

Web Scraping Banyak Halaman
Melanjutkan tulisan sebelumnya kita akan meningkatkan tantangan, mengambil data dari banyak halaman to infinity and beyond.
Karena basangdata minim konten dan baru ada dua halaman maka kita perlu mencari web lain dengan banyak konten berhalaman-halaman. Salah satu website yang menyediakan informasi yang menarik dan memiliki banyak halaman adalah inaproc.id yang adalah portal pengadaan (barang dan jasa) pemerintah, diampu oleh LKPP (Lembaga Kebijakan Pengadaan Barang Jasa Pemerintah).
Kita akan mengambil data rencana umum pengadaan di sini. Bagi yang belum/tidak pernah bersinggungan dengan pengadaan barang jasa pemerintah, halaman rencana umum pengadaan (rup) menyediakan informasi rencana pengadaan (pembelian) barang yang akan dilakukan oleh institusi pemerintah. Berdasar informasi tersebut penyedia jasa akan mengajukan penawaran kepada institusi pemerintah itu.
Jadi jika kita berhasil mengambil semua data dari situs itu maka sebenarnya banyak penyedia jasa yang tertarik dengan data yang kita punya.
Setelah menetapkan target langkah selanjutnya adalah mempelajari perpindahan halaman. Sejauh pengetahuan penulis terdapat dua jenis, yang dapat diamati dari url (alamat web) apakah berubah atau tidak.
- Jika url berubah artinya halaman yang kita hadapi adalah halaman baru, scrapy dapat langsung mengakses halaman itu melalui url.
- Url tidak berubah namun tampilan berubah. Web tersebut menggunakan ajax atau merupakan Single-page-application (SPA). Meski ‘tidak terlihat’ namun halaman web tetap mengakses url lain. Untuk dapat melihat url yang diakses kita dapat menggunakan tab Network pada Inspector Element. Jaman now umumnya kita menemukan web dengan metode ini, untungnya adalah url yang diakses tersebut sebenarnya hanya mengambil sedikit data mentah yang telah terformat baik, misal json, bukan dalam format html yang semrawut.
Kembali ke web rup, kita dapat melihat bagaimana perpindahan halaman dengan mencoba klik tombol Berikutnya di bagian bawah.
Ternyata url berubah dari http://inaproc.id/rup menjadi http://inaproc.id/rup?page=2. Dengan tahu ini kita dapat menentukan url yang akan diambil datanya adalah page 1 sampai dengan halaman ke n. Berapakah nilai n? Pada bagian atas halaman terdapat teks menampilkan 1-10 dari total 6052607.
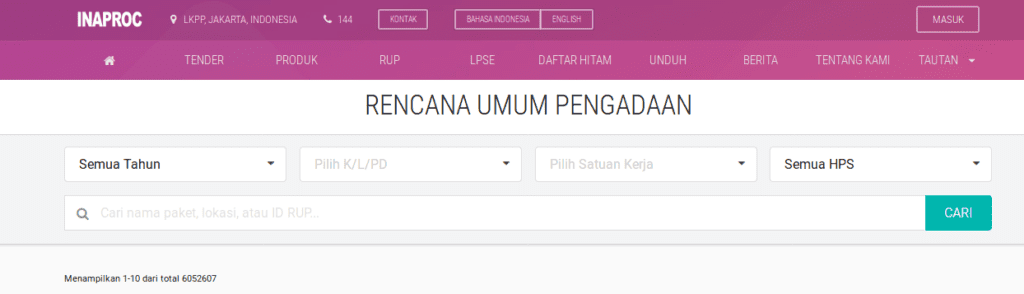
Tiap halaman menampilkan 10 data dan terdapat 6.052.607 sehingga terdapat 605.261 (605.260,7) halaman, alias n = 605.261. Kita dapat menguji apakah itu adalah halaman terakhir dengan mengetikkan url http://inaproc.id/rup?page=605261.
