

Eksplorasi Data dengan Pandas – Rencana Pengadaan 2020 Terbesar
Tertarik ikut mengajukan penawaran pada proyek pemerintah, ingin tahu proyek apa saja yang paling besar nilainya? Atau sekedar ingin tahu hal menarik yang bisa kita dapatkan dari data? Eksplorasi data dapat dengan mudah menjawabnya.
Kode Lima Detik
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
pd.set_option('display.max_colwidth', None)
pd.options.display.float_format = '{:,.2f}'.format
df = pd.read_csv('sirup2020.csv',\
sep='\t',\
usecols=['id', 'paket', 'nilai', 'jenis', 'metode', 'pemilihan', 'instansi', 'satker', 'lokasi'],\
dtype={'id': 'int32', 'paket': 'string', 'nilai': 'float64', 'jenis': 'category', 'metode': 'category', 'pemilihan': 'category', 'instansi': 'category', 'satker': 'category', 'lokasi': 'category'})
# 10 nilai terbesar
df.sort_values(by='nilai', ascending=False).head(10)
Latar Belakang
Rencana Umum Pengadaan (RUP) adalah daftar rencana pengadaan barang atau jasa yang akan dilaksanakan oleh instansi pemerintah, baik pusat maupun daerah. Lembaga Kebijakan Pengadaan Barang Jasa (LKPP) menyediakan Sistem Rencana Umum Pengadaan (SiRUP) sebagai sarana mengumumkan RUP bagi lembaga pemerintah.
Kita dapat mengakses daftar RUP melalui menu Cari Paket pada SiRUP.
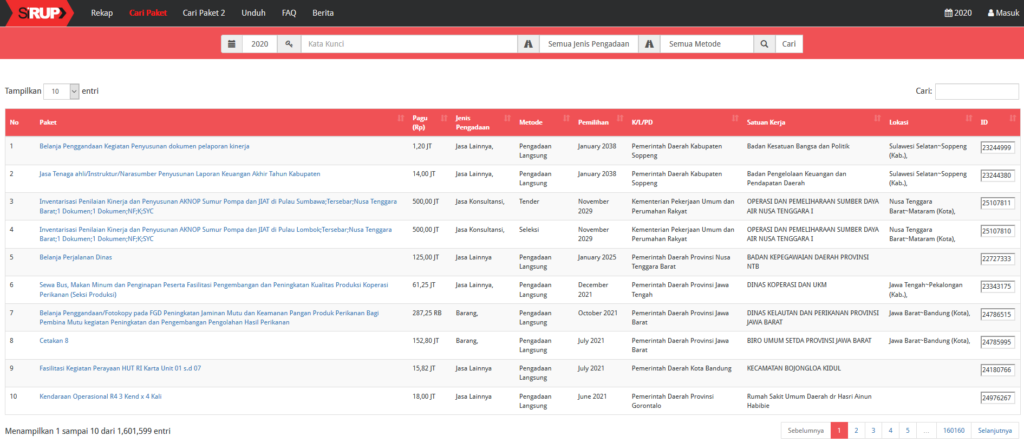
Untuk tahun 2020 terdapat 1.601.599 rencana pengadaan. Penulis telah mendownload daftar tersebut, pada 3 Juni 2020, kemudian mengubah menjadi berkas csv dengan ukuran 340 MB, jika tertarik dengan data tersebut silahkan menghubungi penulis.
Eksplorasi data merupakan hal yang rumit karena kita tidak tahu apa yang ada di depan kita, pertanyaan apa yang bisa diajukan, simpulan apa yang bisa diambil dari data dan lainnya. Karena itu pada tulisan ini kita akan fokus menjawab pertanyaan “berdasarkan data RUP, apa yang terbesar/tertinggi dan terkecil/terendah?”
Apa data terbesar/tertinggi dan terkecil/terendah?
Kode
Impor library
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
pd.set_option('display.max_colwidth', None)
pd.options.display.float_format = '{:,.2f}'.format
Load data
df = pd.read_csv('sirup2020.csv',\
sep='\t',\
usecols=['id', 'paket', 'nilai', 'jenis', 'metode', 'pemilihan', 'instansi', 'satker', 'lokasi'],\
dtype={'id': 'int32', 'paket': 'string', 'nilai': 'float64', 'jenis': 'category', 'metode': 'category', 'pemilihan': 'category', 'instansi': 'category', 'satker': 'category', 'lokasi': 'category'})
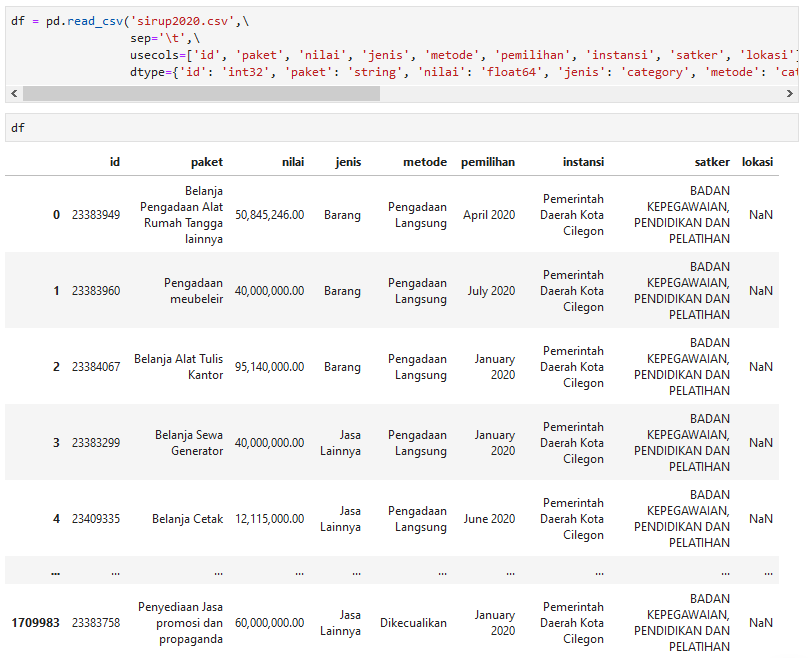
usecols
Kode di atas menggunakan fungsi read_csv untuk membaca berkas csv dan menggunakan parameter usecols dan dtype. Parameter usecols digunakan untuk membatasi kolom tertentu yang akan digunakan. Jika tanpa mendefinisikan kolom, ada beberapa kolom tambahan yang tidak diperlukan seperti 2 kolom tak bernama (unnamed) di sebelah kiri dan satu kolom id.1 (berisi informasi sama dengan kolom id) di sebelah kanan gambar di bawah ini.
