
Python Mencari Kalimat Mirip dalam Data Excel
Setelah berhasil membuat dan mengubah file Excel menggunakan Python, mari mulai mencari studi kasus yang lebih mudah dikerjakan dengan bantuan Python alih-alih hanya Excel. Selalu menggunakan Python untuk semua kasus atau sebaliknya, menggunakan Excel saja untuk semua masalah yang dihadapi, adalah tidak efisien, gunakan alat yang tepat untuk masing-masing kondisi agar kita dapat segera meninggalkan layar komputer dan melanjutkan hidup. Hehehe.
Di grup Excel diberikan soal seperti ini, jika ada nama pada kolom H yang mirip dengan nama pada kolom F, tampilkan nilai kolom I pada kolom G. Jika nama pada kolom H dan F sama maka kita dapat dengan mudah menggunakan fungsi vlookup. Namun vlookup sensitif sekali, beda satu spasi saja tidak akan menghasilkan keluaran yang kita harapkan apalagi untuk sekedar mirip. Di saat beginilah kita memerlukan bantuan teknologi lain.
Microsoft sendiri sudah menyediakan sebuah add-in yang dapat digunakan, Fuzzy Lookup yang dapat didownload di sini. Namun seorang rekan di grup melaporkan terjadi kesalahan dalam instalasi yang sepertinya terjadi karena ketiadaan paket Dot Net Framework yang dibutuhkan oleh add-in tersebut.
Kita akan mencoba menggunakan Python untuk mencapai tujuan di atas. Hal yang pertama perlu dilakukan adalah meng-googling solusi yang ditawarkan Python untuk ini. Gunakan keyword python text similarity di Google, jangan lupa untuk selalu menggunakan Bahasa Inggris saat menggunakan mesin pencari.
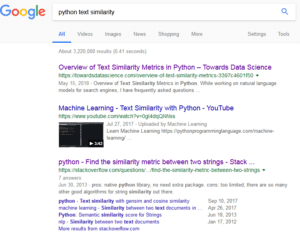
Jawaban pertama sepertinya komprehensif, kita jadi punya wacana tentang metode mengukur kemiripan teks, lengkap dengan kode Python yang cukup panjang, kita akan simpan pranala tersebut untuk referensi di masa depan. Untuk sekarang lebih baik kita cari yang berkode pendek.
Hasil kedua adalah pranala Youtube berjudul Machine Learning, kata yang menarik, kita akan ingat itu, Machine Learning. Tapi untuk saat ini kita lewati dulu situs video pemakan kuota.
Jawaban ketiga dari Stack Overflow, sudah beberapa kali situs ini muncul di halaman pertama, hmm, sepertinya situs ini populer di kalangan pembuat kode. Jawaban pertanyaan pada situs ini mengesankan, hanya 3 baris kode, kita coba yang ini saja.
Oya, sebagai selingan, saya menyarankan untuk menggunakan teks editor selain notepad. Gunakan misalnya notepad++ yang dapat didownload di sini. Buat saya, keuntungan utama menggunakan teks editor yang umum digunakan pemrogram komputer adalah adanya nomor baris. Sering terjadi kesalahan pada kode dan Python mengeluarkan error message disertai nomor baris yang bermasalah. Jika menggunakan notepad tentu kita akan kesulitan mencari sumber masalah tersebut.
Kita akan melakukan instalasi notepad++, setelah didownload, klik dua kali dan 3NF (Next, Next, Next, Finish).

Selanjutnya kita akan mulai membuat kode untuk membuat vlookup ala-ala, silahkan download di sini untuk file Excel berisi data di atas, simpan dalam folder d:\latihan_excel_python.
Mulai dari yang sederhana dulu, kita akan membuat kode dengan algoritma seperti ini.
- Buka file Excel.
- Baca kolom F dari baris 2 sampai selesai.
- Saat melakukan langkah #2 (membaca kolom F), baca kolom H dari baris 2 sampai selesai.
- Saat melakukan langkah #3 bandingkan apakah mirip antara kolom F baris n dengan kolom H baris m (2 sampai selesai).
- Simpan nilai kemiripan pada langkah #4 dalam variable bernama similar.
- Jika nilai similar pada kolom H baris m + 1 lebih besar dari nilai similar pada kolom H baris m, ganti nilai similar menjadi nilai similar pada kolom H baris m + 1. Selain itu simpan nama di kolom H baris m + 1 pada variabel similar_text.
- Setelah selesai membaca kolom H, tulis nilai similar pada kolom K, tulis variable similar_text pada kolom L.
- Setelah selesai membaca kolom F, simpan file Excel dengan nama d:\latihan_excel_python\contoh_kemiripan_pertama.xlsx.
Kodenya seperti berikut.
from openpyxl import load_workbook
from openpyxl import Workbook
from difflib import SequenceMatcher
wb = load_workbook('d:\\latihan_excel_python\\contoh_kemiripan.xlsx', data_only = True)
ws = wb.active
max_row_f = ws.max_row + 1
max_row_h = ws.max_row + 1
for row_f in range(2, max_row_f):
similar = 0.0
similar_text = ''
for row_h in range(2, max_row_h):
sim = SequenceMatcher(None, ws['F' + str(row_f)].value, ws['H' + str(row_h)].value).ratio()
if sim > similar:
similar = sim
similar_text = ws['H' + str(row_h)].value
ws['K' + str(row_f)] = similar
ws['L' + str(row_f)] = similar_text
wb.save('d:\\latihan_excel_python\\contoh_kemiripan_pertama.xlsx')
Simpan di d:\latihan_excel_python\vlookup_ala_ala_pertama.py kemudian jalankan dengan mengetik python d:\latihan_excel_python\vlookup_ala_ala_pertama.py lalu Enter.
