

Forensic Analytics dengan Pandas – The Subset Number Duplication Test
Tiap kelompok/subset angka (misal data penjualan per toko cabang, data pengajuan klaim asuransi per tenaga pemasar) umumnya memiliki duplikasi angka seragam. Sehingga bila terdapat kelompok yang memiliki duplikasi angka yang lebih tinggi maka perlu diperhatikan karena hal tersebut dapat mengindikasikan adanya fraud.
Kode Lima Detik
import numpy as np
import pandas as pd
pd.options.display.float_format = '{:,.2f}'.format
df = pd.read_excel('https://www.nigrini.com/ForensicAnalytics/Chapter4_Figure4pt4_DataOnly.xlsx')
data = df[df['Amount'] >= 100][['ID', 'VendorNum', 'Amount']]
n = data[['ID', 'VendorNum']].groupby('VendorNum', as_index=False).count()
n.rename(columns={'ID': 'n'}, inplace=True)
n['n2'] = pow(n['n'], 2)
data = data.merge(n, how='left', on='VendorNum')
data = data[data['n'] > 1]
minmax = data[['Amount', 'VendorNum']].groupby('VendorNum').agg(min_amount=('Amount', np.min), max_amount=('Amount', np.max))
minmax.reset_index(level=0, inplace=True)
data = data.merge(minmax, how='left', on='VendorNum')
data['sum_amount'] = data['Amount']
sumamount = data[['Amount', 'VendorNum', 'sum_amount']].groupby(['VendorNum', 'Amount'], as_index=False).sum()
data = data.iloc[:,:7].merge(sumamount, how='left', on=['VendorNum', 'Amount'])
c = data[['Amount', 'VendorNum', 'ID']].groupby(['VendorNum', 'Amount'], as_index=False).count()
c.rename(columns={'ID': 'c'}, inplace=True)
c['c2'] = pow(c['c'], 2)
data = data.merge(c, how='left', on=['VendorNum', 'Amount'])
nodup = data.drop_duplicates(subset=['VendorNum', 'Amount'])
sumc = nodup[['c2', 'VendorNum']].groupby(['VendorNum'], as_index=False).sum()
sumc.rename(columns={'c2': 'sumc2'}, inplace=True)
data = data.merge(sumc, how='left', on=['VendorNum'])
data['nff'] = data['sumc2'] / data['n2']
data.drop_duplicates(subset=['VendorNum', 'Amount'], inplace=True)
data.sort_values(by=['nff', 'sum_amount'], ascending=False).head(20)[['VendorNum', 'Amount', 'min_amount', 'max_amount', 'sum_amount', 'nff']]
The Subset Number Duplication Test
Sebagai auditor internal, Anda telah akrab dengan data pembelian perusahaan. Namun entah kenapa pagi ini Anda merasakan sesuatu yang berbeda saat menatap baris-baris data pembelian. Bolak-balik tetikus di-scroll, data turun jauh, lalu perlahan naik lagi, turun lagi sejauh yang bisa dijangkau kemudian naik lagi.
Anda merasa ada pola tertentu, tapi kesulitan mencernanya. Terasa seperti ada sesuatu yang berulang-ulang Anda lihat, sesuatu yang menimbulkan perasaan aneh, terasa mengancam.
Anda telah melakukan berbagai pengujian dari menggambar grafik, Benford’s Law, angka duplikat, angka mirip hingga angka hampir mirip.
Masing-masing memberikan temuan yang berbeda, beberapa merupakan kesalahan administrasi yang wajar dan ada sebagian tindakan melawan hukum, yang telah diproses.
Tapi Anda merasa ada hal lain yang belum terungkap, sesuatu berkenaan dengan pola-pola pada data.
Deskripsi
Pak Nigrini menawarkan satu lagi metode pengujian data duplikat, The Subset Number Duplication Test.
Menggunakan metode ini, data dikelompokkan kemudian dikuantifikasi derajat duplikasinya. Makin tinggi derajat duplikasi, makin perlu perhatian suatu kelompok.
Ide utama dari metode ini adalah makin tidak beragam angka yang dimiliki oleh suatu kelompok data, makin mencurigakan kelompok tersebut.
Misal data di bawah adalah hasil penjualan harian es tebu pada dua tenaga pemasar selama dua pekan (dalam ribuan).
![\[A = \{200, 300, 240, 190, 200, 205, 215, 210, 225, 180, 210, 250, 150, 170\}\]](https://basangdata.com/wp-content/ql-cache/quicklatex.com-474bf81c53c0f36e9273db29be04ca12_l3.png "Rendered by QuickLaTeX.com")
![\[B = \{220, 220, 195, 190, 220, 215, 220, 250, 230, 230, 220, 190, 180, 220\}\]](https://basangdata.com/wp-content/ql-cache/quicklatex.com-c65e8d979cbf9be79f8f0aa33523bf20_l3.png "Rendered by QuickLaTeX.com")
Secara intuitif Anda lebih mudah mencurigai B karena punya banyak angka yang sama, yaitu 220.
Menariknya, oleh Pak Nigrini intuisi kita dikuantifikasi dengan rumus berikut.