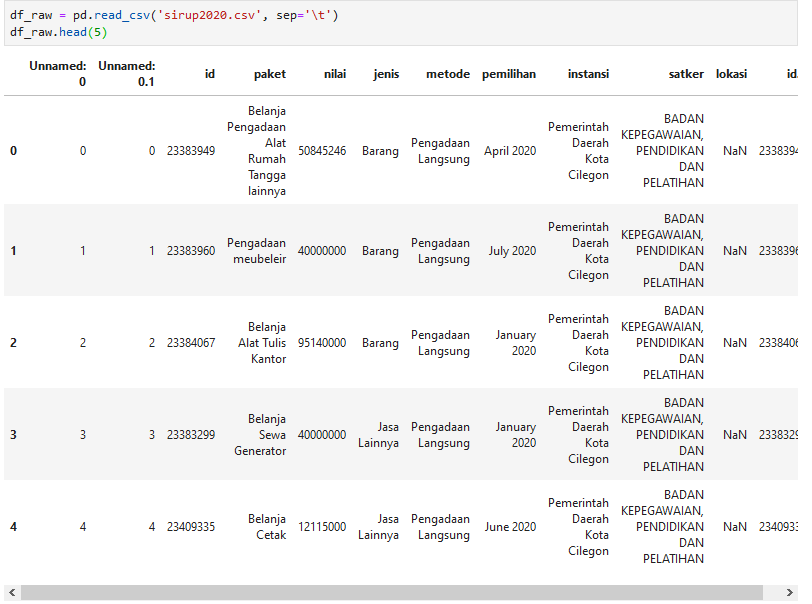
dtype
Parameter dtype digunakan untuk mendefinisikan tipe data pada masing-masing kolom. Kenapa perlu melakukannya? Karena kita berhadapan dengan 1,6 juta baris data yang akan makan banyak waktu untuk memproses. Mendefinisikan tipe data masing-masing kolom membantu mengurangi alokasi memori (yang digunakan) dan waktu tunggu kita (saat pemrosesan data). Pada tulisan selanjutnya akan dibahas beberapa trik (dan library) yang berguna untuk mempercepat proses pengolahan data.
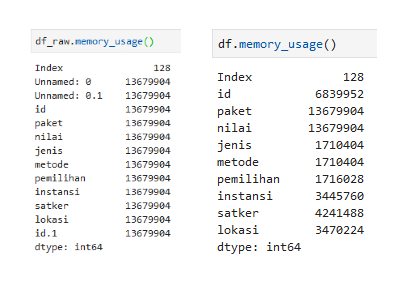
Gambar di atas menunjukkan penggunaan memory tiap kolom. Sebelah kiri (df_raw) adalah dataframe yang tidak didefinisikan tipe data per kolom, sebelah kanan (df) adalah dataframe dengan pendefinisian tipe data. Terlihat df_raw membutuhkan tempat lebih banyak (dalam satuan bytes) ketimbang df.
Jumlah data
df.shape
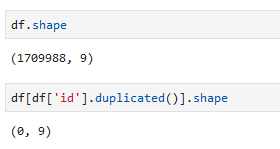
Fungsi shape menunjukkan data yang ada sejumlah 1.709.988 baris dengan masing-masing 9 kolom. Jumlah baris tersebut berbeda dengan versi web yang menunjukkan 1.601.599 data. Namun penggunaan fungsi duplicated menunjukkan tidak terdapat id yang duplikat.
Kolom id
Terbesar dan terkecil
df['id'].describe()
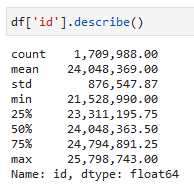
Kolom id dimulai dari nilai 21.528.990 sampai 25.798.743, jika dihitung terdapat 4.269.754 (25.798.743 – 21.528.990 + 1) data. Padahal hanya terdapat 1.709.988 baris data, ada selisih 2.559.766 (4.269.754 – 1.709.988), apakah selisih tersebut merupakan gap?
Gap
Menggunakan teknik pengujian gap dari tulisan sebelumnya, kita uji apakah terdapat gap pada kolom id.
urut = [i for i in range(df['id'].min(), df['id'].max() + 1)] urut_df = pd.DataFrame(urut, columns=['urut']) urut_df[~urut_df['urut'].isin(df['id'])]
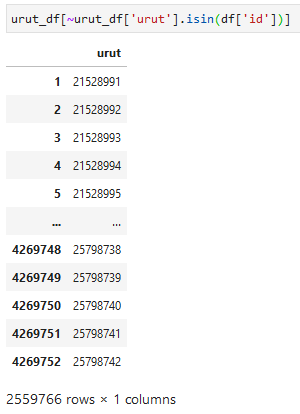
Sejauh ini penulis belum mengetahui kenapa terdapat gap atau data yang tidak terekam dalam data yang kita miliki, bisa jadi karena ada data yang tidak ditampilkan (misal dummy data), sistem memberikan id berupa angka acak atau karena sebab lain.
Secara umum id menggunakan angka berurutan namun hal tersebut bukan keharusan. Banyak sistem yang menggunakan angka/kombinasi huruf-angka acak untuk identitas data, seperti Youtube.
Kolom nilai
Total nilai
'{:,.2f}'.format(df['nilai'].sum())
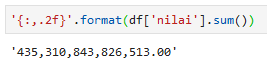
Total nilai pengadaan tahun 2020 direncanakan sebesar 435.310.843.826.513 (435 triliun).