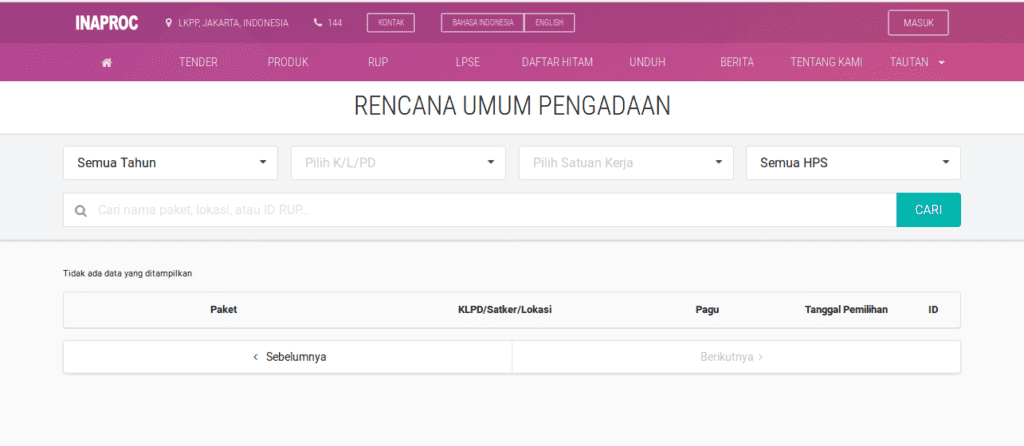
Dan, gagal!
Setelah mencoba beberapa halaman ternyata maksimal halaman yang bisa diambil adalah 1000 (http://inaproc.id/rup?page=1000).
Jika menekan tombol Berikutnya pada halaman tersebut maka halaman selanjutnya (1001) akan menampilkan halaman tanpa data, seperti pada halaman 605261 di atas.
Kadang kondisi dunia nyata memang kedjam. Ok beqlah. Kita ambil saja 10.000 data itu. Jadi kita akan mengambil data dari halaman 1 sampai dengan 1000.
Selanjutnya kita perlu mempelajari elemen web yang memuat data yang kita perlukan. Dalam kasus inaproc, web akan menampilkan pop up window jika nama kegiatan (berwarna merah) diklik.
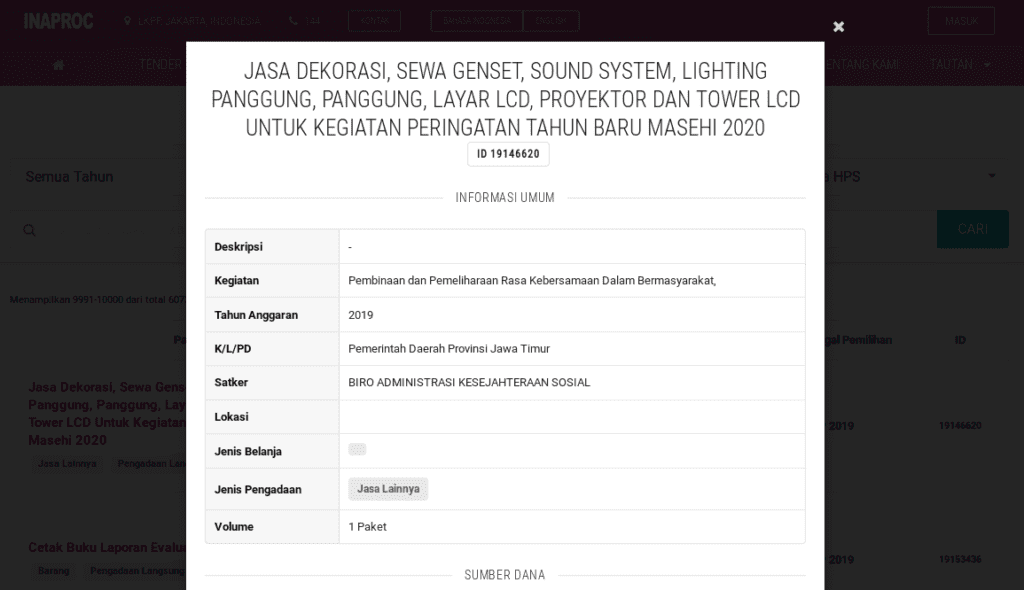
Sebagai informasi, pop up window tersebut sudah ada dalam halaman web namun disembunyikan (hidden) sampai nama kegiatan dipilih. Karena itu kita hanya perlu mencari elemen yang disembunyikan tersebut. Pilih sembarang area dalam pop up window, klik kanan lalu pilih Inspect Element/Inspect. Lalu klik segitiga yang menghadap ke bawah untuk menampilkan elemen pop up. Kita akan mendapatkan sejumlah elemen div dengan id diawali kata modal-. Dalam elemen tersebutlah tersimpan semua informasi yang akan kita ambil.
