

Ambil Data dari Web dengan Scrapy
Jika ingin mendapatkan bahan belajar lebih banyak, sila gunakan frasa scrapy web scraping pada mesin pencari. Dengan asumsi pembaca telah karib dengan proses instalasi library di python atau telah membaca tulisan ini maka untuk instalasi scrapy cukup mengetikkan.
pip install scrapy
Jaman now internet adalah sumber utama data dan informasi karenanya sering kita menemui kebutuhan mengambil data dari internet (halaman web). Solusi termudah dan paling sering dilakukan adalah copy dan paste.
Namun kita, manusia, cepat capek dan bosan, melakukan copy paste >5x pasti sudah muak, apalagi jika prosedur yang dilakukan sama. Sebab itu web scraping digunakan. Web scraping seperti kita membuka halaman web, lalu menyalin bagian-bagian yang akan diambil dan paste ke file excel, berulang-ulang sampai habis semua halaman yang mengandung informasi yang kita butuhkan. Pekerjaan yang dibayangkan saja sudah capek, apalagi jika sudah kenal dengan teknik web scraping, makin benci lagi. Kwkwkw.
Untuk dapat melakukan web scraping a.k.a mengambil data dari halaman web, setidaknya kita perlu memiliki pengetahuan soal html dan karena kita akan menggunakan scrapy maka pengetahuan mengenai library ini menjadi wajib. Jika Anda sama sekali belum mengetahui mengenai html silahkan membaca bahan yang tersedia di sini:
- https://www.w3schools.com/html/html_intro.asp
- https://www.geeksforgeeks.org/html-introduction/
- https://www.w3docs.com/learn-html/html-introduction.html
- https://www.tutorialspoint.com/html/
- https://developer.mozilla.org/en-US/docs/Learn/HTML/Introduction_to_HTML
Sedangkan untuk penggunaan scrapy, kita akan belajar menggunakan tutorial yang disediakan oleh scrapy. Oya, untuk web scraping selain scrapy dapat pula digunakan library lain seperti requests dan selenium.
Setelah melakukan instalasi, kita dapat membuat scrapy project dengan mengetikkan kode ini di terminal/command line.
scrapy startproject tutorialscrape

Dalam folder tutorialscrape terdapat folder dan file seperti ini.
Proyek pertama kita adalah mengambil judul artikel dari blog ini (basangdata.com). Pemilihan obyek latihan bukan (hanya) karena narsis namun ada alasannya.
Web scraping adalah proses terotomasi artinya komputer akan bekerja 24/7. Untuk mengakses sebuah halaman web, batasannya hanya kecepatan koneksi internet, sebuah komputer dengan spek terbatas sekalipun, seperti raspberry, di luar kecepatan koneksi, dapat membuka web kurang dari 1 detik. Dan raspberry itu dapat membuka banyak halaman web dalam waktu bersamaan. Sebagai akibatnya request ke halaman web menjadi tinggi dan server web dapat ambruk jika tidak mampu menanganinya. Web scraping bisa mengganggu kinerja web sehingga web dengan trafik tinggi, seperti ecommerce, membatasi akses web, misal jika kita melakukan request > 10 kali dalam 1 detik (manusia mustahil melakukan ini) server akan memberikan error 429.
Sangat disarankan untuk tetap sopan saat melakukan scraping web, sila merujuk artikel ini dan ini untuk menghindari diblokir oleh server tujuan.
Kembali ke proyek kita, tahap awal web scraping adalah mengobservasi halaman web yang akan kita scraping, mirip langkah reconnaissance dalam hack.
Jika kita meng-klik kanan halaman basangdata dan melihat source (View Page Source jika menggunakan Firefox) maka halaman web tersebut sebenarnya terdiri dari tag-tag html berikut.