Terbesar dan terkecil
df['nilai'].describe()
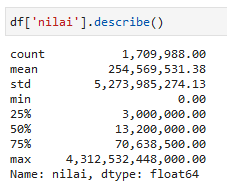
Rencana pengadaan tahun 2020 bernilai 0 sampai 4.312.532.448.000 (4 triliun).
10 terbesar
df.sort_values(by='nilai', ascending=False).head(10)
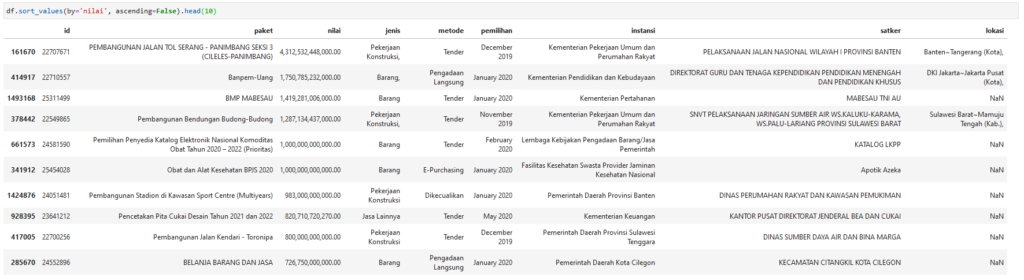
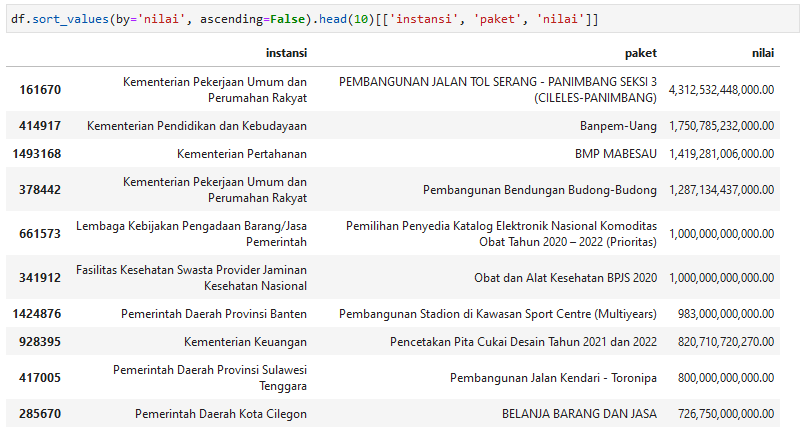
Ternyata rencana pengadaan terbesar adalah paket Pembangunan Jalan Tol Serang – Panimbang Seksi 3 (Cileles-Panimbang) milik Kementerian PUPR. Untuk tingkat provinsi, Pemprov Banten dengan paket Pembangunan Stadion di Kawasan Sport Center senilai 983 miliar menjadi yang terbesar.
10 terkecil
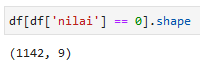
df[df['nilai'] == 0].shape
df[df['nilai'] == 0].head(10)
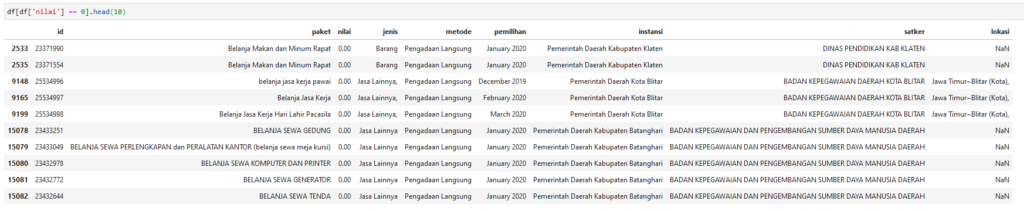
Terdapat 1.142 data dengan kolom nilai 0, sebagai contoh ditampilkan 10 diantaranya. Penulis belum mengetahui kenapa terdapat paket bernilai 0 tersebut.
Data bernilai kurang dari 100
df[(df['nilai'] > 0) & (df['nilai'] < 100)].shape

df[(df['nilai'] > 0) & (df['nilai'] < 100)].head(10)
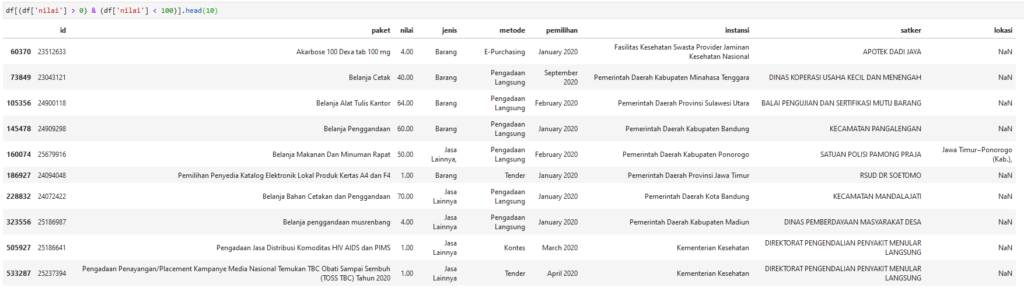
Selain data bernilai 0, terdapat 56 data dengan nilai  . Nilai 100 dipilih karena merupakan nominal terkecil uang emisi tahun 2016.
. Nilai 100 dipilih karena merupakan nominal terkecil uang emisi tahun 2016.
Kolom jenis
Total nilai per jenis
jenis = df.groupby('jenis', as_index=False)['nilai'].sum()
jenis.sort_values(by='nilai', ascending=False, inplace=True)
jenis = jenis.reset_index(drop=True)
jenis['nilai_juta'] = jenis['nilai'] / 1000000
jenis['nilai_log'] = np.log10(jenis['nilai'])
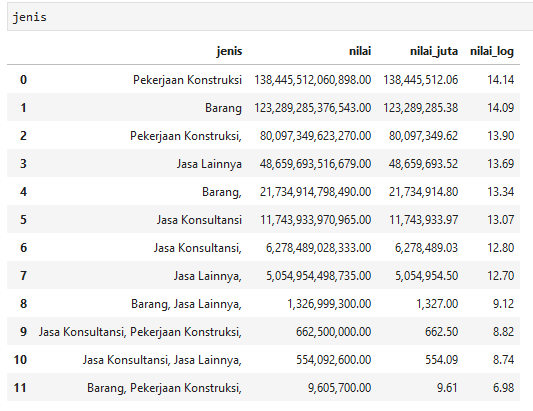
Jika dikelompokkan per jenis, Pekerjaan Konstruksi merupakan jenis terbesar dengan total nilai 138.445.512.060.898.
