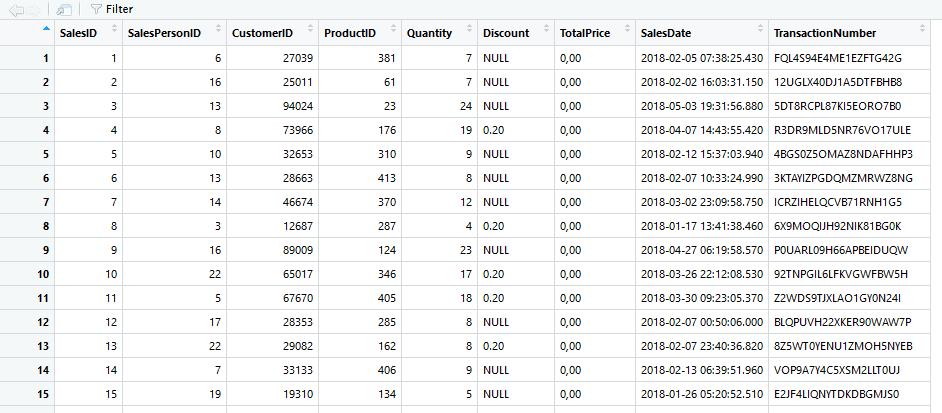
Jika ingin menambah kolom secara permanen kita dapat membuat sebuah variabel data baru yang menampung data lama + kolom tambahan yang dibuat. Atau dapat pula menggunakan variabel data lama.
sales <- mutate(sales, num = SalesID + 1)
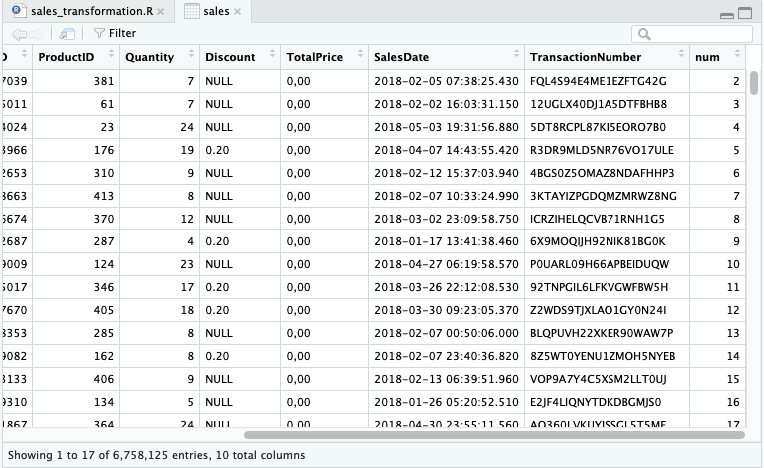
Fungsi mutate dapat juga menangani teks, misal dari kolom SalesDate kita akan mengambil hanya tanggal dan ditampung pada kolom SalesDateOnly.
mutate(sales, SalesDateOnly = unlist(strsplit(SalesDate, ' '))[1])
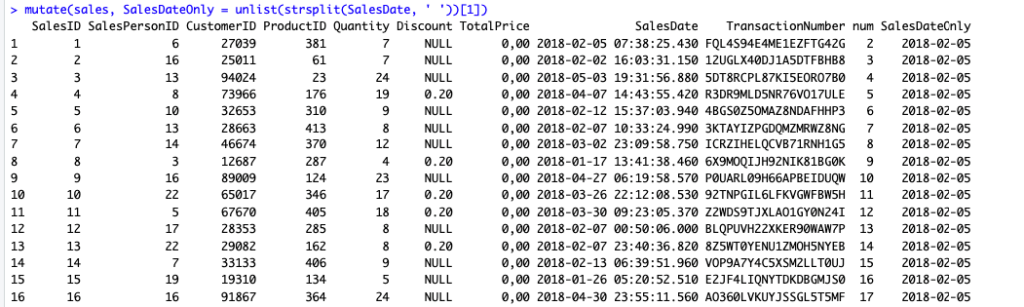
Kode di atas menggunakan strsplit untuk memisahkan teks berdasarkan spasi dan fungsi unlist agar dapat mengakses teks-teks yang telah dipisahkan.
Grouped Summaries
Meringkas (summarise) data oleh dplyr dibantu dengan fungsi summarise yang akan membuat dataframe baru berisi satu (atau beberapa) baris.
Kode di bawah ini akan membuat sebuah kolom bernama QuantityMean, berisi nilai rata-rata (mean) dari kolom Quantity.
summarise(sales, QuantityMean = mean(Quantity))

Group by
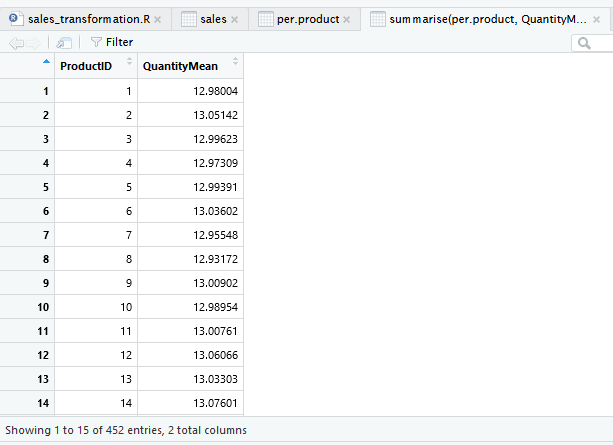
Data dapat dikelompokkan terlebih dahulu, kemudian diringkas. Misal kita ingin mengetahui rata-rata jumlah (Quantity) penjualan per jenis produk (ProductID).