![\[ Number\; Frequency\; Factor = \frac{\Sigma c_i^2}{n^2} \]](https://basangdata.com/wp-content/ql-cache/quicklatex.com-22b84a7ed26b81305395ba1a902fc198_l3.png "Rendered by QuickLaTeX.com")
Dimana:
 = Berapa kali kemunculan masing-masing angka, namun hanya angka dengan kemunculan
= Berapa kali kemunculan masing-masing angka, namun hanya angka dengan kemunculan  yang kita gunakan
yang kita gunakan
 = Berapa banyak angka dalam kelompok
= Berapa banyak angka dalam kelompok
Sehingga untuk tenaga pemasar A, nilai Number Frequency Factor (NFF) dihitung dengan langkah berikut. Pertama dapatkan banyak kemunculan () masing-masing angka.
| Angka | Banyak Kemunculan () |
| 200 | 2 |
| 300 | 1 |
| 240 | 1 |
| 190 | 1 |
| 205 | 1 |
| 215 | 1 |
| 210 | 2 |
| 225 | 1 |
| 180 | 1 |
| 250 | 1 |
| 150 | 1 |
| 170 | 1 |
| n | 14 |
Karena hanya angka dengan kemunculan yang digunakan, maka hanya angka 200 dan 210, yang masing-masing bernilai 2, yang akan dihitung pada NFF.
![\[NFF = \frac{2^2 + 2^2}{14^2}\]](https://basangdata.com/wp-content/ql-cache/quicklatex.com-452db2e67a21a80b4e1693ca9c4bafc5_l3.png "Rendered by QuickLaTeX.com")
![\[NFF = \frac{8}{196} = 0,04\]](https://basangdata.com/wp-content/ql-cache/quicklatex.com-1c9fc2a75da12eba65a48cf7261ad054_l3.png "Rendered by QuickLaTeX.com")
Sekarang kita hitung tenaga pemasar B.
| Angka | Banyak Kemunculan () |
| 220 | 6 |
| 195 | 1 |
| 190 | 2 |
| 215 | 1 |
| 250 | 1 |
| 230 | 2 |
| 180 | 1 |
| n | 14 |
Sebagai pembilang (angka yang akan dibagi) kita gunakan angka 220, 190 dan 180 karena 3 angka tersebut berulang kemunculannya.
![\[NFF = \frac{6^2 + 2^2 + 2^2}{14^2}\]](https://basangdata.com/wp-content/ql-cache/quicklatex.com-193d53e0b5cbec229cbaf3760c60f5e3_l3.png "Rendered by QuickLaTeX.com")
![\[NFF = \frac{44}{196} = 0,22\]](https://basangdata.com/wp-content/ql-cache/quicklatex.com-e26668e5eada86b00429b926956e4dd2_l3.png "Rendered by QuickLaTeX.com")
Nilai NFF B lebih besar dari A ( ) sehingga dapat disimpulkan.
) sehingga dapat disimpulkan.
Makin banyak kemunculan angka yang sama (duplikasi) maka makin tinggi nilai NFF.
Pada kasus yang ekstrim jika selama dua minggu hasil penjualan tenaga pemasar C selalu sebesar 200 maka nilai NFF adalah 1.
![\[NFF = \frac{14^2}{14^2} = 1\]](https://basangdata.com/wp-content/ql-cache/quicklatex.com-83ca8a4ccb4484bdeaae43e328991b6a_l3.png "Rendered by QuickLaTeX.com")
Sebaliknya jika tidak terdapat duplikasi angka maka pembilang bernilai 0 sehingga nilai NFF sebesar 0.
![\[NFF = \frac{0}{14^2} = 0\]](https://basangdata.com/wp-content/ql-cache/quicklatex.com-546c32adbacad0f6372d2e8fb191aa24_l3.png "Rendered by QuickLaTeX.com")
Aplikasi
Secara umum manusia tidak benar-benar dapat memproduksi nomor acak. Demikian pula pelaku fraud, mereka tidak lepas dari masalah itu. Karena itu mereka cenderung untuk menggunakan angka yang sama berulang-ulang.
Apalagi fraudsters memiliki batasan nilai maksimal dan minimal yang dapat digunakan. Pada contoh tenaga pemasar es tebu di atas, jika benar ada diantara mereka yang menyunat hasil penjualan.
Ia harus melaporkan angka penjualan yang cukup besar nilainya sehingga tidak mudah menerbitkan kecurigaan. Namun angka tersebut tidak boleh terlalu kecil (mendekati angka penjualan sebenarnya) sehingga hasil rasuah tidak sepadan dengan risiko yang ditanggung.
Selain mendeteksi angka yang dibuat untuk mencurangi penjualan es tebu di atas, The Subset Number Duplication Test sangat berguna pada beberapa skenario.
- Perusahaan minyak bumi memiliki banyak tagihan sebesar $600 dari operator helikopter sebagai upah untuk mengantar ke rig. Investigasi selanjutnya menemukan bahwa beberapa pegawai menyukai perjalanan tersebut sehingga menyalahgunakan fasilitas itu.
- Jaringan retail ATK nasional menguji data rincian penjualan per kasir. Tujuannya untuk menemukan kasir yang sering membukukan item penjualan bernilai kecil (misal sebesar $0,1) kemudian mengantongi selisih antara nilai pembayaran (misal $16,0) dan item penjualan tersebut. Beberapa kasir diketahui melakukan kecurangan tersebut.
- Daftar penggunaan purchasing card menunjukkan 4 transaksi dengan nilai sama ($2.500) pada penyedia yang sama dan tanggal yang sama. Belakangan diketahui bahwa 1 tagihan hotel sebesar $10.000 dibayarkan 4 kali menggunakan purchasing card yang sama karena batasan penggunaannya sebesar $2.500.
Langkah Kerja
Pagi berikutnya Anda kembali duduk di depan komputer namun kali ini dengan rencana berbeda, alih-alih hanya duduk terpaku melihat layar gelas.
Semalam Anda telah membaca Forensic Analytics, sudah melatih penggunaan The Subset Number Duplication Test pada laporan penjualan es tebu Anda (selain merupakan internal auditor Anda juga memiliki status lain sebagai pengusaha es tebu). Dan sudah menyempatkan memecat salah satu tenaga pemasar Anda setelah memastikan dia telah menjalankan skema cerdasnya selama 4 bulan berkarir.