Sebagai catatan, data di atas belum diolah lebih lanjut, sangat mungkin jenis Pekerjaan Konstruksi dan Pekerjaan Konstruksi, (dengan koma) merupakan satu kesatuan, terpisah karena kesalahan input data. Begitu juga dengan jenis Jasa Lainnya, Jasa Konsultansi dan Barang.
Kolom nilai_juta dan nilai_log ditambahkan untuk menyederhanakan grafik. Kolom nilai_juta didapatkan dengan membagi kolom nilai dengan satu juta. Kolom nilai_log merupakan hasil log10 dari kolom nilai, sebagai pengingat log10(1000) adalah 3, log10(1000000) adalah 6.
Grafik
a4_dims = (11.7, 8.27)
plt.figure(figsize=a4_dims)
ax = sns.barplot(x='jenis', y='nilai_juta', data=jenis, order=jenis.sort_values('nilai_juta', ascending=False).jenis)
ax.set(xlabel='Jenis Pengadaan', ylabel='Nilai (dalam Juta)')
ax.get_yaxis().set_major_formatter(plt.FuncFormatter(lambda x, loc: "{:,}".format(int(x))))
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha="right")
plt.tight_layout()
plt.show()
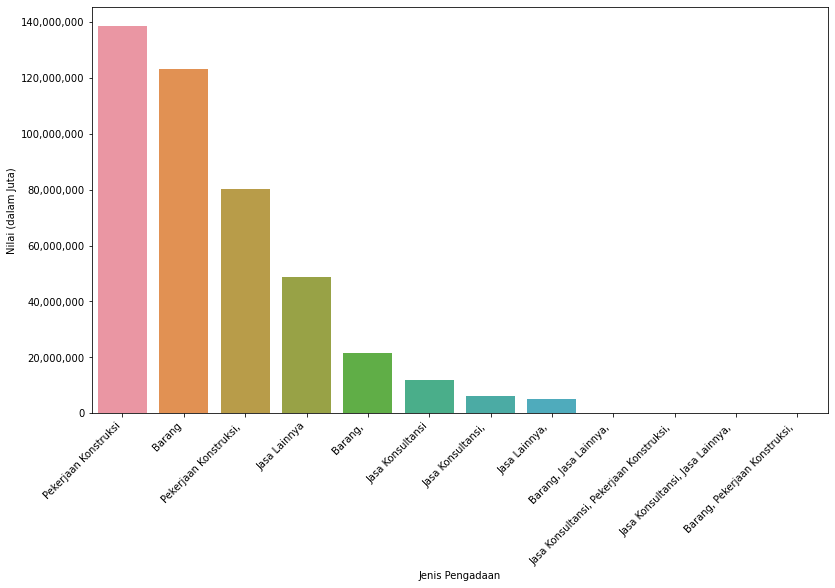
Grafik di atas menggunakan kolom nilai_juta, sebagai akibatnya jenis Barang, Pekerjaan Konstruksi, dengan nilai 9,61 terlalu pendek sehingga (hampir) tidak ditampilkan karena jenis lainnya terlalu tinggi. Jika semata hanya untuk menunjukkan urutan (terbesar ke terkecil), kita dapat menggunakan log10.
Grafik log10
a4_dims = (11.7, 8.27)
plt.figure(figsize=a4_dims)
ax = sns.barplot(x='jenis', y='nilai_log', data=jenis, order=jenis.sort_values('nilai_log', ascending=False).jenis)
ax.set(xlabel='Jenis Pengadaan', ylabel='Nilai (dalam log10)')
ax.get_yaxis().set_major_formatter(plt.FuncFormatter(lambda x, loc: "{:,}".format(int(x))))
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha="right")
plt.tight_layout()
plt.show()
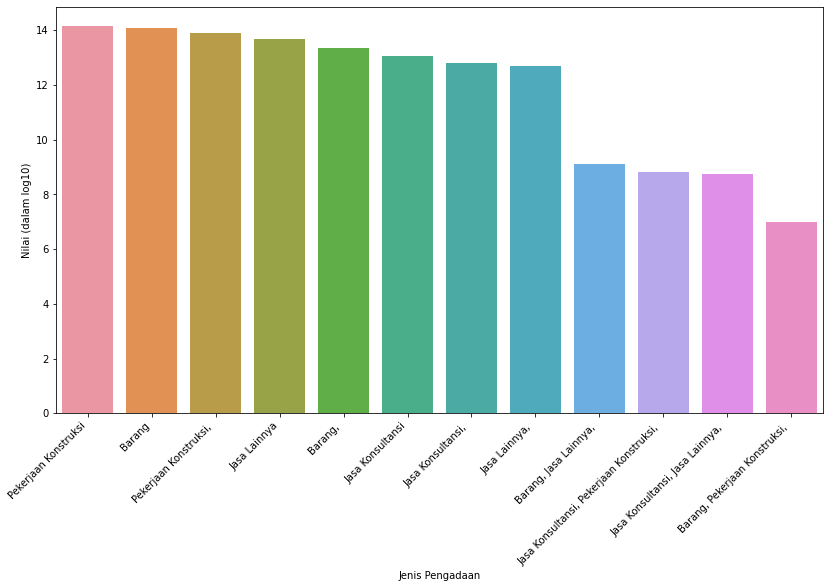
Kita perlu berhati-hati dalam memvisualkan data, grafik terakhir memiliki jarak yang pendek sehingga dapat disalahartikan sebagai perbedaan antar jenis tidak terlalu besar. Padahal hal tersebut (jarak antar jenis yang pendek) terjadi karena kita menggunakan log10 dari kolom nilai, bukan kolom nilai langsung.
