

Add-in Excel untuk Web Scraping
Satu hal memicu hal lainnya.
Tulisan soal Add-in Excel untuk pemula memantik rasa ingin tahu penulis, apakah vba bisa juga digunakan untuk mengambil data dari web? Mengingat kebanyakan dari kita mengolah data di MS Excel, kenapa tidak sekalian saja akuisisi data menggunakan Excel?
Pencarian vba scrape web pada mesin pencari menghasilkan beberapa artikel yang menggunakan Internet Explorer (IE) dan ServerXMLHTTP untuk scraping data dari web. Namun penulis punya pengalaman tertentu (baca: kurang menyenangkan-red) dengan IE, bahkan artikel ini menyarankan menggunakan Selenium. Penulis sudah beberapa kali menggunakan Selenium dan puas dengan apa yang bisa dilakukan. Karena itu penulis cenderung menggunakannya.
Selenium di VBA Excel telah dibungkus dalam sebuah library SeleniumBasic yang dapat diunduh di sini. Sayangnya orang baik itu sudah tidak lagi mengembangkan SeleniumBasic sehingga mungkin kita tidak dapat menggunakan fitur kekinian dari Selenium, seperti headless browser. Tapi sebagian besar kebutuhan kita sehari-hari telah dapat diselesaikan dengan baik oleh SeleniumBasic, jika ingin menggunakan fitur yang tidak tersedia kita bisa menggunakan Bahasa Pemrograman lain seperti C#, Java, Python, Javascript atau Ruby sebagai antarmuka untuk menggunakan Selenium.
Apa itu Selenium? Menurut rilis resmi pembuatnya, Selenium adalah (satu set) alat yang digunakan untuk mengotomasi web browsers. Awalnya otomasi peramban ini digunakan untuk memudahkan jika kita ingin melakukan pengujian atas web yang kita buat, namun ternyata banyak juga “disalahgunakan” untuk melakukan otomasi pada “kegiatan” di halaman web. Karena itulah ada captcha yang digunakan untuk melawan kegiatan otomasi web yang mengganggu.
Tulisan ini akan dibagi menjadi tiga bagian, yaitu:
- Instalasi SeleniumBasic dan akses web
- Ambil Data dari Web
- Web Scraping Banyak Halaman
Software yang perlu di-download:
Instalasi SeleniumBasic dan Akses Web
Karena tak lagi dikembangkan, SeleniumBasic memiliki beberapa hal yang perlu diperhatikan seperti:
- Tidak dapat digunakan dengan peramban Firefox.
- Fitur Selenium tidak selengkap Selenium yang kita akses melalui bahasa pemrograman lain seperti Java dan Python.
Instalasi dilakukan dengan mendownload SeleniumBasic v2.0.9.0 pilih SeleniumBasic-2.0.9.0.exe.
Lalu lakukan instalasi dengan klik Next berkali-kali.
Setelah selesai, langkah selanjutnya adalah mengunduh Web Driver, penulis baru berhasil mengoperasikan SeleniumBasic menggunakan Google Chrome. Penggunaan Firefox (geckodriver) selalu gagal. Karena itu kali ini akan digunakan ChromeDriver yang dapat diunduh di sini. Oya, pada PC harus sudah terinstall peramban Chrome.
Versi ChromeDriver yang digunakan harus sesuai dengan Chrome yang telah terinstal pada komputer. Untuk mengetahui versi Chrome dapat diketik alamat chrome://settings/help.
Pada contoh, Chrome penulis adalah versi 78.x sehingga pada halaman ini penulis memilih ChromeDriver 78.x.
Lalu pilih chromedriver_win32.zip.
