

Web Scraping setelah Login
Setelah pengantar web scraping di tulisan pertama dan dilanjutkan dengan scraping banyak halaman penulis merasa minimal perlu satu tulisan lagi soal scrapy, bagaimana mengambil data yang hanya dapat diakses setelah melakukan login.
Yang dimaksud login di sini adalah login sederhana, memasukkan username dan password. Jika terdapat captcha maka perlu pendekatan lain, misalnya menggunakan kecerdasan buatan (mudah-mudahan kita punya kesempatan untuk membahas ini di masa depan).
Secara garis besar, setelah kita berhasil login maka server akan membuat sebuah sesi untuk kita, dalam sesi tersebut kita bisa mengakses layanan server tersebut. Agak teknis, sesi itu akan melibatkan session, cookie dan (kadang) token, namun dua yang pertamalah yang lebih banyak ditemui. Seringnya kita tidak perlu mengetahui secara akurat apa dan bagaimana terjadi, seperti saat melakukan login di browser, jika berhasil (tidak salah memasukkan username/password) maka kita dapat membuka halaman lain dalam situs tersebut, bahkan dalam tab yang berbeda. Tidak perlu memikirkan cookies disimpan dimana, lalu mekanisme sesi seperti apa.
Pola pikir itu, tidak perlu memikirkan mekanisme sesi, yang akan kita gunakan saat melakukan scraping.