Anda sudah tahu akan menjalankan pengujian pada data pembelian yang dikelompokkan berdasarkan penyedia. Karena Anda menyukai pandas sebagai alat bantu mengolah data maka teknologi itu yang akan digunakan. Dan sekarang saatnya membuktikan apakah The Subset Number Duplication Test merupakan jawaban atas keresahan kemarin.
Kode
Langkah yang akan Anda kerjakan kurang lebih:
- Memfilter data hanya

- Menghitung banyak transaksi masing-masing penyedia
- Menghitung banyak kemunculan angka yang sama masing-masing penyedia
- Menghitung NFF
- Menampilkan 20 NFF tertinggi
Load library dan data
import numpy as np
import pandas as pd
pd.options.display.float_format = '{:,.2f}'.format
df = pd.read_excel('https://www.nigrini.com/ForensicAnalytics/Chapter4_Figure4pt4_DataOnly.xlsx')
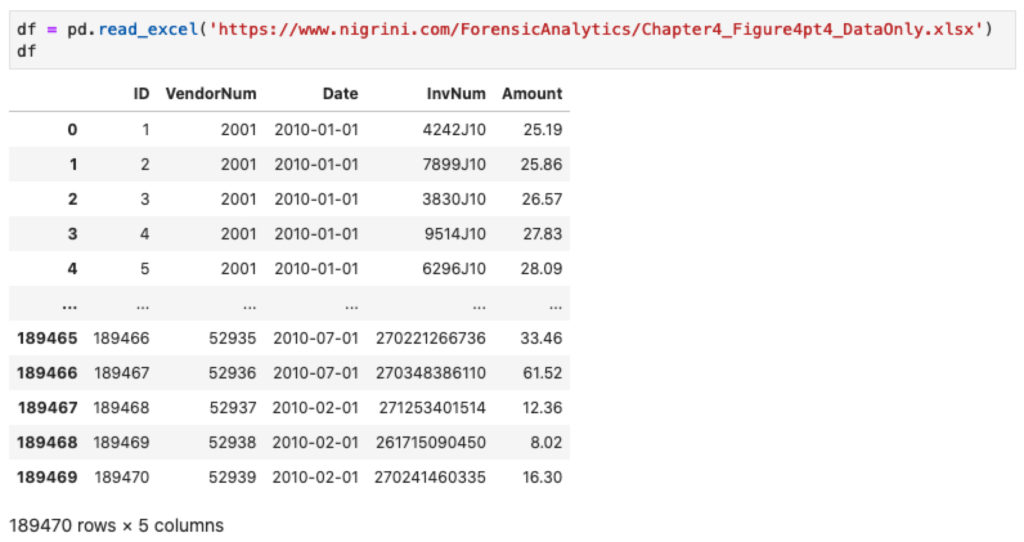
Data pembelian terdiri dari 189.470 baris dengan 5 kolom. Anda ingin mengetahui nilai NFF pada masing-masing penyedia (VendorNum). Angka yang diuji adalah angka pada kolom Amount.
Selain pandas, Anda juga menggunakan numpy yang akan digunakan untuk mendapatkan nilai minimum dan maksimum. Untuk load data Anda menggunakan fungsi read_excel dari pandas.
Hanya gunakan nilai Amount  dan kolom tertentu
dan kolom tertentu
data = df[df['Amount'] >= 100][['ID', 'VendorNum', 'Amount']]
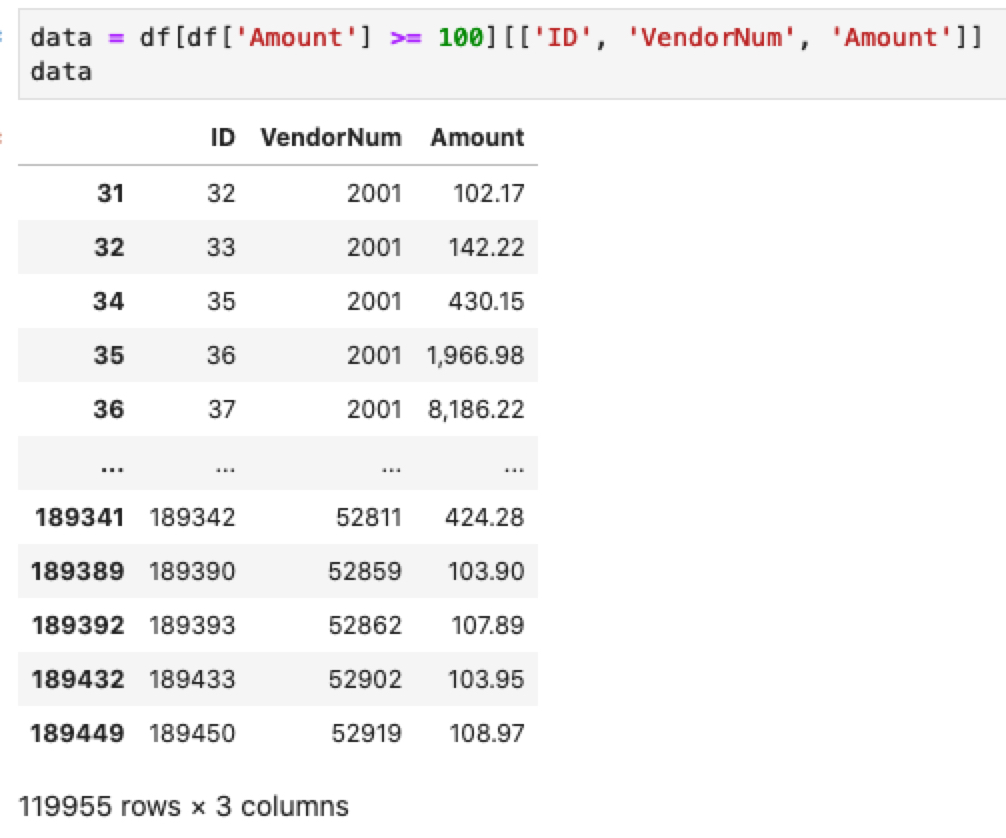
Anda ingin rasional, melakukan pengujian pada transaksi bernilai kecil berisiko lebih besar biaya pengujian ketimbang nilai temuannya. Karena itu Anda membatasi hanya memproses pembelian senilai minimal 100.