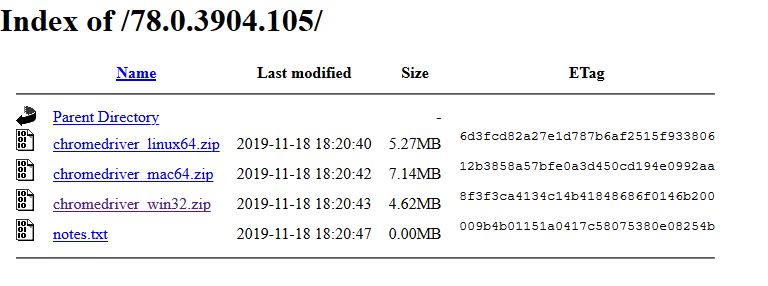
Berkas .zip tersebut berisi satu file yaitu chromedriver.exe yang akan kita gunakan untuk memperbaharui chromedriver bawaan SeleniumBasic. Hal ini perlu kita lakukan karena kita akan menemui error jika menggunakan chromedriver bawaan SeleniumBasic, penulis mengalami sendiri hal tersebut. Berdasarkan jawaban di SO ini, kita perlu me-replace chromedriver.exe yang ada di C:\Users\%username%\AppData\Local\SeleniumBasic.
Sampai di sini, proses instalasi selesai, SeleniumBasic sudah dapat diberdayakan.
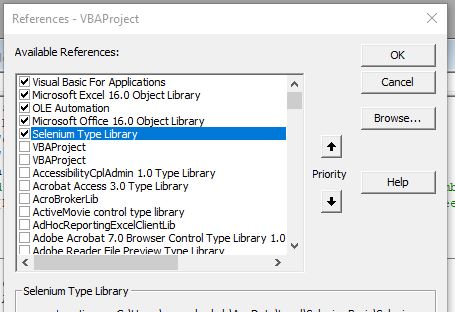
Buka Excel lalu VBA (ALT+F11). Lalu tambahkan SeleniumBasic melalui menu Tools > References.

Kemudian pilih Selenium Type Library dan OK.
Lalu buat sebuah Module dan ketik, atau paste, kode ini.
Public Sub cobabukabrowser()
' Inisiasi Peramban
Dim driver As New WebDriver
' Peramban yang digunakan adalah chrome dan
' halaman yang dibuka adalah https://google.com
driver.Start "chrome", "https://google.com"
' Peramban membuka halaman
driver.Get "/"
' Tunggu selama 5 detik
Application.Wait (Now + TimeValue("0:00:05"))
' Tutup peramban
driver.Quit
End Sub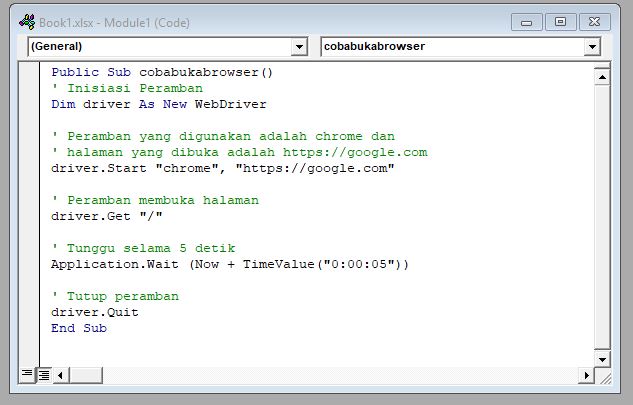
Selanjutnya jalankan kode dengan Run > Run Sub/UserForm atau tekan F5.

VBA akan membuka window Chrome baru.
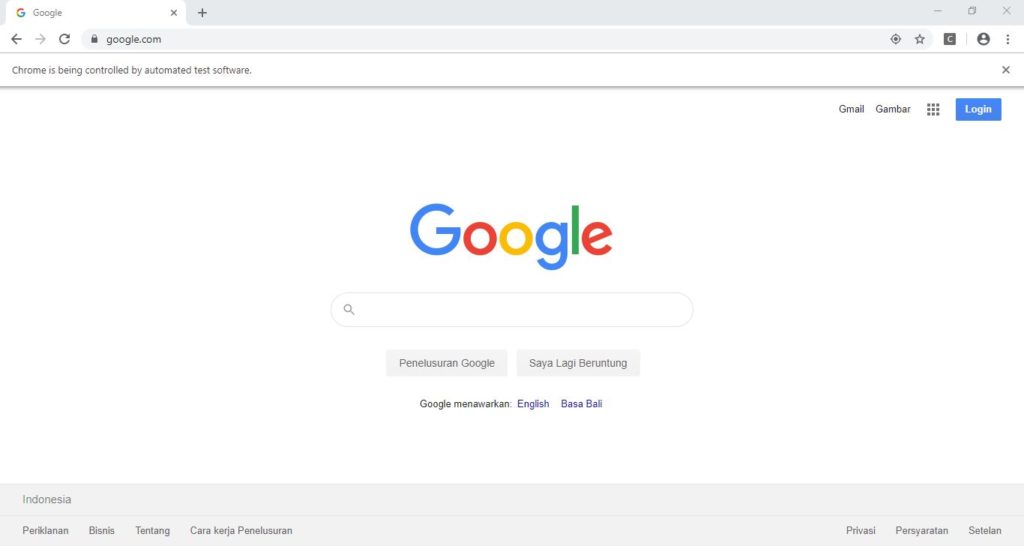
Di bagian atas terdapat keterangan “Chrome is being controlled by automatic test software” yang menunjukkan bahwa peramban tersebut dioperasikan (diotomasi) oleh program komputer, bukan oleh manusia.