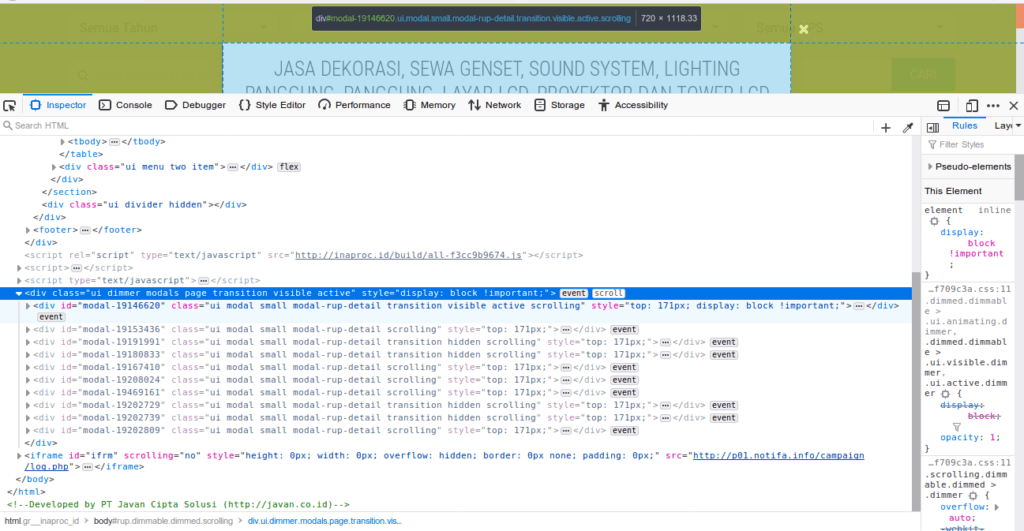
Dari banyak elemen modal di atas, hanya yang paling atas yang terang, hal itu menunjukan jika elemen tersebut sedang aktif (ditampilkan). Elemen lainnya berwarna abu-abu karena tidak aktif.
Kita akan mengambil contoh data yang terdapat dalam pop up window tersebut yaitu Kegiatan dan Sumber Dana.
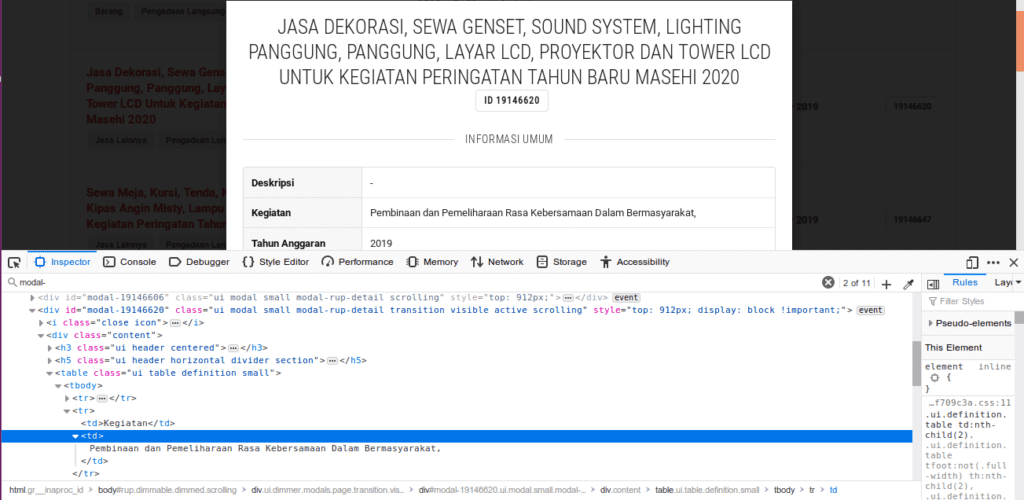
Elemen yang berisi informasi kegiatan ada di div (id = modal) -> div (class = content) -> table (pertama) -> tbody -> tr (kedua) -> td (kedua).