Dapatkan banyak transaksi masing-masing penyedia
n = data[['ID', 'VendorNum']].groupby('VendorNum', as_index=False).count()
n.rename(columns={'ID': 'n'}, inplace=True)
n['n2'] = pow(n['n'], 2)
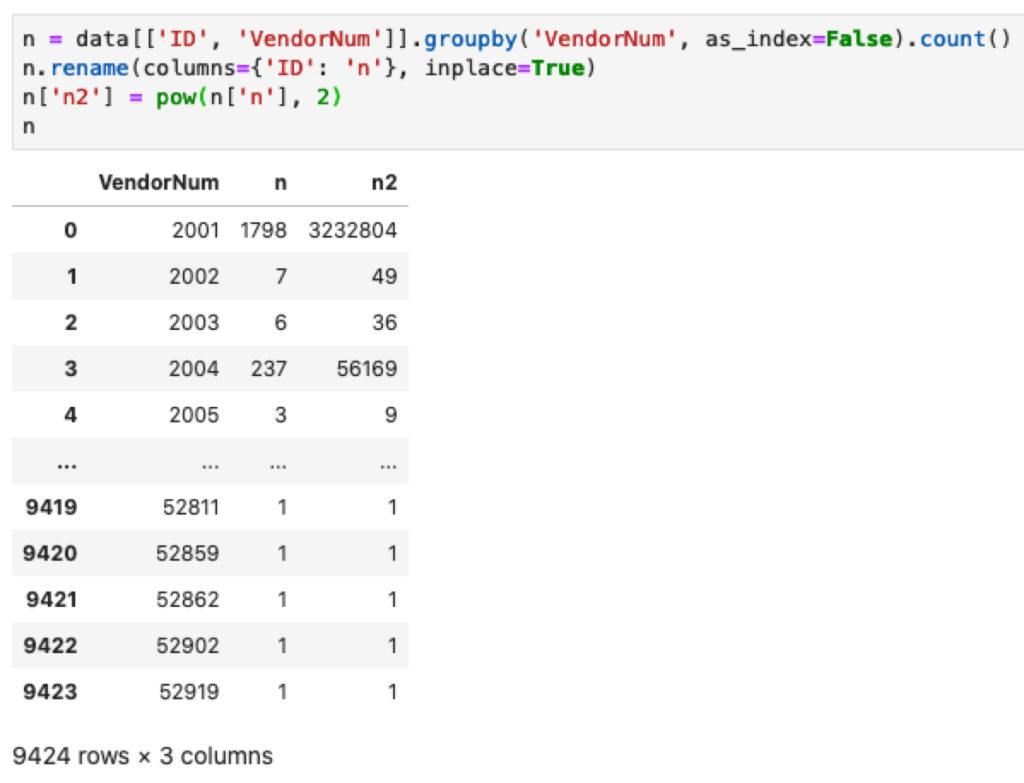
Fungsi groupby digunakan untuk menggabungkan pembelian berdasarkan penyedia (VendorNum) kemudian dihitung jumlah data pada masing-masing penyedia menggunakan count.
Agar lebih informatif kolom ID diganti namanya menjadi n menggunakan fungsi rename.
Python menyediakan fungsi pow untuk menghitung pangkat angka, Anda menggunakan itu untuk mendapatkan kolom n2.
Gabungkan data
data = data.merge(n, how='left', on='VendorNum')
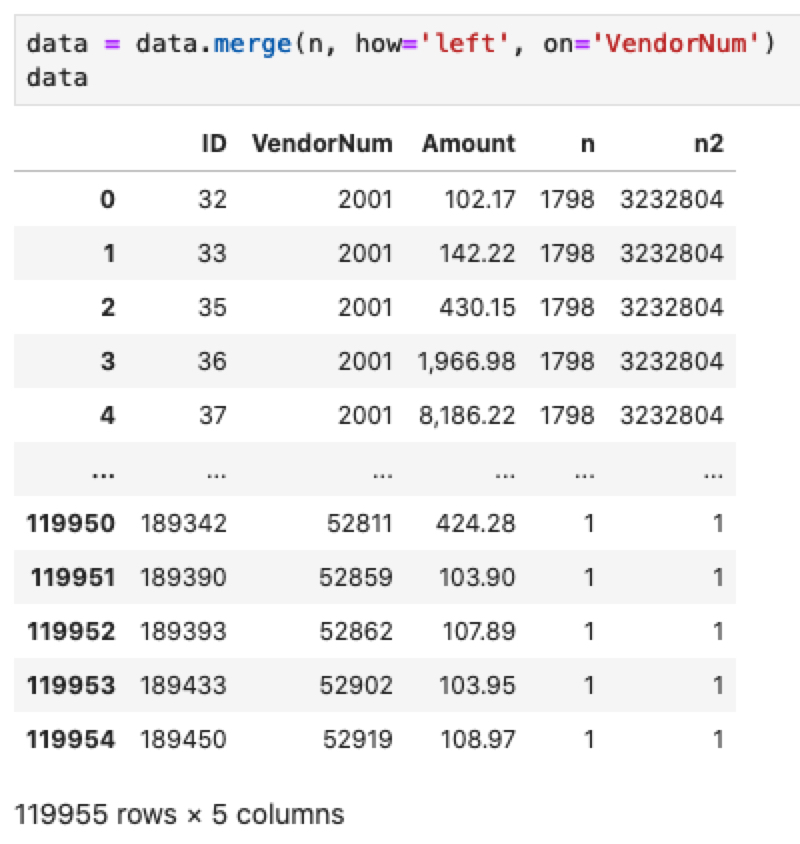
Setelah mendapatkan banyaknya transaksi (n) per penyedia, data tersebut digabungkan dengan data utama menggunakan fungsi merge. Karena yang dibutuhkan adalah  maka langkah selanjutnya adalah memfilter hanya