Awesome! Sekarang kita bisa mencoba SeleniumBasic untuk bekerja bagi kita.
Ambil Data dari Web
Kita akan mengulangi tugas di tulisan ini, bedanya alih-alih menggunakan scrapy kita akan menggunakan VBA.
Tugas kita adalah mengambil judul artikel dari blog ini (https://basangdata.com) dan menuliskan hasilnya pada sebuah sheet baru dengan kode seperti ini.
Public Sub tugaspertama()
' Inisiasi Peramban, Elemen pada web, Sheet dan variabel i
Dim driver As New WebDriver
Dim titles As WebElements ' dapat diperhatikan penggunaan s di akhir kata (plural)
Dim title As WebElement ' WebElement ini tanpa s (singular)
Dim sheetkiri As Worksheet
Dim i As Integer
' Variabel i ini adalah nomor baris
i = 1
' Peramban yang digunakan adalah chrome dan
' halaman yang dibuka adalah https://basangdata.com
driver.Start "chrome", "https://basangdata.com"
' Peramban membuka halaman
driver.Get "/"
' Buat sheet baru dan letakkan paling kiri
Sheets.Add(Before:=Sheets(1)).Name = "SheetsPalingKiri"
' variabel sheetkiri adalah sheet paling kiri
Set sheetkiri = Sheets("SheetsPalingKiri")
' variabel titles berisi banyak elemen (FindElements bukan FindElement)
' yang didapatkan dari tag HTML heading2 dengan kelas entry__title
Set titles = driver.FindElementsByXPath("//h2[contains(@class, 'entry__title')]/a")
' Ulangi untuk tiap variabel titles
For Each title In titles
' Tambahkan sheet dengan data dari tag HTML heading2 yang telah diambil
sheetkiri.Cells(i, 1).Value = title.Text
' Tambahkan i agar data pada tiap baris tidak ditimpa data selanjutnya
i = i + 1
Next
' Tutup peramban
driver.Quit
End Sub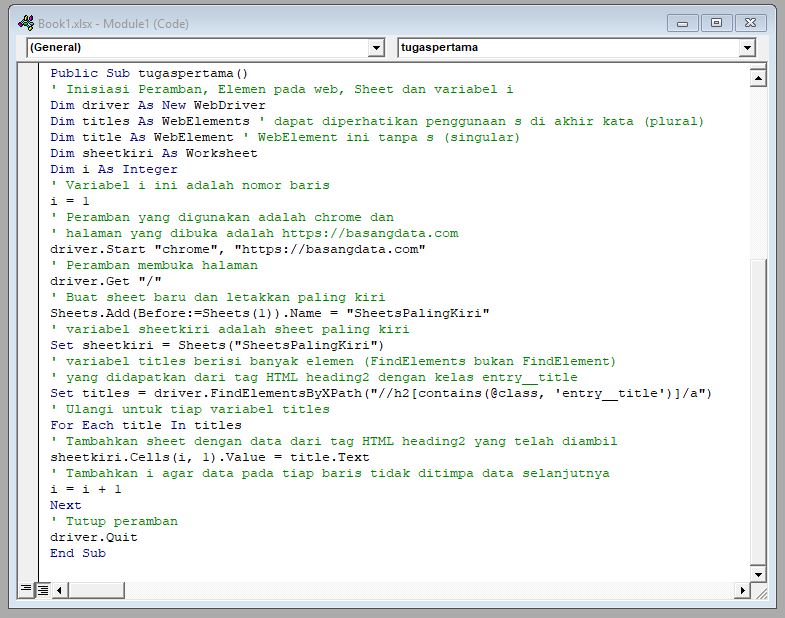
Lalu Run kode (F5).