Kolom metode
Total nilai per metode
metode = df.groupby('metode', as_index=False)['nilai'].sum()
metode.sort_values(by='nilai', ascending=False, inplace=True)
metode = metode.reset_index(drop=True)
metode['nilai_juta'] = metode['nilai'] / 1000000
metode['nilai_log'] = np.log10(metode['nilai'])
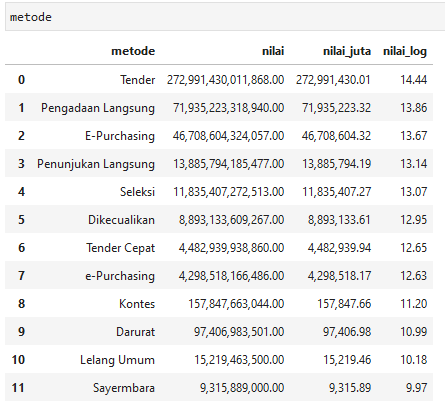
Pengadaan melalui tender menduduki peringkat terbesar pertama dengan nilai 272 triliun. Sedang sayembara menjadi yang paling akhir dengan “hanya” senilai total 9 miliar.
Grafik
a4_dims = (11.7, 8.27)
plt.figure(figsize=a4_dims)
ax = sns.barplot(x='metode', y='nilai_juta', data=metode, order=metode.sort_values('nilai_juta', ascending=False).metode)
ax.set(xlabel='Metode Pengadaan', ylabel='Nilai (dalam juta)')
ax.get_yaxis().set_major_formatter(plt.FuncFormatter(lambda x, loc: "{:,}".format(int(x))))
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha="right")
plt.tight_layout()
plt.show()
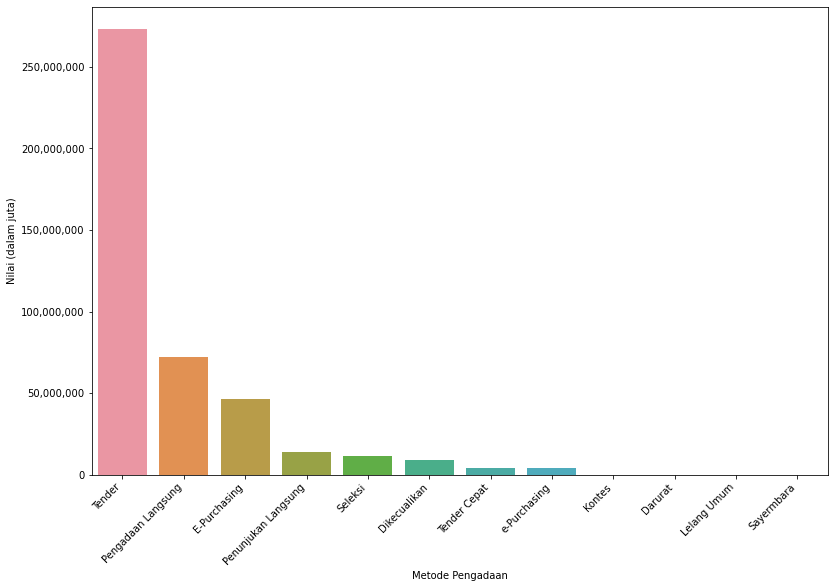
Kolom instansi
Total nilai per instansi
instansi = df.groupby('instansi', as_index=False)['nilai'].sum()
instansi.sort_values(by='nilai', ascending=False, inplace=True)
instansi = instansi.reset_index(drop=True)
instansi['nilai_juta'] = instansi['nilai'] / 1000000
instansi['nilai_log'] = np.log10(instansi['nilai'])
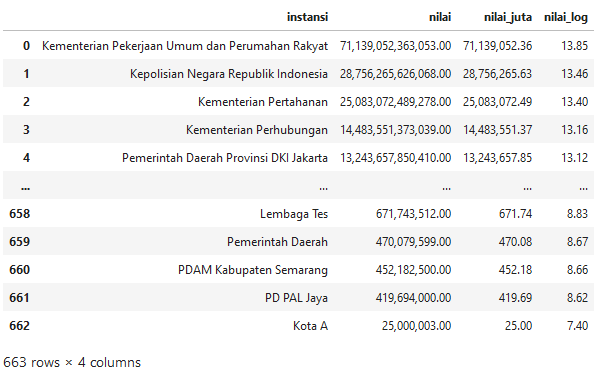
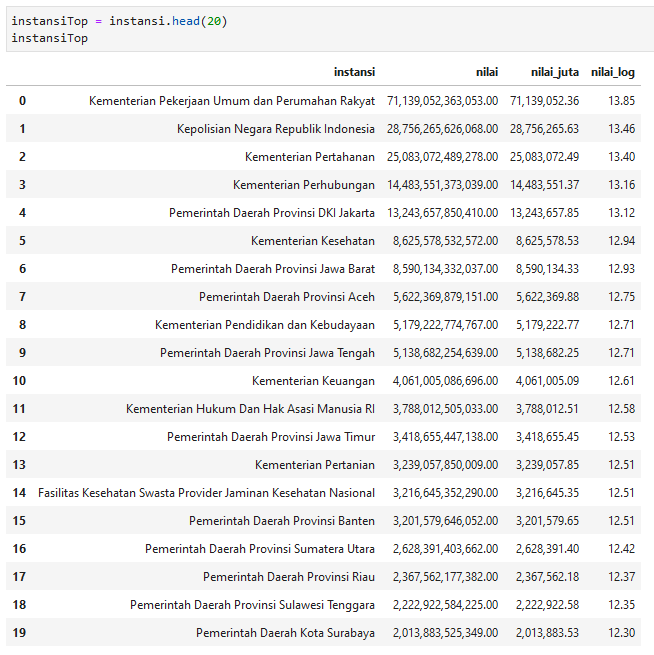
Terdapat 663 instansi pada data RUP, Kementerian PUPR menjadi yang tertinggi nilainya dengan 71 triliun, disusul Kepolisian. Sedang di posisi bawah ada PD Pal Jaya dan Kota A, mengenai yang terakhir ini penulis berasusmsi merupakan dummy data.