Mari mulai.
Yang pertama perlu kita lakukan adalah memahami alur login yaitu halaman apa untuk mengisi username dan password, lalu jika sukses dialihkan ke halaman apa, sebaliknya jika gagal diarahkan ke halaman apa. Setelahnya baru mengakses halaman yang semula kita tuju.
Sebagai latihan kita akan melakukan scraping repository github yang telah kita beri bintang.
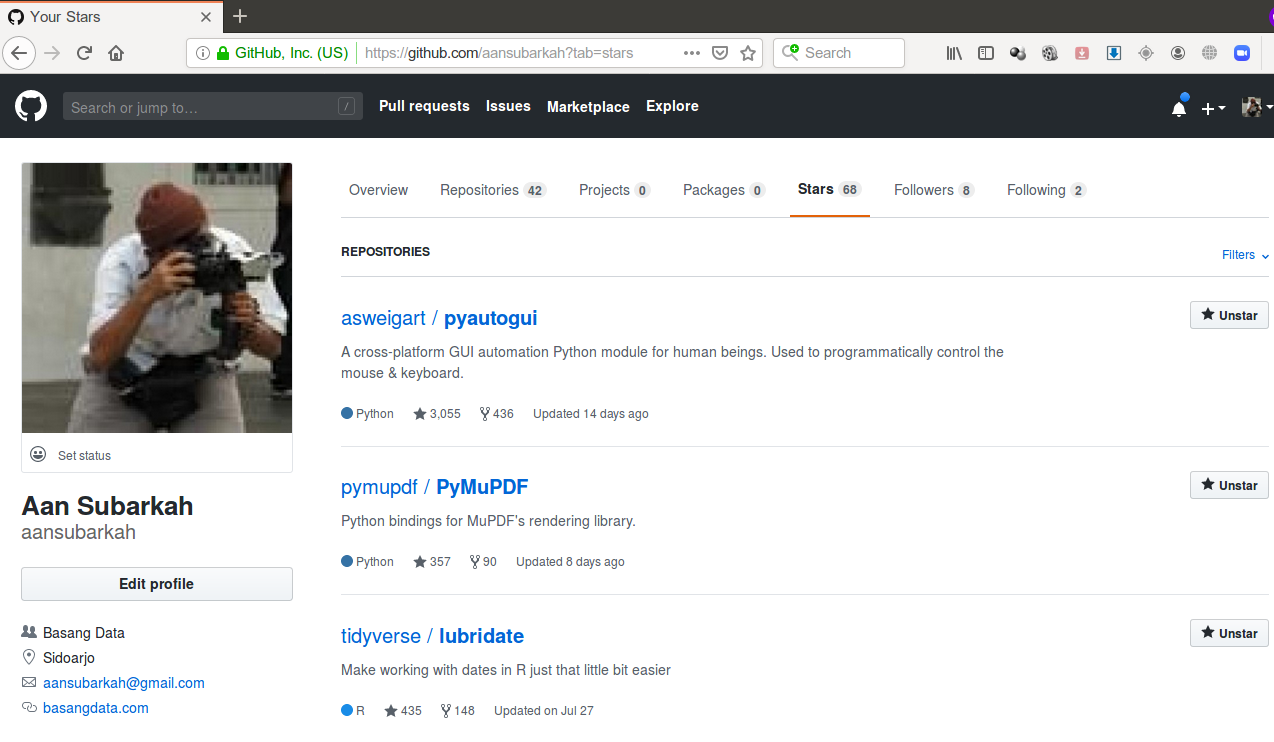
Alamat halaman di atas adalah https://github.com/username/?tab=stars, hanya dapat diakses setelah melakukan login. Dan tentu saja halaman tersebut akan menampilkan yang berbeda untuk masing-masing penduduk github.
Sebagai informasi, github adalah penyedia layanan version control untuk pengembangan perangkat lunak. Atau kadang secara sederhana dipahami sebagai tempat mengunduh kode sumber software.
Login pada github melalui tombol Sign In pada https://github.com yang lalu di-redirect ke https://github.com/login, umumnya halaman login memang ada di alamat website.com/login.
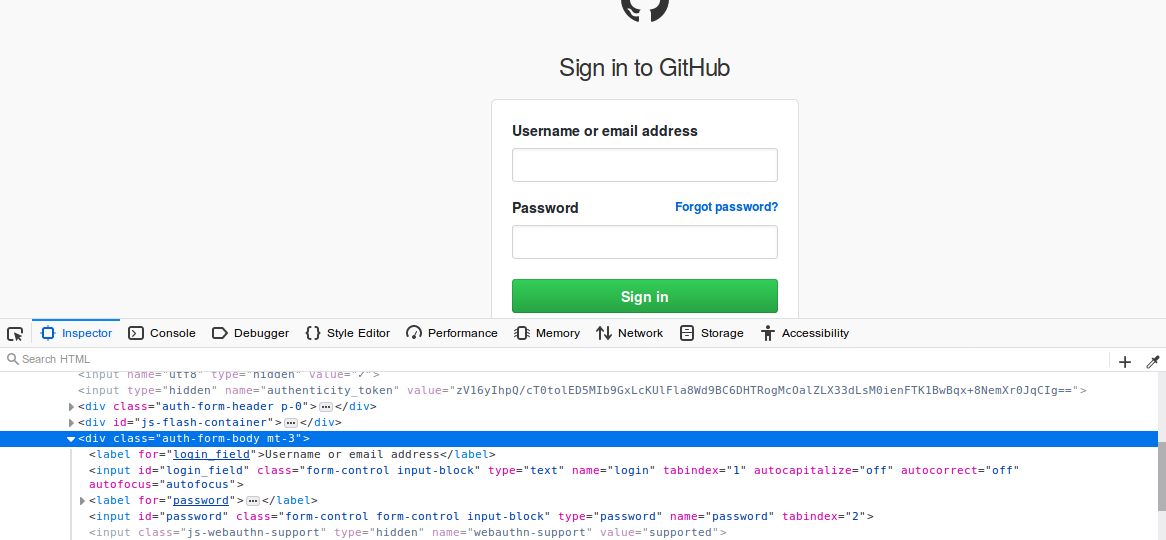
Halaman login dapat diakses langsung dari url tersebut, sehingga tugas pertama, memahami alur login, dapat dilakukan langsung dari alamat https://github.com/login.