Mantul.
Singkatnya Selenium mencari elemen h2 yang mengandung kelas entry__title, mencari elemen a di dalam h2 dan mengambil teks dari elemen a.
Jika ingin mendapatkan penjelasan (lebih tidak) singkat mengenai bagaimana mendapatkan data melalui tag HTML, XPATH dan kenapa narsis melakukan scraping dari blog ini, silahkan membaca tulisan yang menjadi rujukan.
Web Scaping Banyak Halaman
Mulanya bagian ini ingin mengulangi lagi langkah kerja di tulisan sebelumnya, namun penulis merasa perlu lebih memanfaatkan properti yang ada pada web, alih-alih melakukan perulangan 1-1.000. Namun hal tersebut, melakukan perulangan 1 sampai 1.000 benar pada saat itu karena tombol Berikutnya hanya bekerja lancar sampai halaman ke-1000.
Kali ini kita akan mengambil data paket pekerjaan yang dilelang oleh Pemerintah Kabupaten Jayawijaya dari web LPSE.
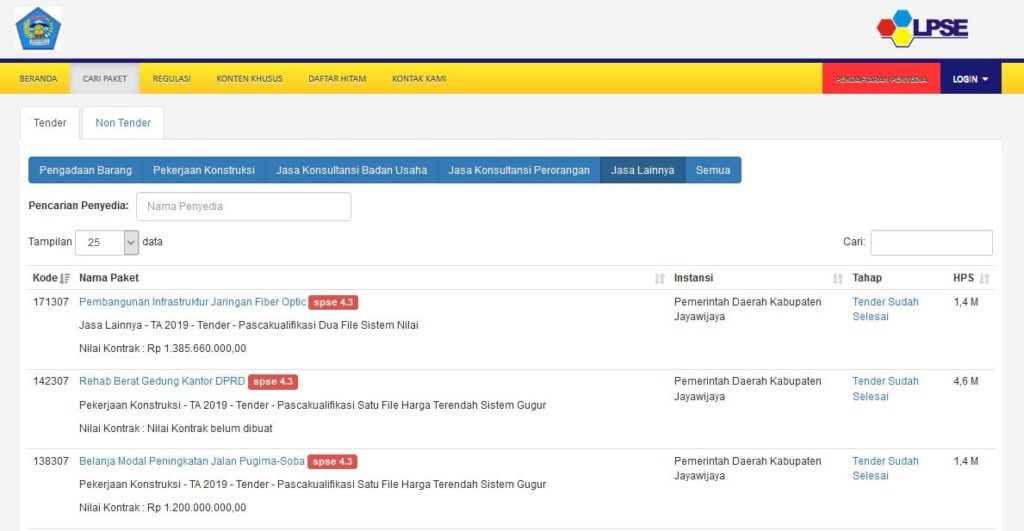
Informasi dari sini dapat dimanfaatkan jika pembaca ingin mengikuti lelang pekerjaan yang dilakukan oleh Pemerintah. Pada tahun 2019 ini terdapat 43 paket pekerjaan yang dilelang oleh Pemerintah Jayawijaya sehingga daftar tersebut terbagi menjadi 2 halaman.
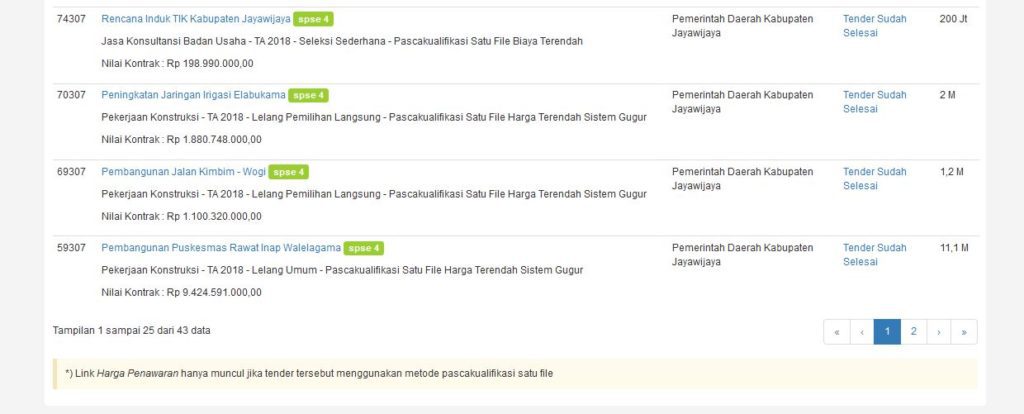
Kita akan mengambil data berupa Kode dan Nama Paket dari 43 data tersebut.