Grafik
a4_dims = (11.7, 8.27)
plt.figure(figsize=a4_dims)
ax = sns.barplot(x='instansi', y='nilai_juta', data=instansi, order=instansi.sort_values('nilai_juta', ascending=False).instansi)
ax.set(xlabel='Instansi', ylabel='Nilai (dalam log10)')
ax.get_yaxis().set_major_formatter(plt.FuncFormatter(lambda x, loc: "{:,}".format(int(x))))
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha="right")
plt.tight_layout()
plt.show()

Hampir tidak ada informasi yang dapat kita ambil dari gambar di atas, kita ambil saja 20 (instansi) teratas dan terbawah.
20 teratas
instansiTop = instansi.head(20)
a4_dims = (11.7, 8.27)
plt.figure(figsize=a4_dims)
ax = sns.barplot(x='instansi', y='nilai_juta', data=instansiTop, order=instansiTop.sort_values('nilai_juta', ascending=False).instansi)
ax.set(xlabel='Instansi', ylabel='Nilai (dalam juta)')
ax.get_yaxis().set_major_formatter(plt.FuncFormatter(lambda x, loc: "{:,}".format(int(x))))
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha="right")
plt.tight_layout()
plt.show()
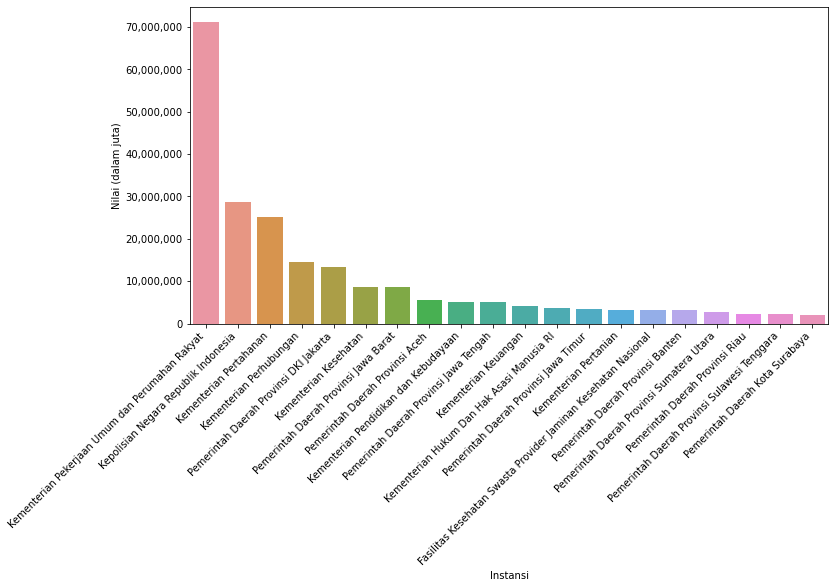
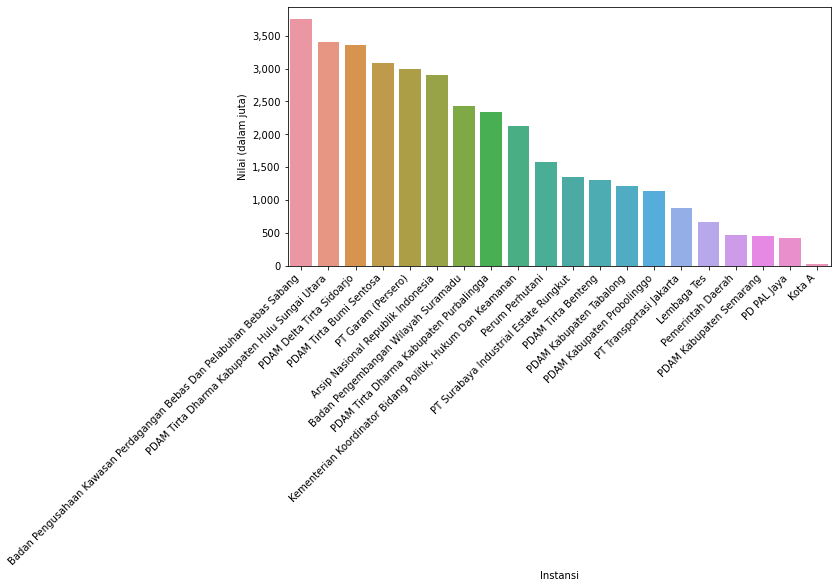
20 terbawah
instansiBottom = instansi[instansi['nilai'] > 0].tail(20)
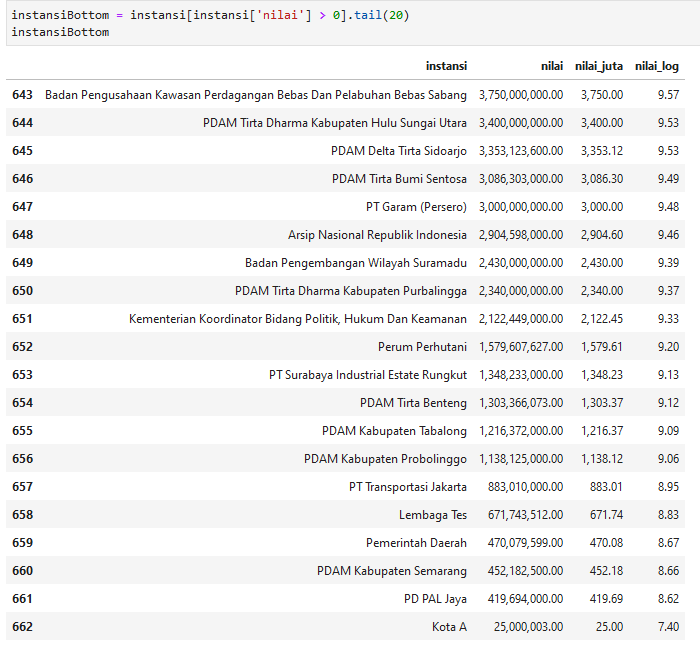
Selain Kota A, Pemerintah Daerah (baris 659) sepertinya merupakan dummy data juga. Kita perlu data sekunder untuk memastikan data mana saja yang mengacu pada lembaga pemerintah dan mana yang merupakan dummy data sehingga dapat dieksklusi.