Elemen yang perlu diisi adalah inputan di bawah label Username or email address dan Password. Klik kanan pada element tersebut lalu pilih fitur inspect element (Firefox) atau Inspect (Chrome) untuk mengetahui nama dari kedua elemen tersebut.
- login
- password
Adalah nama kedua elemen yang perlu diisi. Dua ini yang perlu kita kirimkan ke server github, untuk mengenali dan memberikan akses pada kita.
Kode selengkapnya, hanya 22 baris, untuk mengambil login dan mengambil data adalah seperti ini. Kode ini diberi nama masuk_spider.py dan disimpan dalam folder tutorialscrape/spiders.
import scrapy
class MasukSpider(scrapy.Spider):
name = "masuk"
start_urls = ['https://github.com/login']
nama = 'usernameanda'
sandi = 'passwordanda'
url_stars = 'https://github.com/usernameanda/?tab=stars'
def parse(self, response):
formdataanda = {
'login': self.nama,
'password': self.sandi
}
return scrapy.http.FormRequest.from_response(response, formdata = formdataanda, callback = self.scrape_page)
def scrape_page(self, response):
yield scrapy.Request(url = self.url_stars, callback = self.stars)
def stars(self, response):
for repo in response.xpath('//div[contains(@class, "d-inline-block mb-1")]/h3/a/text()'):
print(repo.get())
Kita bahas per-baris kode di atas. Empat baris pertama telah dijelaskan pada tulisan sebelumnya.
start_urls = ['https://github.com/login']
Adalah pengganti fungsi start_requests seperti pada tulisan sebelumnya. Fungsinya sebagai daftar alamat yang akan langsung di-scraping setelah spider dipanggil. Hasil scraping akan langsung menjadi response pada fungsi parse.
nama = 'usernameanda'
sandi = 'passwordanda'
url_stars = 'https://github.com/usernameanda/?tab=stars'
Variabel nama dan sandi silahkan disesuaikan dengan username dan password github Anda. Begitu pula dengan usernameanda pada variabel url_stars, silahkan diubah dengan username yang sebagaimana mestinya.
def parse(self, response):
formdataanda = {
'login': self.nama,
'password': self.sandi
}
return scrapy.http.FormRequest.from_response(response, formdata = formdataanda, callback = self.scrape_page)
Fungsi parse diisi terutama dengan sebuah dictionary berisi data yang diperlukan saat login. Diakhiri dengan pemanggilan fungsi from_response (bukan form) yang akan memanggil fungsi scrape_page.
def scrape_page(self, response):
yield scrapy.Request(url = self.url_stars, callback = self.stars)
Fungsi scrape_page (nama fungsi dapat dimodifikasi) mengasumsikan bahwa username dan password tidak bermasalah sehingga login berhasil tanpa kendala. Karena itu fungsi scrape_page hanya me-redirect ke halaman https://github.com/usernameanda/?tab=stars. Fungsi ini dapat diperkaya, misalnya dengan melakukan pengecekan apakah login telah berhasil yaitu dengan memeriksa apakah terdapat elemen yang hanya dapat ditemui jika login berhasil, seperti tombol Logout/Signout.
def stars(self, response):
for repo in response.xpath('//div[contains(@class, "d-inline-block mb-1")]/h3/a/text()'):
print(repo.get())
Fungsi stars, nama fungsi ini juga dapat diubah (hanya fungsi parse yang tidak dapat diubah namanya), bertugas menyelesaikan tugas utama yaitu scraping repository yang telah kita beri bintang.