maka langkah selanjutnya adalah memfilter hanya
Hanya gunakan
data = data[data['n'] > 1]
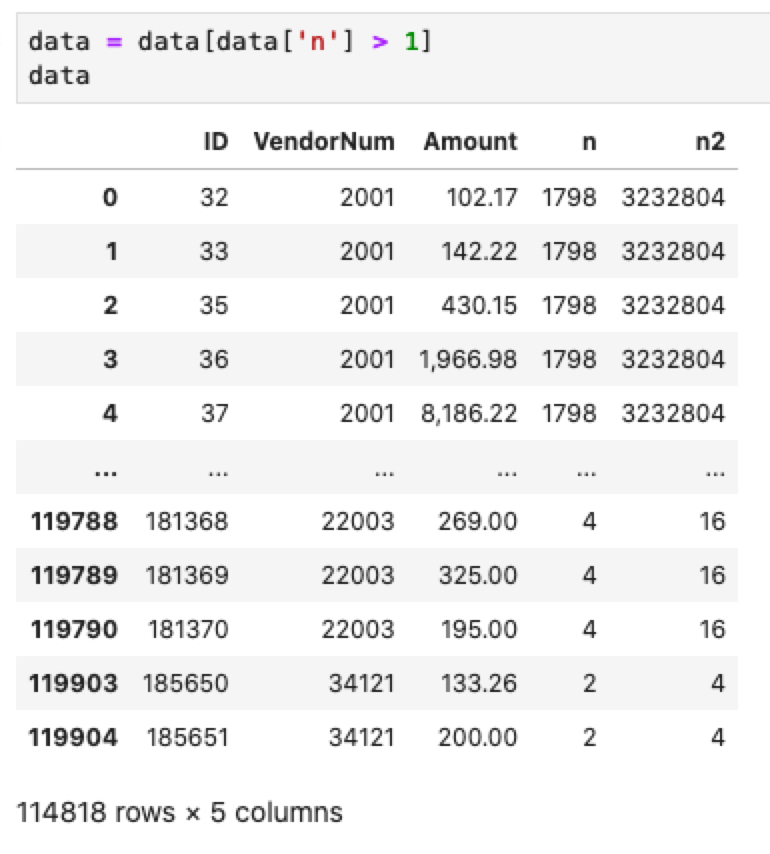
Dapatkan nilai min dan max masing-masing penyedia
minmax = data[['Amount', 'VendorNum']].groupby('VendorNum').agg(min_amount=('Amount', np.min), max_amount=('Amount', np.max))
minmax.reset_index(level=0, inplace=True)
data = data.merge(minmax, how='left', on='VendorNum')
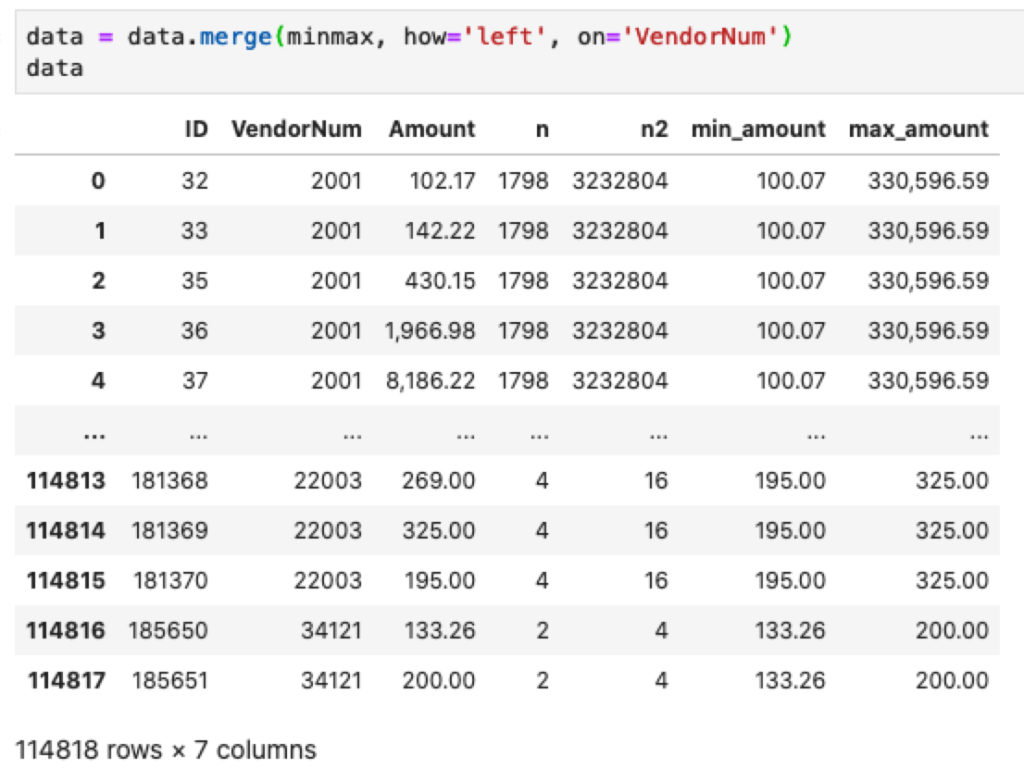
Angka yang digunakan adalah angka yang kemunculannya  sehingga Anda membuat sebuah variabel baru bernama dup yang berisi data yang memiliki duplikat pada kolom VendorNum dan Amount.
sehingga Anda membuat sebuah variabel baru bernama dup yang berisi data yang memiliki duplikat pada kolom VendorNum dan Amount.