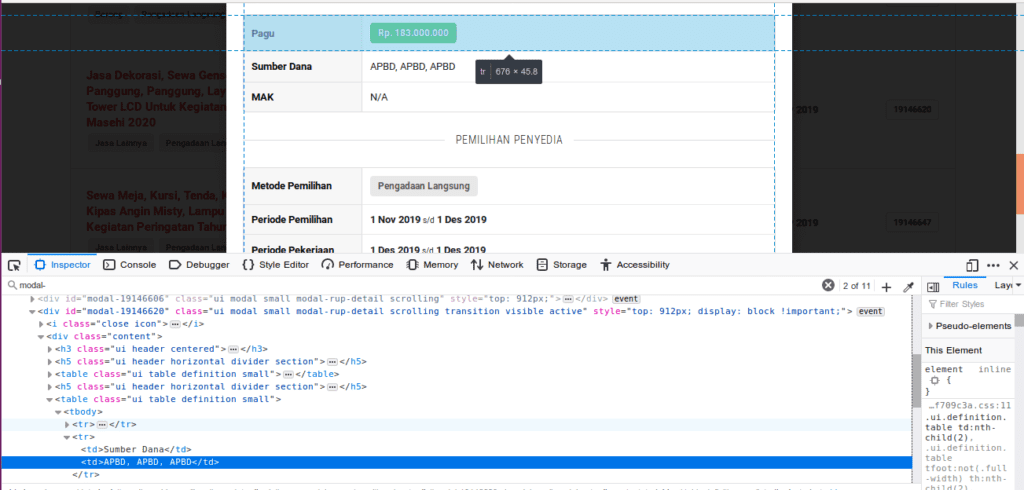
Sedang elemen sumber dana adalah div (id = modal) -> div (class = content) -> table (kedua) -> tbody -> tr (kedua) -> td (kedua).
Kita sudah tahu bagaimana mengakses halaman 1 sampai 1000, kita sudah tahu elemen apa saja yang akan diambil, sekarang kita bisa mulai menulis spider.
Kita beri nama inaproc_spider.py yang disimpan pada folder tutorialscrape/spiders (melanjutkan project sebelumnya). Sebagai bahan latihan, kita gunakan script sederhana.
import scrapy
class InaprocSpider(scrapy.Spider):
name = "inaproc"
def start_requests(self):
urlInaproc = "http://inaproc.id/rup?page="
for i in range(1, 1001):
newUrl = urlInaproc + str(i)
yield scrapy.Request(url = newUrl, callback = self.parse)
def parse(self, response):
print(response.body)
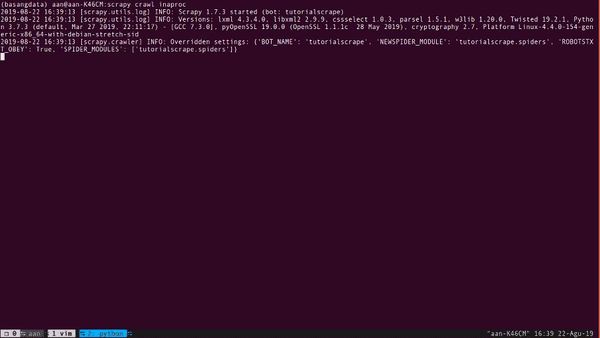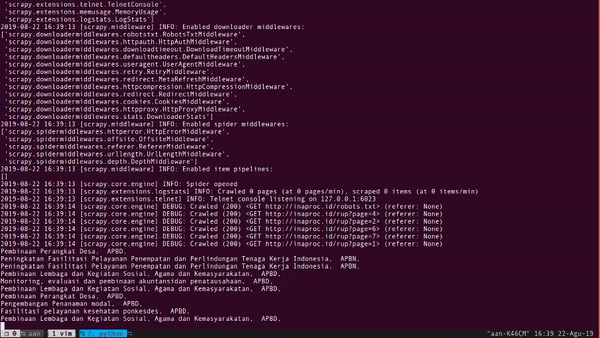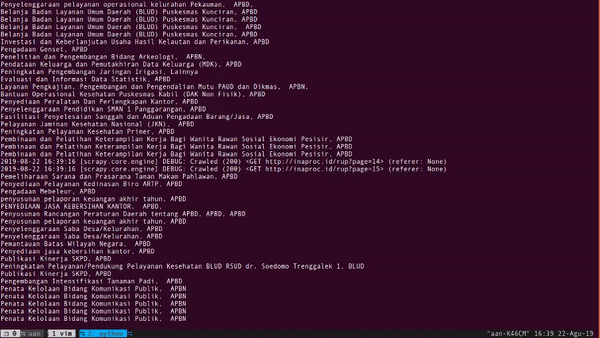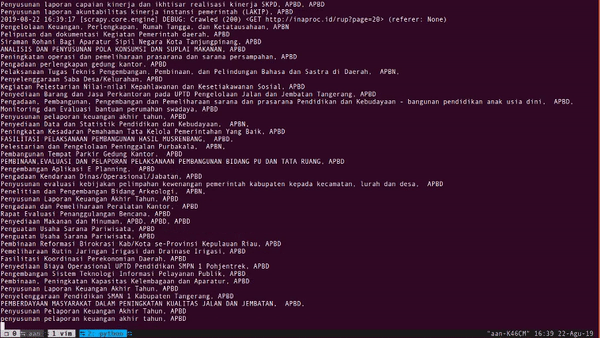
Kemudian eksekusi dengan perintah scrapy crawl inaproc, namun, seperti biasa, pastikan kita telah berada dalam folder tutorialscrape.

Layar akan menampilkan tag-tag html halaman 1 sampai 1000. Pada gambar di atas hanya ditampilkan saat scrapy meng-crawl beberapa halaman saja.
Kita rapikan layar dengan script yang khusus mengambil dua informasi yang kita butuhkan.
import scrapy
class InaprocSpider(scrapy.Spider):
name = "inaproc"
def start_requests(self):
urlInaproc = "http://inaproc.id/rup?page="