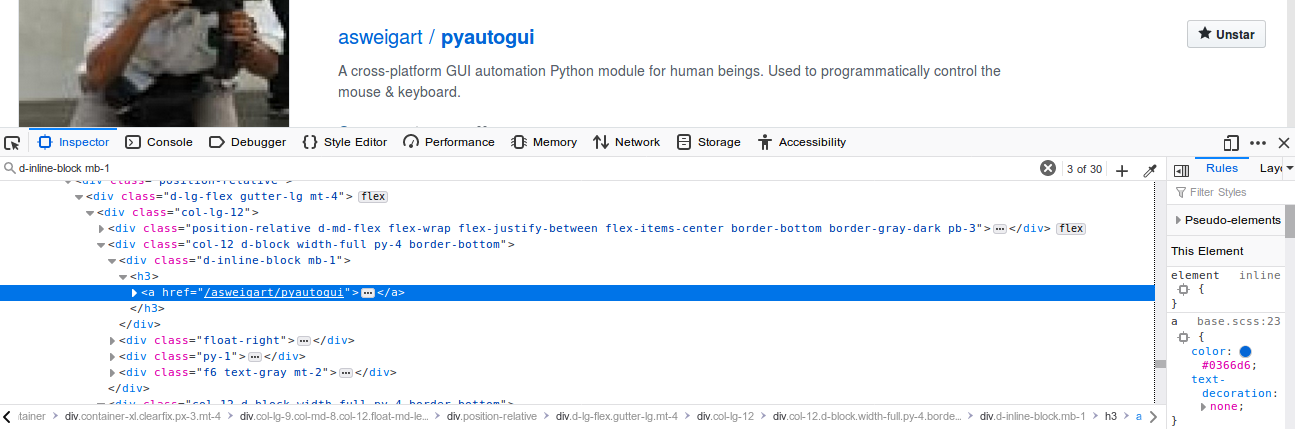
Kelas d-inline-block mb-1 adalah kelas spesifik pada elemen yang berisi data yang kita butuhkan. Hal itu dapat kita ketahui melalui proses pencarian secara manual melalui browser.
Kode di atas dieksekusi dengan perintah scrapy crawl masuk. Hasilnya seperti berikut.
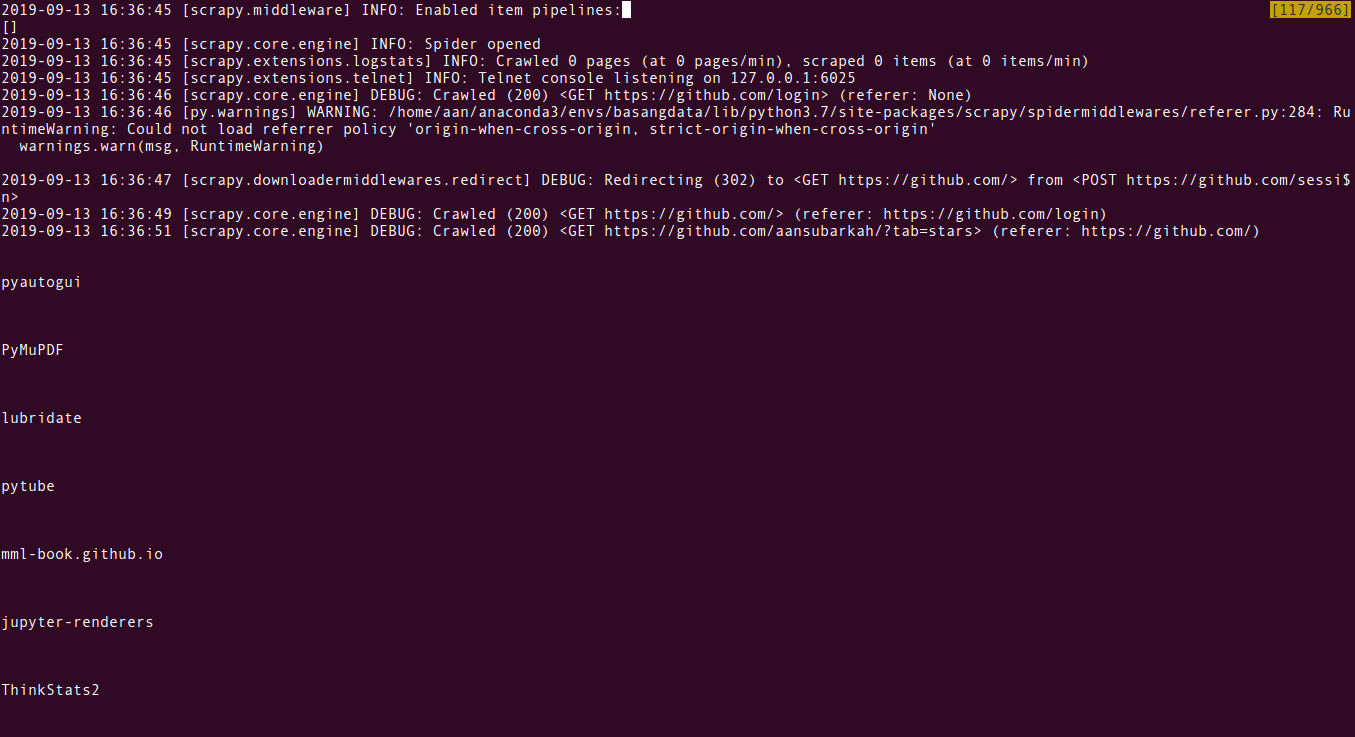
Mantul.