Kode ada di tag html td dengan kelas sorting_1. Pada peramban, kita dapat melakukan klik kanan pada salah satu Kode dan pilih Inspect Element. Kita akan mendapatkan tag html yang berisi kode tersebut.
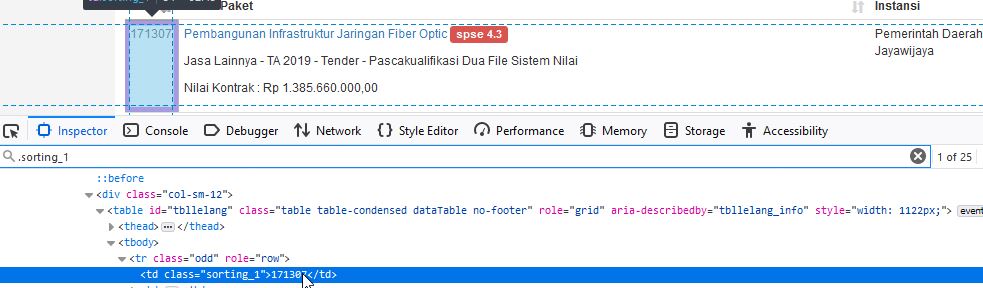
Pada gambar di atas, kita tahu bahwa kelas yang digunakan adalah sorting_1. Hasil pencarian elemen dengan kelas sorting_1 pada halaman tersebut terdapat 25 elemen, angka 25 ini sesuai dengan jumlah data yang ditampilkan per halaman. Jadi bisa disimpulkan untuk mendapatkan Kode kita dapat mengambil dari elemen td dengan kelas sorting_1.
Beda dengan Kode, elemen yang mengandung data Nama Paket tidak memiliki id atau kelas khusus.
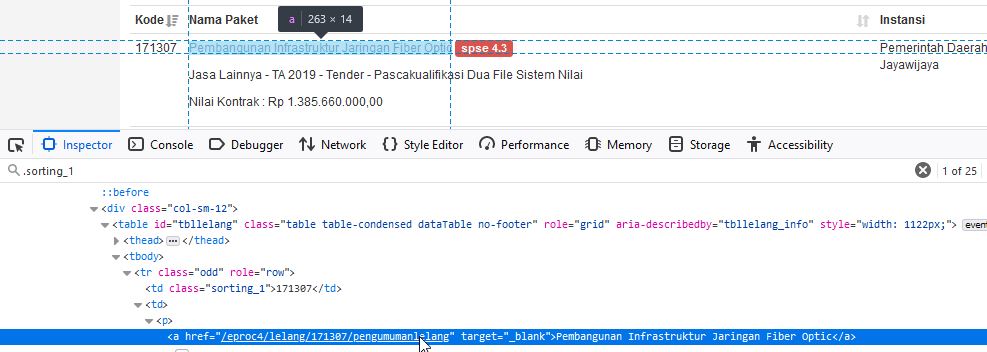
Sejauh ini yang kita ketahui hanya elemen td dengan kelas sorting_1 memiliki sibling, keduanya merupakan anak dari elemen tr, berupa elemen td. Dalam elemen td tersebut terdapat elemen p yang memiliki elemen a, dan akhirnya pada elemen a inilah terdapat Nama Paket yang akan kita ambil.
Kebingungan seperti ini biasanya akan teratasi saat melakukan koding karena itu tidak perlu terburu-buru jika sekarang kita belum paham.
Selanjutnya untuk berpindah halaman kita bisa melakukan klik pada nomor halaman selanjutnya atau dengan tombol panah kanan (>). Tombol panah kanan tersebut ada pada elemen dengan id tbllelang_next.