a4_dims = (11.7, 8.27)
plt.figure(figsize=a4_dims)
ax = sns.barplot(x='instansi', y='nilai_juta', data=instansiBottom, order=instansiBottom.sort_values('nilai_juta', ascending=False).instansi)
ax.set(xlabel='Instansi', ylabel='Nilai (dalam juta)')
ax.get_yaxis().set_major_formatter(plt.FuncFormatter(lambda x, loc: "{:,}".format(int(x))))
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha="right")
plt.tight_layout()
plt.show()
Kolom lokasi
Total nilai per lokasi
lokasi = df.groupby('lokasi', as_index=False)['nilai'].sum()
lokasi.sort_values(by='nilai', ascending=False, inplace=True)
lokasi = lokasi.reset_index(drop=True)
lokasi['nilai_juta'] = lokasi['nilai'] / 1000000
lokasi['nilai_log'] = np.log10(lokasi['nilai'])
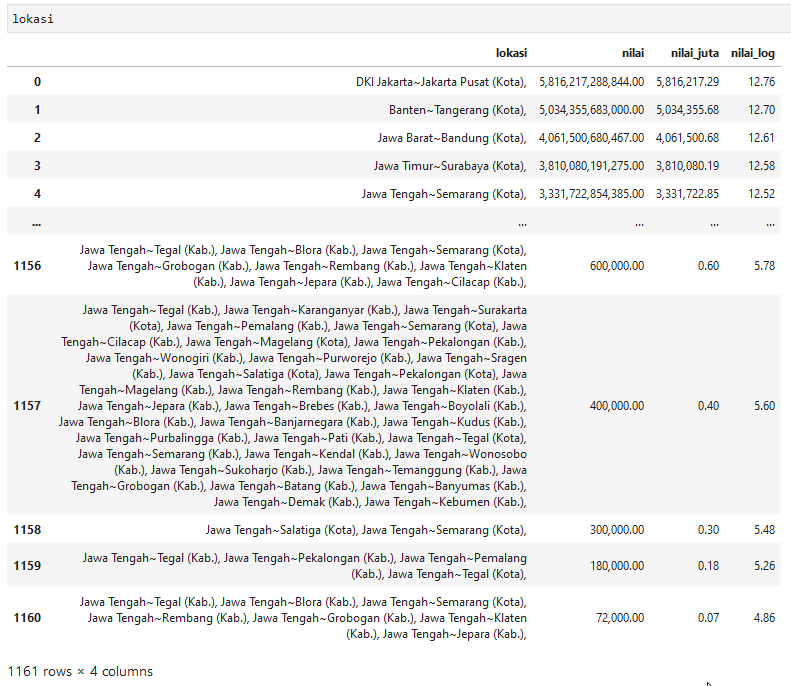
Lokasi pengadaan tersebar di 1.161 titik namun jumlah tersebut perlu ditelusuri lagi karena terdapat paket dengan nama lokasi yang merupakan gabungan dari berbagai lokasi.
Grafik
a4_dims = (11.7, 8.27)
plt.figure(figsize=a4_dims)
ax = sns.barplot(x='lokasi', y='nilai_juta', data=lokasi, order=lokasi.sort_values('nilai_juta', ascending=False).lokasi)
ax.set(xlabel='Lokasi', ylabel='Nilai (dalam juta rupiah)')
ax.get_yaxis().set_major_formatter(plt.FuncFormatter(lambda x, loc: "{:,}".format(int(x))))
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha="right")
plt.tight_layout()
plt.show()

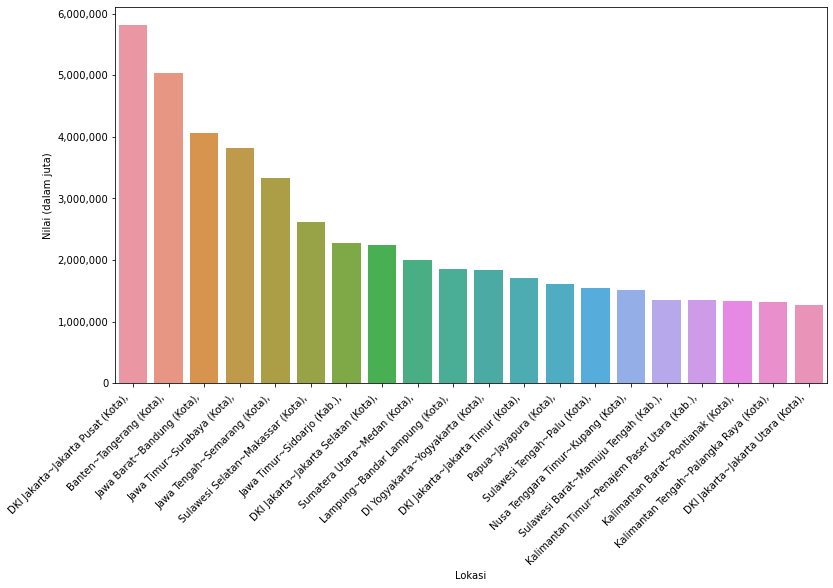
20 teratas
lokasiTop = lokasi.head(20)
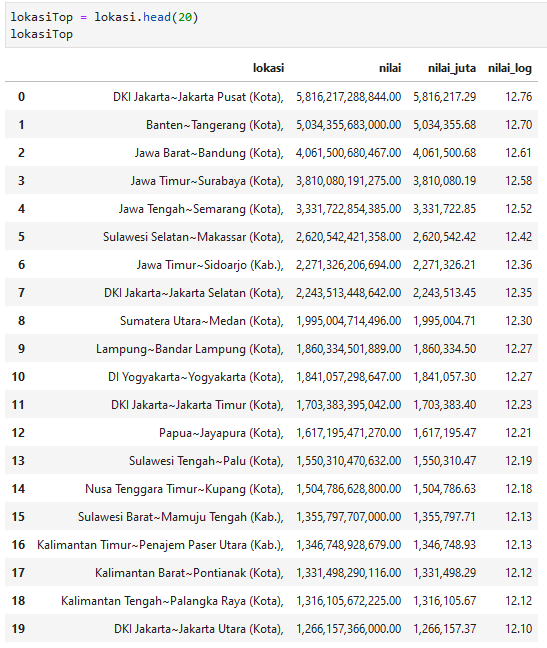
a4_dims = (11.7, 8.27)
plt.figure(figsize=a4_dims)
ax = sns.barplot(x='lokasi', y='nilai_juta', data=lokasiTop, order=lokasiTop.sort_values('nilai_juta', ascending=False).lokasi)
ax.set(xlabel='Lokasi', ylabel='Nilai (dalam juta)')