Pertama data dikelompokkan per ProductID menggunakan fungsi group_by dari dplyr. Kemudian pada baris kedua, dapatkan rata-rata jumlah terjual menggunakan fungsi summarise.
per.product <- group_by(sales, ProductID) summarise(per.product, QuantityMean = mean(Quantity))
Pipes
Membuat variabel baru (per.product) hanya demi menampilkan ringkasan penjualan per ProductID bisa jadi terlalu berlebihan. Menghindari itu, tidyverse mengenalkan konsep Pipes (pipa) yang kurang lebih memerintahkan komputer untuk “lakukan A kemudian pada hasil A, lakukan B”.
A %>% B
Agak teknis, simbol %>% tersebut diambil dari library magrittr. Tak perlu khawatir, tidyverse otomatis menginstall dan me-load library tersebut.
Menggunakan pipes, kode untuk mendapatkan rata-rata jumlah penjualan per ProductID adalah sebagai berikut.
group_by(sales, ProductID) %>% summarise(QuantityMean = mean(Quantity))
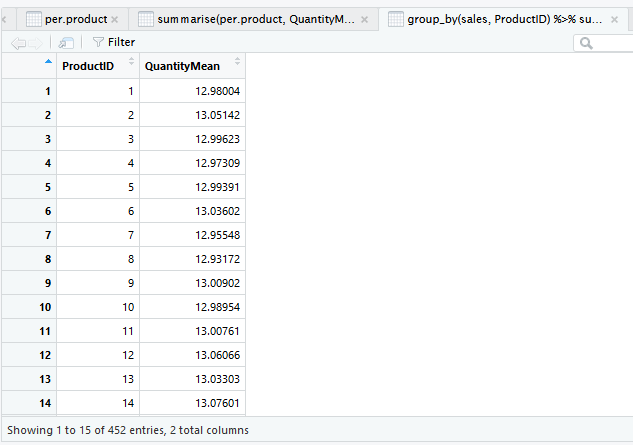
Untuk mendapatkan hasil yang sama namun lebih mudah dibaca, dapat pula menggunakan kode berikut.
sales %>% group_by(ProductID) %>% summarise(QuantityMean = mean(Quantity))
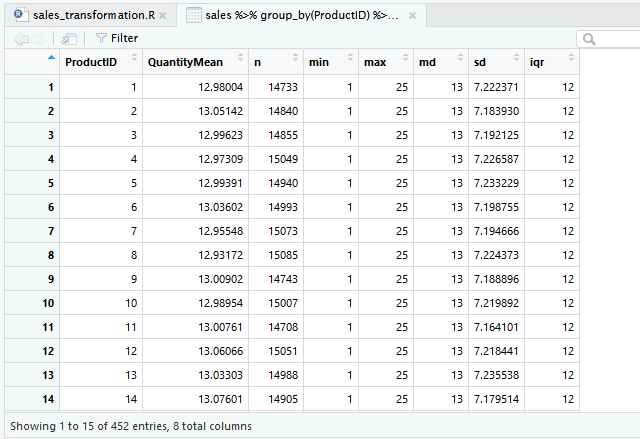
Other Summary Functions
Pada contoh di atas, ringkasan yang ditampilkan adalah nilai rata-rata (mean), selainnya ada beberapa.
- n() untuk mendapatkan jumlah data
- min untuk mendapatkan nilai terkecil
- max untuk nilai terbesar
- median untuk mendapatkan median
- sd untuk Standar Deviasi
- IQR untuk mendapatkan Interquartile Range
sales %>%
group_by(ProductID) %>%
summarise(
QuantityMean = mean(Quantity),
n = n(),
min = min(Quantity),
max = max(Quantity),
md = median(Quantity),
sd = sd(Quantity),
iqr = IQR(Quantity)
)
Konklusi
Mentransformasi data menggunakan dplyr hanya butuh sedikit pengetahuan dan (sisanya) imajinasi. Fungsi yang disediakan library telah mencakup mayoritas skenario saat berhubungan dengan data.
Pada tulisan ini didemonstrasikan transformasi pada 6juta baris data. Hanya butuh beberapa detik proses pada komputer kebanyakan orang dengan 8GB RAM, beberapa proses butuh waktu lebih lama namun masih dapat diterima.
Langganan dan Saran
Jika suka tulisan di sini silahkan berlangganan agar kami dapat mengirimkan pemberitahuan tulisan baru. Punya saran atau keluhan terhadap blog ini, boleh ajukan langsung pada kami.
Pelbagai tips harian, ada di Twitter.
Referensi
- https://r4ds.had.co.nz/transform.html
- https://www.kaggle.com/codemysteries/salesdb?select=products.csv
Terima kasih, Kak.
Sejauh yang saya temui, informasi di situs inilah yang menyajikan tutorial R dengan sangat rinci dan menggunakan narasi yang mudah dimengerti. Mohon tambah lagi tutorial pengolahan teks stringR 😀 Saya sedang belajar mengolah data bahasa menggunakan R. Mohon doanya.
Hi, Eka.
Terimakasih telah membaca. Semoga di masa depan dapat diwujudkan tulisan mengenai StringR.
Tetap semangat ya, Eka.