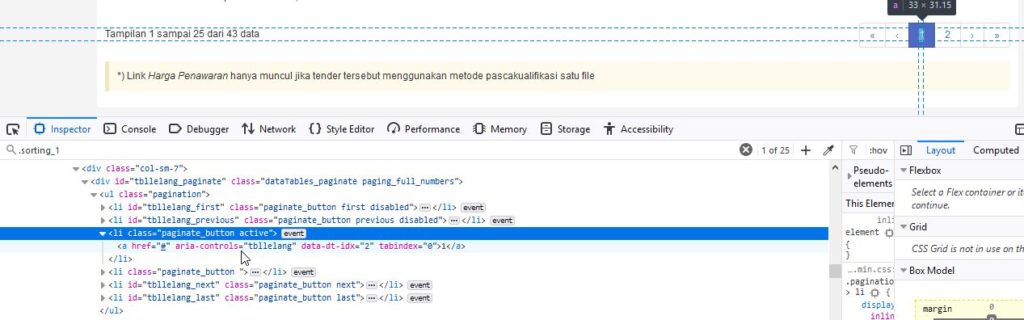
Jika masih ada halaman selanjutnya maka tbllelang_next akan menggunakan kelas “paginate_button next“, sedang jika tidak ada halaman selanjutnya menjadi “paginate_button next disabled“. Hal ini adalah properti yang akan kita manfaatkan untuk mengidentifikasi apakah sudah saatnya program berhenti melakukan scraping atau belum.

Memanfaatkan tombol navigasi, kita tidak perlu tahu berapa banyak halaman yang diambil, beda dengan tulisan sebelumnya yang membatasi hanya 1.000 halaman.
Kode yang kita gunakan sebagai berikut.
Public Sub tugaskedua()
Dim driver As New WebDriver
Dim codes As WebElements
Dim code As WebElement
Dim sheetkiri As Worksheet
Dim i As Integer
Dim halamanterakhir As Boolean
Dim By As New By
Dim nextbutton As WebElement
i = 1
halamanterakhir = False
driver.Start "chrome", "http://lpse.jayawijayakab.go.id" ' Buka halaman awal LPSE
driver.Get "http://lpse.jayawijayakab.go.id/eproc4/lelang" ' Lalu buka halaman berisi data yang diinginkan
Set sheetkiri = Sheets.Add ' Buat sheet baru
' Lakukan langkah di bawah ini selama variabel halamanterakhir = False
Do While halamanterakhir = False
driver.Wait 5000 ' Tunggu selama 5 detik sampai halaman di-load sempurna
' variabel halamanterakhir bernilai False/True
' Bergantung dari ditemukan/tidak elemen dengan kelas paginate_button next disabled
halamanterakhir = driver.IsElementPresent(By.XPath("//li[contains(@class, 'paginate_button next disabled')]"))
' Ambil semua elemen dengan kelas sorting_1
Set codes = driver.FindElementsByXPath("//td[contains(@class, 'sorting_1')]")
' Untuk tiap element dengan kelas sorting_1 lakukan langkah di bawah ini
For Each code In codes
' Kolom A diisi dengan kode
sheetkiri.Cells(i, 1).Value = code.Text
' Kolom B diisi dengan nama paket
sheetkiri.Cells(i, 2).Value = code.FindElementByXPath("./..//td[2]//p[1]/a").Text
' Tambahkan variabel i agar baris yang ditulis tidak ditimpa data selanjutnya
i = i + 1
Next
' Cari tombol > (halaman berikutnya)
Set nextbutton = driver.FindElementByXPath("//li[contains(@class, 'paginate_button next')]/a")
' Klik tombol >
nextbutton.Click
Loop ' Penutup Do While