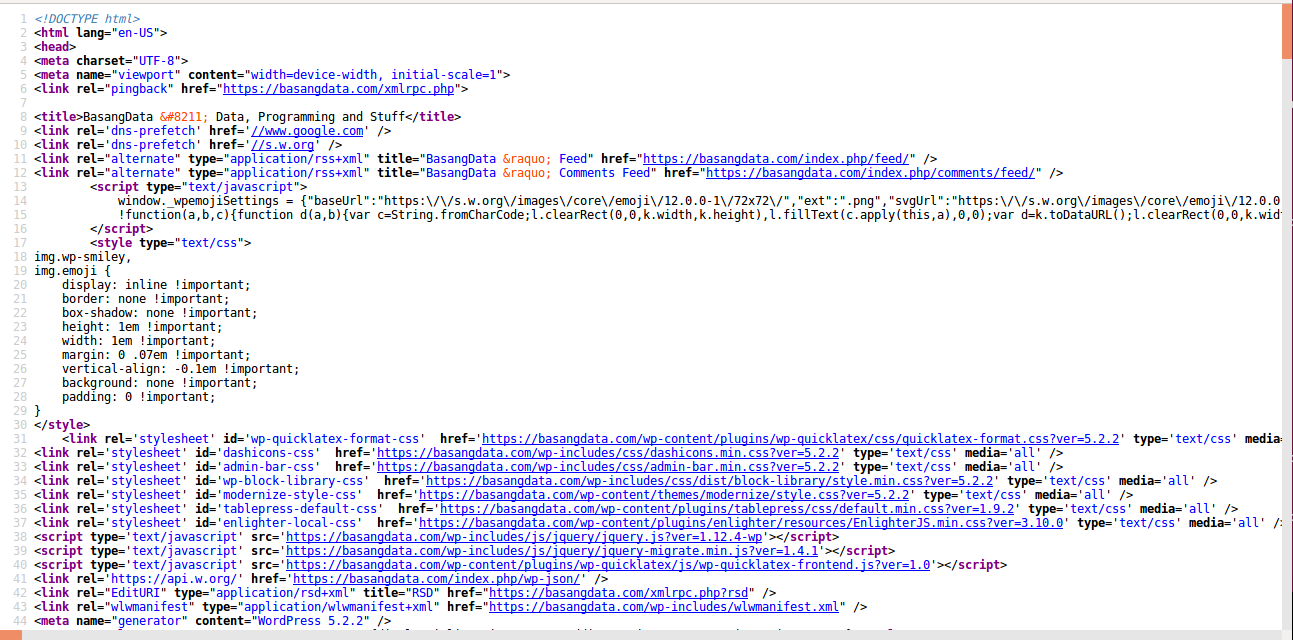
Karena informasi yang akan diambil hanyalah judul artikel maka kita perlu mengenali ciri-ciri judul artikel itu.
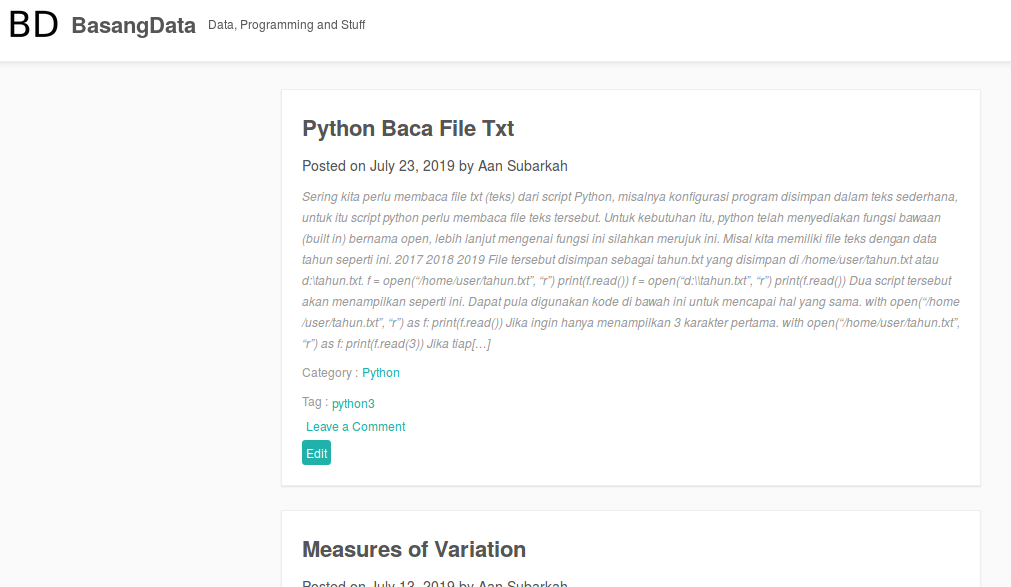
Seperti terlihat, judul artikel ditulis tebal (bold), berukuran lebih besar dari isi artikel dan berada di atas teks Posted on… Selain itu judul artikel adalah pranala (link) menuju halaman artikel lengkap. Karena halaman web adalah tag html maka ciri-ciri tersebut dapat diidentifikasi pada tag html yang digunakan. Peramban memiliki fitur yang sangat membantu dalam proses ini yaitu inspector element. Arahkan pointer ke judul artikel lalu klik kanan dan pilih Inspect Element (Firefox) atau Inspect (Chrome).