Pengayaan
Sejujurnya hasil mantul di atas memiliki satu kendala yang menyebabkan perintah scrapy crawl masuk tidak menampilkan data sama sekali, hanya log (catatan) scrapy.

Hal tersebut terjadi karena scrapy perlu mengunduh robots.txt sebelum crawling. Sayangnya robots.txt tidak selalu disediakan oleh situs target kita, sehingga scrapy memunculkan pesan kesalahan dan membuat kode kita tidak diproses. Solusi dari stackoverflow adalah dengan mengubah berkas settings.py pada folder tutorialscrape.
ROBOTSTXT_OBEY = True
Bagian di atas diubah nilainya dari True menjadi False seperti ini.
ROBOTSTXT_OBEY = False
Setelah menyimpan perubahan, silahkan ulangi perintah scrapy crawl masuk. Kali ini kode kita akan menghasilkan sebagaimana seharusnya.
Selain mengenai robots.txt ada hal lain sebagai pengayaan yaitu formulir login.
Pada bagian sebelumnya dituliskan mengenai tidak perlu memikirkan mekanisme, untuk kemudahan. Hal tersebut terutama didorong oleh kemajuan teknologi yang telah menangani sebagian besar pekerjaan kita sehingga kita dapat fokus pada tujuan utama alih-alih ubo rampe yang rumit, banyak dan menyita waktu.
Dalam studi kasus kita, login form hanya meminta username dan password, setidaknya hanya dua itu yang ditampilkan. Namun jika melihat elemen pada formulir login, terdapat beberapa inputan lain yang tidak ditampilkan (hidden) yaitu:
- commit
- utf8
- authenticity_token
- webauthn-support
- required_file_ac66
- timestamp
- timestamp_secret
Bersama dengan inputan tersebut dikirimkan username dan password. Hal itu dapat kita pastikan dari tab Network Monitor pada Developer Tools (Firefox atau Chrome DevTools pada, tentu saja, Chrome).