driver.Quit ' Tutup peramban
End Sub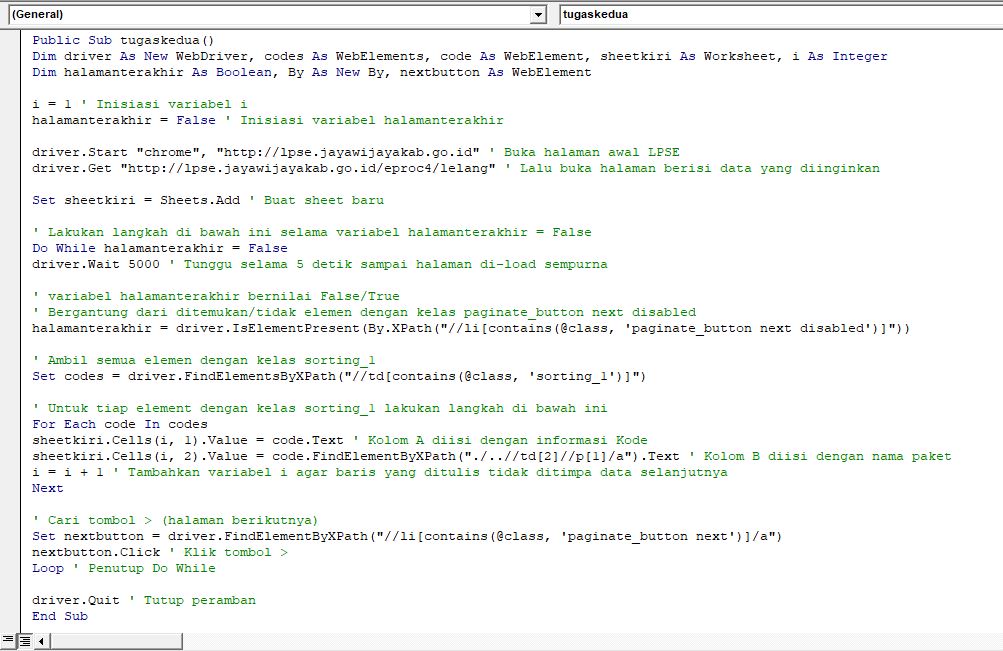
Hasil dari kode di atas, jika di Run.
Berhasil, berhasil, berhasil!
Beberapa bagian yang menarik dari kode (web) tersebut adalah.
driver.Start "chrome", "http://lpse.jayawijayakab.go.id" ' Buka halaman awal LPSE
driver.Get "http://lpse.jayawijayakab.go.id/eproc4/lelang" ' Lalu buka halaman berisi data yang diinginkanTernyata alamat (url) http://lpse.jayawijayakab.go.id/eproc4/lelang tidak dapat langsung diakses dari peramban yang baru dibuka, karena itu kita terlebih dahulu membuka http://lpse.jayawijayakab.go.id/eproc4/.
driver.Wait 5000 ' Tunggu selama 5 detik sampai halaman di-load sempurnaHalaman LPSE tersebut perlu waktu untuk me-load halaman (data diambil dengan ajax) sehingga kita perlu memerintahkan peramban untuk menunggu, dalam contoh menunggu 5 detik (5.000 milisekon).
' Kolom B diisi dengan nama paket
sheetkiri.Cells(i, 2).Value = code.FindElementByXPath("./..//td[2]//p[1]/a").TextKolom B diisi dengan Nama Paket. Menggunakan XPath kita mengakses parent dari elemen td (dengan kelas sorting_1) melalui “./..”. Kemudian dari parent tersebut diambil anak kedua “//td[2]” dan dari anak tersebut diambil cucu pertama “//p[1]”.
Bagian lain dari kode tersebut tidak terlalu menarik dan kurang lebih sama dengan kode sebelumnya.
Kita telah belajar melakukan pengambilan data dari web menggunakan VBA. Kode di atas dapat pembaca simpan sebagai Add-in, bahkan bisa ditingkatkan lagi, misal agar lebih mudah diakses dapat ditambahkan sebuah formulir. Pengguna dapat memasukkan halaman LPSE yang diinginkan, tidak terbatas pada Kabupaten Jayawijaya seperti pada contoh.
Menurut penulis bagian yang paling menyita waktu adalah identifikasi elemen apa saja yang berisi informasi yang akan diambil dan bagaimana perilaku dari sistem. Penulis butuh waktu > 3jam sampai mengetahui bahwa perlu diberi waktu tunggu (kode driver.Wait) agar elemen yang akan diambil telah siap sehingga bisa diakses.
Salam.
Cover Photo by Mika Baumeister on Unsplash
Tulisan ini tidak ada jika tanpa:
Hai Salam Kenal,
Terima kasih sekali telah membuat artikel ini, sangat menginspirasi.