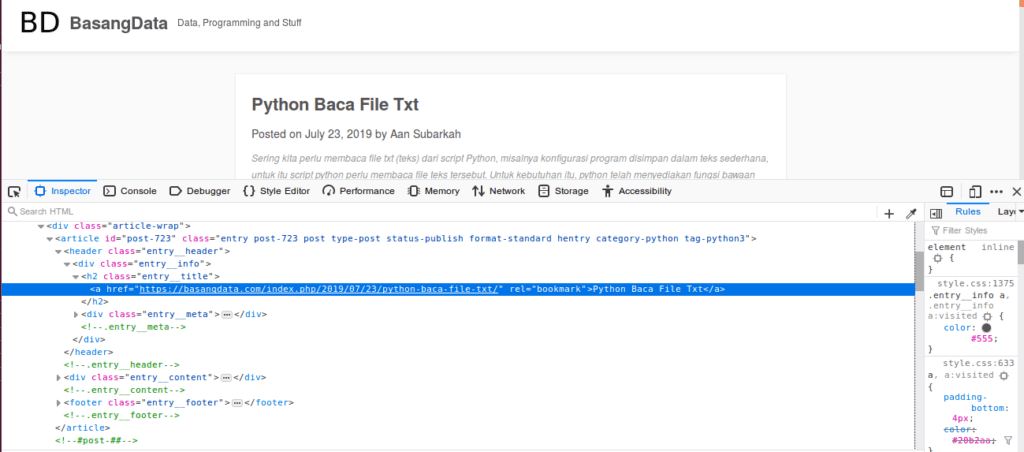
Setelah melakukan proses yang sama pada judul artikel lainnya maka kita dapat mengidentifikasi tag html yang selalu digunakan adalah <h2> dengan kelas (class) bernama entry__title. Untuk memastikan, kita dapat melakukan pencarian kelas tersebut, gunakan ctrl + f lalu ketik entry__title.

Terdapat 10 elemen dengan kelas tersebut, jika angka tersebut sama dengan jumlah judul artikel yang secara visual dapat kita ketahui maka dipastikan bahwa elemen tersebut adalah target kita.
Didalam tag <h2> terdapat tag <a> yang berisi judul artikel. Karena itu kombinasi tag yang identik dengan judul artikel adalah <h2 class=”entry__title><a>, tag a yang berada dalam tag h2 dengan kelas entry__title. Kenapa tidak langsung saja tag <a>? Karena tag <a> tersebut tidak identik dengan judul artikel. Jika dicari, tag <a> dalam halaman tersebut ada >100 buah, lebih dari judul artikel yang hanya 10.
Selanjutnya kita gunakan scrapy untuk mengambil data tersebut. Buat sebuah spider dengan membuat file judul_spider.py di folder tutorialscrape/spiders.
import scrapy
class JudulSpider(scrapy.Spider):
name = "judul"
def start_requests(self):
urlBasang = "https://basangdata.com"
yield scrapy.Request(url = urlBasang, callback = self.parse)
def parse(self, response):
print(response.body)
Kemudian eksekusi dengan perintah scrapy crawl namaspider, namun sebelumnya pastikan kita telah berada dalam folder tutorialscrape.
cd tutorialscrape scrapy crawl judul

Jika di-scroll ke bawah maka akan terlihat.
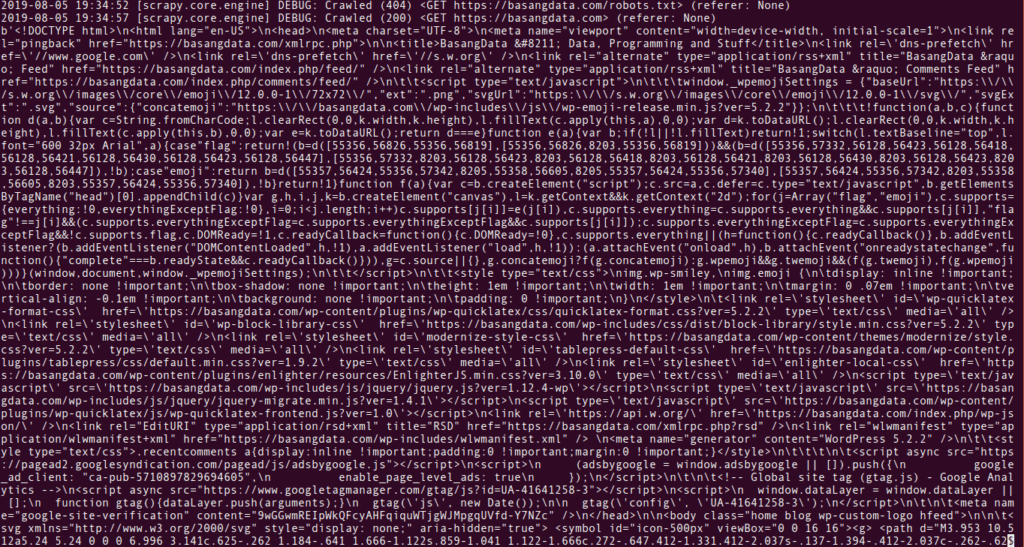
Di atas adalah file html dari halaman basangdata yang jika mengikuti tutorial resmi dari scrapy, file html tersebut disimpan dalam harddisk.