for i in range(1, 1001):
newUrl = urlInaproc + str(i)
yield scrapy.Request(url = newUrl, callback = self.parse)
def parse(self, response):
for modal in response.xpath('//div[contains(@id, "modal-")]/div'):
kegiatan = modal.xpath('.//tr[td/text() = "Kegiatan"]/td[2]/text()').get()
sumber = modal.xpath('.//tr[td/text() = "Sumber Dana"]/td[2]/text()').get()
print(kegiatan, sumber)
Hurray!
Cukup 13 baris kode kita sudah mendapatkan 10.000 data. Kita bahas kode di atas.
import scrapy
class InaprocSpider(scrapy.Spider):
name = "inaproc"
Kode standar dalam spider scrapy, pertama import scrapy lalu buat sebuah kelas yang bernama sama dengan nama file. Pada baris ketiga isi variable name dengan nama yang sama dengan nama file.
def start_requests(self):
urlInaproc = "http://inaproc.id/rup?page="
for i in range(1, 1001):
newUrl = urlInaproc + str(i)
yield scrapy.Request(url = newUrl, callback = self.parse)
start_requests adalah fungsi yang harus ada dalam spider scrapy. Dalam fungsi tersebut pertama-tama kita buat sebuah variabel berisi url web tujuan, namun url ini belum lengkap karena belum berisi no halaman. Pada bagian selanjutnya kita membuat sebuah perulangan dari angka 1 sampai 1000, url ditambahkan angka tersebut sehingga menjadi http://inaproc.id/rup?page=1 lalu http://inaproc.id/rup?page=2 dan seterusnya. Baris terakhir adalah scrapy mengakses tiap halaman tersebut (url = newUrl) kemudian hasilnya diproses fungsi lain (callback = self.parse).