ax.get_yaxis().set_major_formatter(plt.FuncFormatter(lambda x, loc: "{:,}".format(int(x))))
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha="right")
plt.tight_layout()
plt.show()
20 terbawah
lokasiBottom = lokasi[lokasi['nilai'] > 0].tail(20)
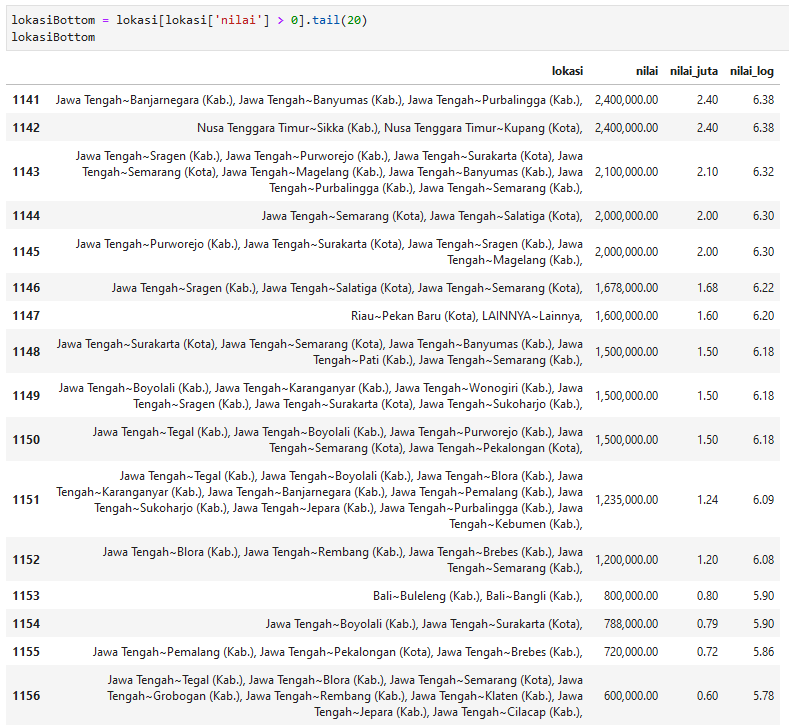
lokasiBottom['lokasi_sub'] = lokasiBottom['lokasi'].str.split().str[0:3].str.join(' ')
a4_dims = (11.7, 8.27)
plt.figure(figsize=a4_dims)
ax = sns.barplot(x='lokasi_sub', y='nilai_juta', data=lokasiBottom, order=lokasiBottom.sort_values('nilai_juta', ascending=False).lokasi_sub)
ax.set(xlabel='Lokasi', ylabel='Nilai (dalam juta)')
ax.get_yaxis().set_major_formatter(plt.FuncFormatter(lambda x, loc: "{:,}".format(int(x))))
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha="right")
plt.tight_layout()
plt.show()
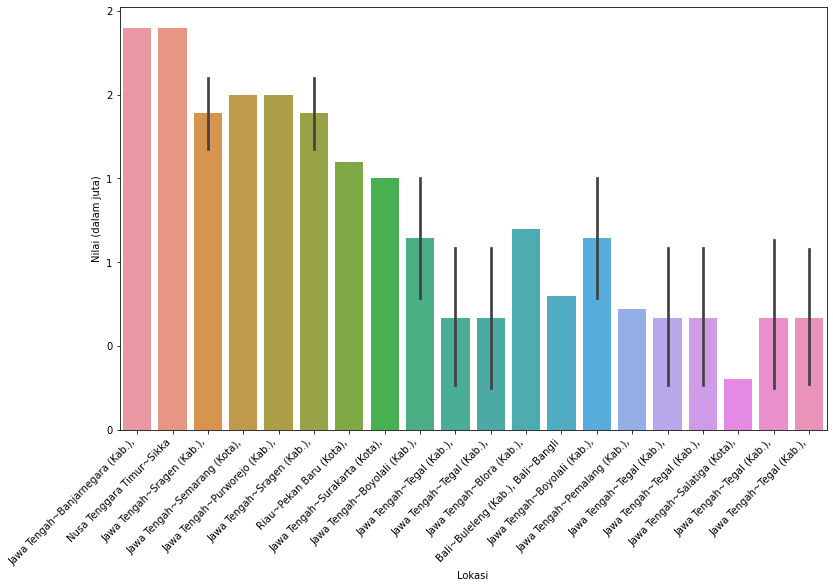
Kode di atas membuat sebuah kolom bernama lokasi_sub yang mengambil dua kata pertama dari kolom lokasi. Kolom lokasi_sub tersebut yang ditampilkan pada grafik.
Referensi
- https://sirup.lkpp.go.id/sirup/ro/cari
- https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.memory_usage.html
- https://www.kaggle.com/pmarcelino/comprehensive-data-exploration-with-python
- https://towardsdatascience.com/a-guide-to-pandas-and-matplotlib-for-data-exploration-56fad95f951c
- https://towardsdatascience.com/data-exploration-vs-insights-cd2d3551fd77
- https://medium.com/@FILWD/what-do-we-talk-about-when-we-talk-about-data-exploration-2f82503fb377
- https://medium.com/analytics-vidhya/a-comprehensive-guide-to-data-exploration-d5919167bf6e
saya senang membaca web bapak.
keinginan saya belajar mengenai mengolah data.
boleh minta no kontak komunikasinya
Terimakasih telah membaca, silahkan kontak melalui ba********@***il.com.