Dapatkan total nilai masing-masing Amount per masing-masing penyedia
data['sum_amount'] = data['Amount'] sumamount = data[['Amount', 'VendorNum', 'sum_amount']].groupby(['VendorNum', 'Amount'], as_index=False).sum() data = data.iloc[:,:7].merge(sumamount, how='left', on=['VendorNum', 'Amount'])
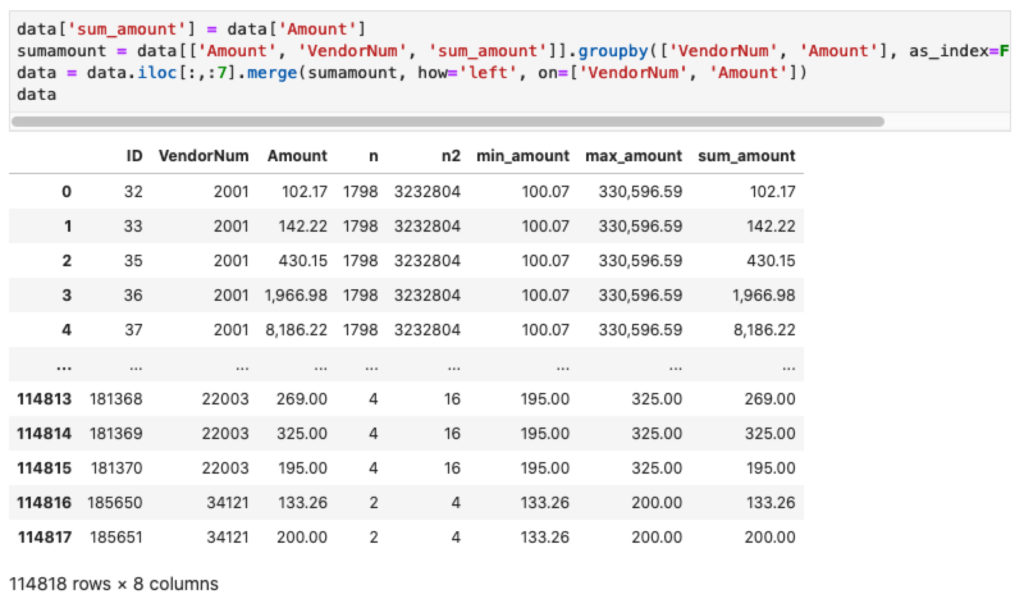
Dapatkan jumlah kemunculan angka
c = data[['Amount', 'VendorNum', 'ID']].groupby(['VendorNum', 'Amount'], as_index=False).count()
c.rename(columns={'ID': 'c'}, inplace=True)
c['c2'] = pow(c['c'], 2)
data = data.merge(c, how='left', on=['VendorNum', 'Amount'])
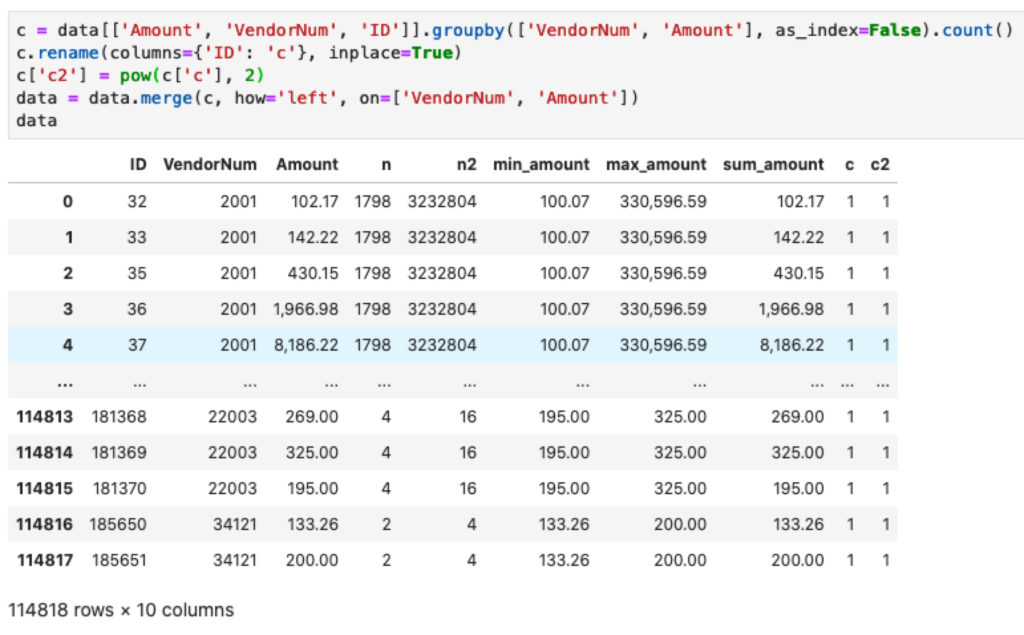
Sampai di sini Anda sudah memiliki nilai ,  ,
,  dan yang terbaru
dan yang terbaru  .
.