Karena kita hanya ingin mendapatkan judul artikel dan tahu tag html yang mengandung judul tersebut, maka kita ganti judul_spider.py menjadi seperti ini (perubahan pada fungsi parse).
import scrapy
class JudulSpider(scrapy.Spider):
name = "judul"
def start_requests(self):
urlBasang = "https://basangdata.com"
yield scrapy.Request(url = urlBasang, callback = self.parse)
def parse(self, response):
for j in response.xpath('//h2[contains(@class, "entry__title")]/a'):
print(j.xpath('text()').extract_first())
Xpath berguna untuk memilih tag html, yang dalam kode di atas //h2[contains(@class, “entry__title”)]/a yaitu bermakna: ambil semua tag h2 yang mengandung kelas entry__title lalu ambil satu tag a. Saat menggunakan xpath, beda antara dua tanda // (ambil semua) dan satu tanda / (ambil satu) karena itu kita perlu memperhatikan tanda itu. Lalu baris selanjutnya.
print(j.xpath('text()').extract_first())
xpath(‘text()’) bermakna ambil teks (dari elemen dalam variabel j). Kemudian extract_first() maksudnya ekstraksi elemen pertama. Hasil ekstraksi tersebut, tampilkan (print).
Jika spider di atas dieksekusi lagi dengan perintah scrapy crawl judul, lalu scroll ke bawah sedikit, maka hasilnya.

Hurray!
Kita berhasil mendapatkan judul artikel dalam halaman basangdata. Jika ingin menyimpan hasil tersebut dalam sebuah file csv, spider dapat dimodifikasi menjadi seperti ini.
import scrapy
class JudulSpider(scrapy.Spider):
name = "judul"
def start_requests(self):
urlBasang = "https://basangdata.com"
yield scrapy.Request(url = urlBasang, callback = self.parse)
def parse(self, response):
newCsv = open('judulartikel.csv', 'a')
for j in response.xpath('//h2[contains(@class, "entry__title")]/a'):
newCsv.write(j.xpath('text()').extract_first() + "\n")
newCsv.close()
Seperti biasa kita eksekusi spider dengan perintah scrapy crawl judul lalu hasilnya kita mendapat file bernama judulartikel.csv dengan isi sebagai berikut.
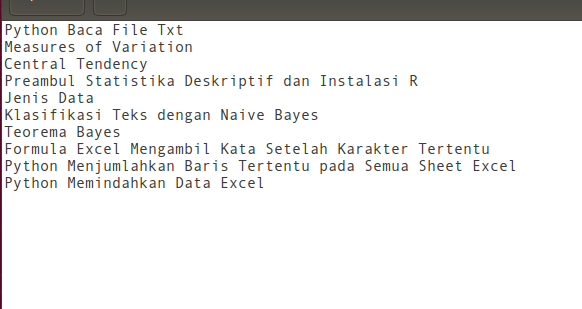
Hurray!
Pada tulisan berikutnya kita akan mengeksplorasi lebih lanjut mengenai web scraping ini, seperti mengambil data dari halaman web yang berhalaman-halaman, menggunakan selector selain xpath dan lain sebagainya.
Salam.
Cover Photo by Pixabay from Pexels
Lebih lanjut:
- https://devhints.io/xpath
- https://docs.scrapy.org/en/latest/intro/tutorial.html
- https://www.w3schools.com/xml/xpath_syntax.asp
saya ada masalah saat install scrapy
muncul banyak tulisan berwarna merah, salah satu barisnya:
error: Microsoft Visual C++ 14.0 is required. Get it with “Build Tools for Visual Studio”: https://visualstudio.microsoft.com/downloads/
Kemudian saya coba mendownload dan install vcredist
tapi masih tetap error?
hmmm…
Saya pernah bermasalah yg sama saa akan menggunakan Jupyter Lab (https://basangdata.com/instalasi-jupyter-lab-pada-windows/). Solusi saya adalah menginstall Anaconda (https://www.anaconda.com/products/individual) dan melakukan instalasi scrapy dari Anaconda Prompt.
Saya make anaconda ga bisa bisa
Hi, boleh dielaborasi lebih panjang mengenai permasalahan yang dihadapi?