Kalau boleh tertanya,
Apakah memungkinkan, ketika scaping data di lpse, jika membuka url halaman yang ingin kita scrap berdasarkan tabel excel (cara mengisikan driver.get ” ………..”), contoh
A1. http://lpse.jayawijayakab.go.id/eproc4/evaluasi/171307/pemenang
A2. http://lpse.jayawijayakab.go.id/eproc4/evaluasi/142307/pemenang
Terima kasih.
Pertama-tama, terimasih telah membaca, Pak Roi.
Sangat mungkin untuk langsung menggunakan URL dari hasil modifikasi ID Paket Pekerjaan + pola url LPSE, seperti http://lpse.jayawijayakab.go.id/eproc4/evaluasi/171307/pemenang, http://lpse.jayawijayakab.go.id/eproc4/lelang/171307/pengumumanlelang, http://lpse.jayawijayakab.go.id/eproc4/lelang/171307/peserta.
Jadi variabel url bisa disiapkan sebelumnya, tinggal dibuat dinamis dengan mengganti ID Paket.
siap..
saya mau ketawa ini.. menertawakan diri sendiri.. di waktu malam.. umur 40an jadi belajar dasar scrapy dll.. terima kasih telah menginspirasi..
Sy bergerak di bidang pembangunan perumahan, dan juga pengadaan jasa konstruksi.. n hobbyist komputer yang semuanya nanggung..
tp saya pikir banyak manfaatnya untuk kenal big data dan automation (dikit2).. sekali lagi terima kasih telah menginspirasi, semoga kita semua bisa terus belajar untuk kemajuan..
semoga bapak tertawa karena senang mendapat mainan edukatif baru hehehe, kita sama-sama sadar bahwa tidak pernah ada kata terlambat untuk belajar, bukan? saya sedang menyiapkan sebuah web khusus yang berisi data dari inaproc dan lpse seluruh indonesia, mudah-mudahan dalam waktu 1-2 bulan ini sudah bisa tayang diinternet.
nah ini… keren.. pake BINGiTS
Ide untuk scraping data lsg keluar (dengan tulisan mas Aan), so keep learning dan langsung dijalankan (disela sela waktu), sy fokus di 3 provinsi dan bbrp departemen saja. Rencana mau liat2 SIRUP.
Big data. tinggal mau di bawa kemana data itu?. Mungkin tahu kondisi real di lapangan pengadaan kita. Semoga bisa berguna.
Salam,
Saya sedang mencoba untuk mengambil setiap url dari iklan yang ada pada halaman marketplace. sekedar informasi, sekarang saya sudah benar2 pusing.
bisakah bapak membantu saya membuat code untuk bisa mengambil url yang berada di href=””
“>…
saya mau copy setiap link address yang berada di class “rl3f9 AueO0”
Sediakah bapak membantu saya?
sebelumnya terimakasih untuk artikelnya
Kode apa yang sudah dibuat? Lalu hasil apa yang diinginkan?
sebelumnya saya sudah buat code vba, tapi tanpa selenium. Namun hasilnya kurang memuaskan, Terkadang datanya belum diambil, tapi sudah loncat ke halaman berikutnya.
Saya ingin mengambil data ID akun olx dan juga nomor teleponnya. Berhubung data tersebut hanya dapat diambil ketika masuk ke link iklannya (seperti no telp yang diharuskan untuk klik tombol agar nmrnya muncul). Maka ide saya yaitu dengan cara:
1. mengumpulkan link setiap iklan yang berada dikategori tertentu
2. menyimpannya di excel
3. membuka satu-persatu setiap url yg sudah disimpan, untuk diambil id dan nomr tlp
untuk tahap 2 dan 3 saya sudah berhasil, meskipun kurang memuaskan. Masalahnya di tahap 1. Saya kesulitan menerapkan cara diatas, untuk mengambil url setiap iklan di olx.
‘<div
'
‘
‘ <a class="fhlkh" href="/item/toyota-kijang-innova- dan 'seterusnya
'
‘
‘ DLL
saya coba mengambil setiap data href yang berada di class EIR5N _1_a8d
sudah saya coba code ini
Value = code.FindElementByXPath(“./..//td[2]//p[1]/a”).Text
dengan mengubah class dan tag tapi malah error