Hapus duplikasi data berdasarkan VendorNum dan Amount
nodup = data.drop_duplicates(subset=['VendorNum', 'Amount'])
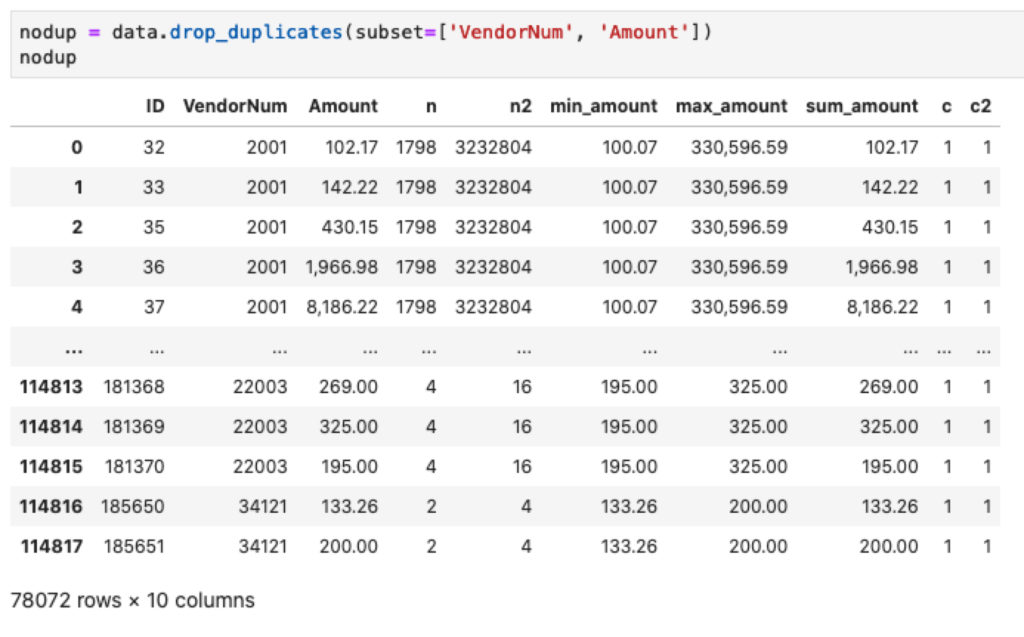
Menggunakan fungsi drop_duplicates Anda hanya mengambil satu data yang duplikat pada kolom VendorNum dan Amount.
Dapatkan jumlah kemunculan angka masing-masing penyedia
sumc = nodup[['c2', 'VendorNum']].groupby(['VendorNum'], as_index=False).sum()
sumc.rename(columns={'c2': 'sumc2'}, inplace=True)
data = data.merge(sumc, how='left', on=['VendorNum'])
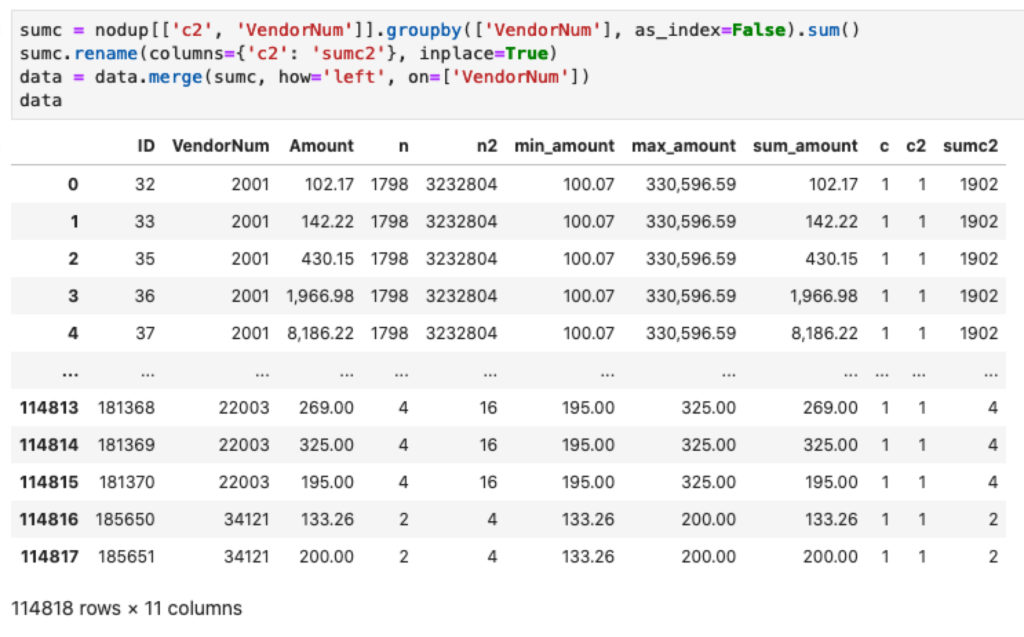
Kode di atas untuk mendapatkan  atau pembilang.
atau pembilang.