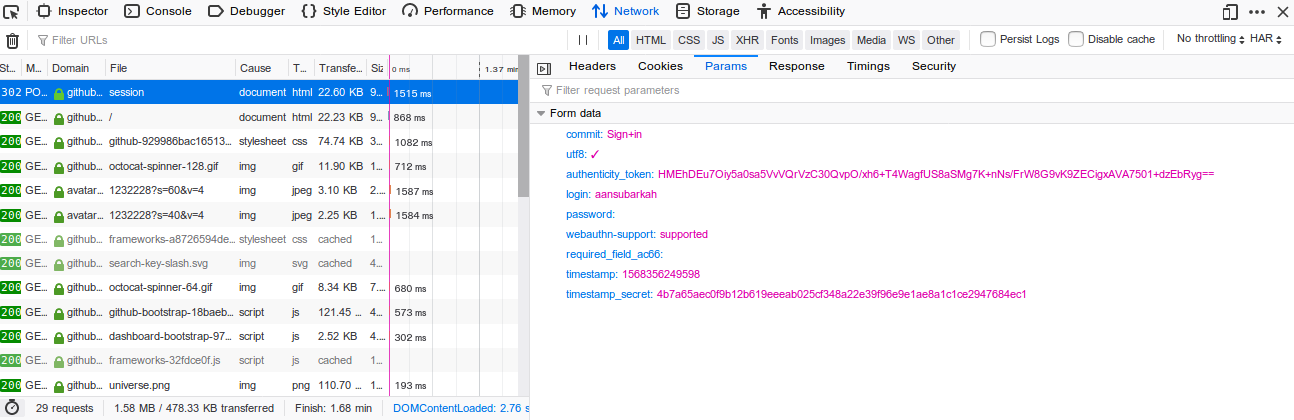
Tab tersebut memuat informasi data dan dokumen apa saja yang dikirim dan diterima oleh halaman web. Berdasar informasi tersebut kita mengetahui bahwa github tetap meminta informasi itu, meski tidak ditampilkan.
Namun kode kita tidak perlu serinci itu karena telah ditangani oleh scrapy, yang berlaku seperti sebuah browser.
Namun jika kita ingin menambahkan informasi tersebut pada kode, dapat kita gunakan kode berikut.
import scrapy
class MasukSpider(scrapy.Spider):
name = "masuk"
start_urls = ['https://github.com/login']
nama = 'usernameanda'
sandi = 'passwordanda'
url_stars = 'https://github.com/usernameanda/?tab=stars'
def parse(self, response):
utf = response.xpath('//input[contains(@name, "utf")]/@value').get()
commit = response.xpath('//input[contains(@name, "commit")]/@value').get()
authenticity_token = response.xpath('//input[contains(@name, "authenticity_token")]/@value').get()
webauthn_support = response.xpath('//input[contains(@name, "webauthn-support")]/@value').get()
required_field_ac66 = response.xpath('//input[contains(@name, "required_field_ac66")]/@value').get()
timestamp = response.xpath('//input[contains(@name, "timestamp")]/@value').get()
timestamp_secret = response.xpath('//input[contains(@name, "timestamp_secret")]/@value').get()
formdataanda = {
'login': self.nama,
'password': self.sandi,
'utf': utf,
'commit': commit,
'authenticity_token': authenticity_token,
'webauthn_support': webauthn_support,
'required_field_ac66': required_field_ac66,
'timestamp': timestamp,
'timestamp_secret': timestamp_secrete
}
return scrapy.http.FormRequest.from_response(response, formdata = formdataanda, callback = self.scrape_page)
def scrape_page(self, response):
yield scrapy.Request(url = self.url_stars, callback = self.stars)
def stars(self, response):
for repo in response.xpath('//div[contains(@class, "d-inline-block mb-1")]/h3/a/text()'):
print(repo.get())
Kode di atas hanya berbeda pada fungsi parse, yaitu terdapat beberapa variabel tambahan yang diisi dari elemen dari form login. Kemudian variabel tersebut digunakan dalam dictionary formdataanda yang dikirimkan ke server github bersama dengan username dan password.
Meski tidak diperlukan saat ini namun pengetahuan ini, membaca dan mengirimkan nilai inputan formulir yang tidak ditampilkan (hidden), dapat diaplikasikan dalam skenario lain, misal saat kita menggunakan library requests. Seseorang di halaman stackoverflow ini melaporkan tidak dapat login karena terdapat inputan yang tidak ditampilkan, dijawab secara mangkus oleh pengguna stackoverflow lain. Kemudian di halaman ini terdapat cara bagaimana menyertakan inputan hidden tersebut pada saat login.
Salam.
Assalamu’alaikum Gan…
Ada tutorial scraping pake R gak Gan?
yg butuh login ke halaman web tersebut..
terima kasih