def parse(self, response):
for modal in response.xpath('//div[contains(@id, "modal-")]/div'):
kegiatan = modal.xpath('.//tr[td/text() = "Kegiatan"]/td[2]/text()').get()
sumber = modal.xpath('.//tr[td/text() = "Sumber Dana"]/td[2]/text()').get()
print(kegiatan, sumber)
Fungsi parse dimulai dengan mengambil semua pop up window dalam halaman yang sedang dibuka. Dari variabel response yang dikirimkan oleh fungsi sebelumnya (start_requests), digunakan xpath untuk mendapatkan semua elemen div yang idmodal-. Di bagian akhir xpath itu (//div[contains(@id, “modal-“)]/div) terdapat div dengan satu garis miring sebelumnya, hal ini menunjukkan bahwa variabel modal berisi semua elemen dalam div dengan kelas content (div (id = modal) -> div (class = content)).
Sebagai catatan, dalam xpath, dua garis miring (//) berarti banyak (semua) elemen sedangkan satu garis miring berarti hanya satu elemen anak dari elemen yang disebutkan sebelumnya. Karena itu penting untuk sebelumnya mempelajari hirarki elemen dan bagaimana menggunakan xpath.
Variabel kegiatan dan sumber berisi teks yang ada dalam elemen di samping kata Kegiatan dan Sumber Dana. Sekali lagi, silahkan mengacu pada dokumentasi xpath seperti w3schools atau dari scrapy sendiri agar tahu apa fungsi titik sebelum dua garis miring atau text(). Penulis sendiri tidak menghapal dan/atau paham benar penggunaan kombinasi xpath tersebut, trial and error sejauh ini efektif menyelesaikan persoalan yang dihadapi. Keyword paling sering penulis gunakan di mesin pencari adalah xpath how to get …, titik-titik diisi dengan kebutuhan, misalnya sibling.
Baris terakhir hanya menampilkan saja data yang telah diambil dari masing-masing pop up window. Jika ingin menyimpan dalam file csv seperti pada tulisan sebelumnya, dapat digunakan kode berikut.
def parse(self, response):
newCsv = open('inaprocdata.csv', 'a')
for modal in response.xpath('//div[contains(@id, "modal-")]/div'):
kegiatan = modal.xpath('.//tr[td/text() = "Kegiatan"]/td[2]/text()').get()
sumber = modal.xpath('.//tr[td/text() = "Sumber Dana"]/td[2]/text()').get()
print(kegiatan, sumber)
if kegiatan: kegiatan = kegiatan
else: kegiatan = ""
if sumber: sumber = sumber
else: sumber = ""
newCsv.write(kegiatan + ";" + sumber + "\n")
newCsv.close()
Data akan disimpan dalam file inaprocdata.csv yang ditempatkan di folder tutorialscrape. Dua if digunakan untuk memastikan variabel kegiatan dan sumber diisi teks kosong, jika tidak demikian Python akan memprotes karena variabel kosong ditambahkan dengan variabel teks. Oya, meski bernama csv (comma separated value) namun sebagai pemisah antar nilai kita dapat menggunakan karakter lain, misal semikolon seperti pada file inaprocdata.csv kita. Hal itu untuk mengantisipasi data yang berisi karakter koma.
Mantul!
Kita sudah berhasil mengambil data dari banyak halaman, sebagai ringkasan, langkah Web Scraping adalah:
- Tentukan target
- Pelajari bagaimana website berpindah halaman
- Pelajari elemen yang memuat data yang akan diambil
- Buat spider
- Eksekusi scrapy
- Evaluasi hasil, jika sesuai ulangi #5 jika tidak ulangi #4 atau bahkan #2
Selain itu, agar mudah di langkah #3 kita perlu memperhatikan hirarki elemen dan bagaimana menggunakan xpath.
Salam.
Cover Photo by Negative Space from Pexels
2 Replies to “Web Scraping Banyak Halaman”