Dapatkan NFF
data['nff'] = data['sumc2'] / data['n2']
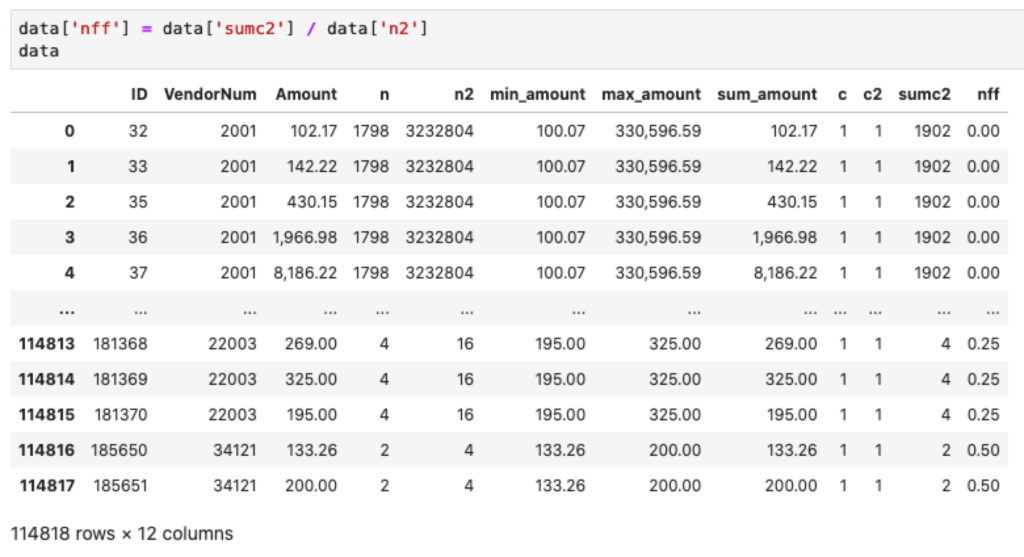
Hapus duplikasi data berdasarkan VendorNum dan Amount
data.drop_duplicates(subset=['VendorNum', 'Amount'], inplace=True)
Tampilkan 20 nilai teratas
data.sort_values(by=['nff', 'sum_amount'], ascending=False).head(20)[['VendorNum', 'Amount', 'min_amount', 'max_amount', 'sum_amount', 'nff']]
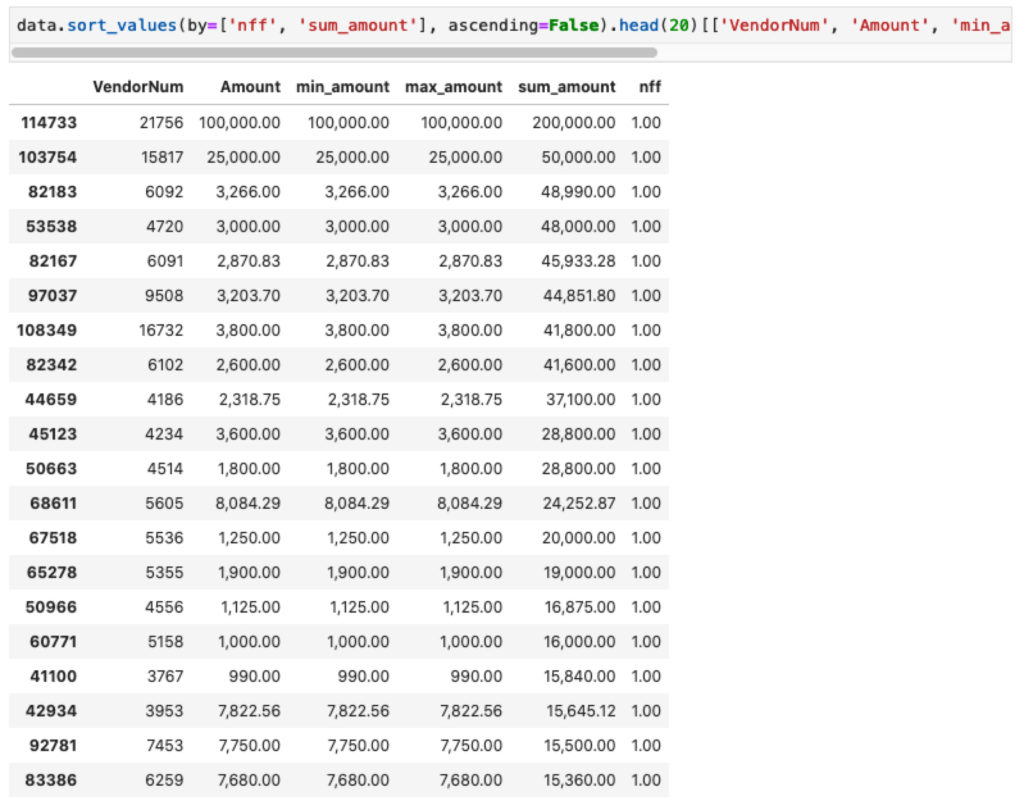
Selanjutnya
Anda sudah mendapatkan top 20 pembelian dengan derajat duplikasi tertinggi. Investigasi lebih lanjut dilakukan untuk memastikan transaksi tersebut adalah transaksi yang sah atau tidak.
Salah satu kondisi yang mungkin terjadi adalah pembelian fiktif dilakukan dengan pura-pura melakukan pemesanan pada penyedia (VendorNum) yang tidak aktif kemudian memproduksi semua dokumen yang dibutuhkan.
Karena menurut Anda memecat satu orang pagi ini sudah memenuhi dosis harian, Anda berharap tidak ada lagi orang yang akan kehilangan pekerjaan hari ini. Diam-diam Anda berdoa agar semua transaksi yang ada dalam daftar merupakan transaksi yang sah.
Konklusi
The Subset Number Duplication Test dapat memberikan derajat duplikasi dalam bentuk angka. Berdasarkan derajat tersebut kita dapat memfokuskan investigasi pada kelompok data yang memiliki banyak duplikasi data.
Kecenderungan manusia yang kesulitan membuat angka acak, ditambah dengan batasan maksimal dan minimal yang dihadapi pelaku fraud menyebabkan angka/nilai yang digunakan fraudster cenderung sama dari waktu ke waktu. Kita tinggal mengidentifikasi angka-angka tersebut menggunakan The Subset Number Duplication Test.
Tinggalkan komentar Anda jika memiliki pengalaman serupa atau memiliki ide lain untuk menggunakan The Subset Number Duplication Test.