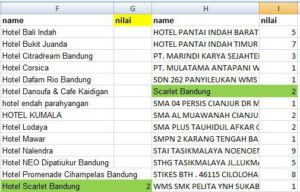
Hasilnya adalah file contoh_kemiripan_pertama.xlsx berisi seperti berikut.
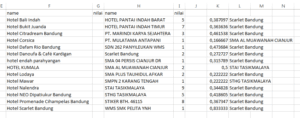
Cara membaca hasilnya seperti ini, pada baris 2, kolom K berisi nilai kemiripan paling tinggi antara kolom F baris 2 dengan kolom H baris 2 sampai akhir. Skor kemiripan (kolom F baris 2 dengan kolom H baris 2 sampai akhir) paling tinggi adalah 0,38. Kata Hotel Bali Indah (kolom F) dianggap paling mirip (skor kemiripan 0,38) dengan kata Scarlet Bandung (dari kolom H baris 7). Kita mengevaluasi hasil itu, terlalu jauh kemiripannya, kalau begitu coba lihat yang skor kemiripannya paling tinggi yaitu baris 15.
Kolom F baris 15 berisi kata Hotel Scarlet Bandung yang dianggap mirip dengan kata Scarlet Bandung (kolom H baris 7) dengan skor kemiripan 0,83. Berarti skor 0,83 dapat kita terima sebagai mirip. Kita coba skor di tengah antara 0,38 (tidak mirip) dan 0,83 (mirip), misalnya 0,47 pada baris 6. Pada baris 6 tersebut kata Hotel Dafam Rio Bandung dianggap mirip dengan kata Scarlet Bandung dengan skor kemiripan 0,47.
Hmm, sepertinya skor 0,47 pun tidak memadai untuk kita (manusia) anggap mirip. Jika melihat skor 0,5 pada baris 9 yang berisi kata HOTEL KUMALA dan STAI TASIKMALAYA juga belum cukup mirip. Dengan begitu kita putuskan skor yang kita terima sebagai mirip dalam data yang kita miliki adalah minimal 0,83. Proses ini, memutuskan menerima skor berapa sebagai mirip, harus dilakukan oleh manusia, bukan komputer karena pada dasarnya komputer bodoh sekali dan harus diajari manusia untuk melakukan sesuatu. Namun komputer dapat bekerja berulang-ulang selama 24/7 tanpa lelah yang merupakan keunggulannya melebihi manusia.
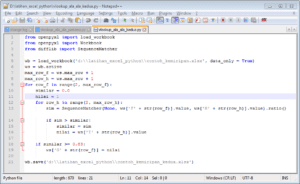
Algoritma di atas kita ubah untuk hanya menampilkan kata dengan skor kemiripan minimal 0,83. Kode yang diperbaiki diberi nama d:\latihan_excel_python\vlookup_ala_ala_kedua.py dengan isi.
from openpyxl import load_workbook
from openpyxl import Workbook
from difflib import SequenceMatcher
wb = load_workbook('d:\\latihan_excel_python\\contoh_kemiripan.xlsx', data_only = True)
ws = wb.active
max_row_f = ws.max_row + 1
max_row_h = ws.max_row + 1
for row_f in range(2, max_row_f):
similar = 0.0
nilai = 1
for row_h in range(2, max_row_h):
sim = SequenceMatcher(None, ws['F' + str(row_f)].value, ws['H' + str(row_h)].value).ratio()
if sim > similar:
similar = sim
nilai = ws['I' + str(row_h)].value
if similar >= 0.83:
ws['G' + str(row_f)] = nilai
wb.save('d:\\latihan_excel_python\\contoh_kemiripan_kedua.xlsx')
Kita sedikit merubah kode, antara lain, buat variable nilai yang diisi nilai default 1, variable ini akan menampung berapapun nilai dari kolom I jika skor kemiripan baris m + 1 lebih tinggi dari skor kemiripan baris m. Lalu baris if similar >= 0.83 artinya jika skor minimal 0,83 lakukan ini, isi kolom G baris n dengan variable nilai.
Jalankan dengan ketik python d:\latihan_excel_python\vlookup_ala_ala_kedua.py lalu Enter di Command Prompt.
Hasilnya file Excel bernama contoh_kemiripan_kedua.xlsx, kita buka.

Mantul lagi, sekarang Hotel Scarlet Bandung pada kolom F menampilkan angka 2 di kolom G, sama seperti nilai pada kolom I. Kita telah berhasil membuat mirip fungsi vlookup, hanya saja tanpa harus sama persis kata/kalimatnya.
Semoga bermanfaat. Jika ada pertanyaan atau saran mengenai kasus lain, silahkan berkomentar.
Salam.
One Reply to “Python Mencari Kalimat Mirip dalam Data Excel”